
1. Principles of Reliable Data Transfer
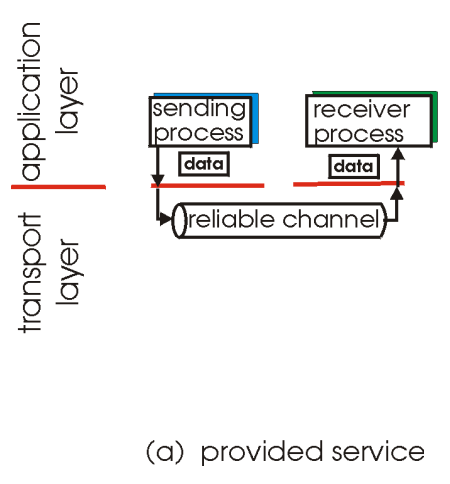
트랜스포트의 TCP 프로토콜이 제공해주는 reliable한 data transfer가 어떻게 이루어지는지 알아보겠습니다. 여기서 말하는 reliable은 애플리케이션에서 내려온 메시지가 하나도 유실되지 않고 에러 없이 전달되는 것을 의미합니다.
그런데 이게 애플리케이션 프로세스들한테 뭔가 reliable한 채널이 있는 것처럼 뭔가 환상을 주지만, 실제적으로 보면 이 트랜스포트는 아래 계층들을 통해서 메시지가 나가는 것 입니다.
그래서 라우터를 거쳐서 가는데, 실제적인 이 언더 라인 네트워크는 unreliable 합니다. 왜냐하면 이곳은 여러가지 경우의 수가 일어나는 환경 이기 때문입니다. 예를 들어 어떤 라우터에 큐가 꽉 차 있으면, 패킷이 드랍 돼서 로스가 발생하고, 패키지 유실이 발생하고. 어떤 케이블이 좀 이상하면 거기에 에러가 발생합니다.

트랜스포트 레이어 서비스가 reliable한 서비스 데이터 통신을 제공하는 것 같지만, 사실은 이런 환경에서 우리한테 어떤 환상을 주는 것 입니다. 백조가 잘 떠 있는 것 같지만, 발을 엄청 구르는 것과 동일한 셈입니다.
이 실제 환경은 reliable 하지 않습니다. 그러면 unreliable한 환경은 두 가지 경우를 지칭합니다. 패킷이 유실되거나 혹은 패킷의 에러가 발생하거나. 그러니까 결국 이 unreliable한 현실적인 이 채널에서, 네트워크에서 발생하는 상황은 패킷 에러 혹은 패킷 로스입니다. 패킷이 없어지거나 아니면 패킷에 에러가 발생하거나. 이 두 가지 사항만 잘 처리를 하면 reliable하게 만들 수 있게 됩니다.
2. Let's Build simple Reliable Data Transfer Protocol
- What can happen over unreliable channel?
- Message (packet) error
- Message (packet) loss
TCP에서 필요한 이 reliable한 데이터 transfer를 제공하기 위한 원리를 알아보겠습니다.
We'll:
Incrementally develop sender, receiver sides of reliable data transfer protocol (rdt)
Consider only stop-and-wait protocol
Use finite state machines (FSM) to specify sender, receiver
reliable data transfer protocol을 디자인 해보겠습니다. 이 프로토콜은 단순해서, 한 번에 패킷 하나씩만 보냅니다. 즉, 패킷을 하나 보내고, receiver가 받았는지 100% 확인하면, 다음 패킷 보내는 식으로 신뢰성을 주겠습니다.
3. rdt1.0: Data Transfer over a Perfect Channel
- Underlying channel is perfectly reliable
- No packet errors
- No packet loss
- What mechanisms do we need for reliable transfer?
- Nothing! Underlying channel is reliable!
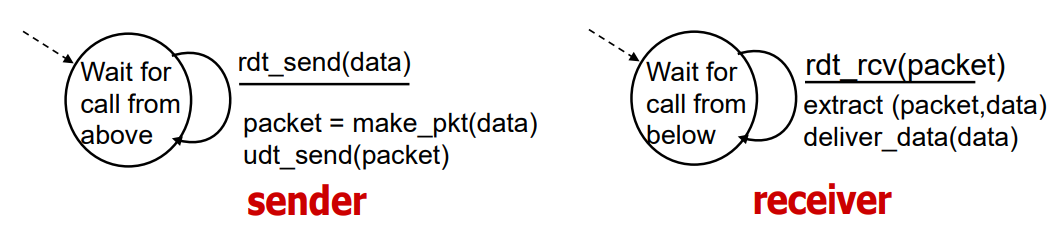
단순한 상황을 가정하고, 점진적으로 프로토콜을 개선시켜 보겠습니다. 우선 rdt 프로토콜 버전 1.0인 단순한 상황에서 어떻게 동작하는지 보겠습니다. 만약에 이 언더 라인이 네트워크 채널이 완벽하게 reliable 하다면 에러는 발생하지 않을 것 입니다.
에러도 없고 유실도 없고 완벽하면 할 일 없습니다. 그냥 보내면 다 가기 때문입니다. sender는 그냥 메시지가 위에서 오면, 패킷으로 만들어서 보내고, 보내는 것은 잘 도착해서 받는 서버/클라이언트는 오는 것을 위로 올리게 됩니다.
4. rdt2.0: Channel with Bit Errors (no loss!)
What mechanisms do we need to deal with error?
Error detection
• Add checksum bits
Feedback
• Acknowledgements (ACKs): receiver explicitly tells sender that packet received correctly
• Negative acknowledgements (NAKs): receiver explicitly tells sender that packet had errorsRetransmission
• Sender retransmits packet on receipt of NAK
So, we need the following mechanisms:
- Error detection, Feedback (ACK/NACK), Retransmission

위의 상황에서 현실적인 상황을 하나씩 추가하겠습니다. 만약에 이 언더라인 채널이 패킷 에러가 발생 가능한 채널이면, 에러가 났는지 안 났는지 판단이 필요합니다. 즉, Error dection을 위해서 보내는 패킷에 Checksum이라는 어떤 부가적인 정보를 붙여 헤더에 담아서 보내게 됩니다. Checksum은 실제 패킷에 담긴 메시지에 에러가 있는지 없는지 판단하게 만들어주는 어떤 장치입니다.
그럼 receiver 측에서 패킷을 받았는데 패킷 에러는 경우에 error dection 메커니즘인 checksum을 통해서 알았으면 다시 보내달라고 요청을 한다든지 잘 받았는지, 못 받았는지 피드백을 지속적으로 줘야합니다. 예를 들면 잘 받았다 그러면 “나 잘 받았어.”라고 하는 이 Acknowledgement 메시지를 줘야 하고, 받아왔는데 에러가 있어서 “나 잘 못 받았다.” 그러면 negative 피드백을 줘야합니다.
즉, 패킷을 받을 때마다 피드백을 줘야 negative 또는 positive든 상대가 알게 됩니다. 에러가 있는 상황에서 신뢰성 있는 의사소통은 일상생활에서도 하는 것 입니다. 전화 통화할 때 전화 회선 에러 발생이 가능합니다. 그런데 우리는 서로 메시지 교환할 수 있습니다. 이게 지금 에러가 있는 상황에서 우리가 신뢰성 있는 의사소통을 하고 있는 개념입니다.
전화 통화할 때 우리는 알게 모르게 계속 positive든 negative든 피드백을 계속 주고 있습니다. 긍정적인 피드백을 받으면 계속 얘기하는 거고, “뭐라고?” 이런 부정적인 피드백을 주면 상대방은 그 전에 했던 말을 반복하게 됩니다.
Sender가 negative acknowledgement 즉 NAK을 받게 되면 어떻게 해 우리는 방금 했던 말을 다시 하게 됩니다 그래서 생각해 보면 우리 일상생활에서 하고 있던 겁니다. 에러가 있는 상황에서 필요한 메커니즘은 바로 error detection, feedback 이후에 재전송(retransmission)을 합니다.
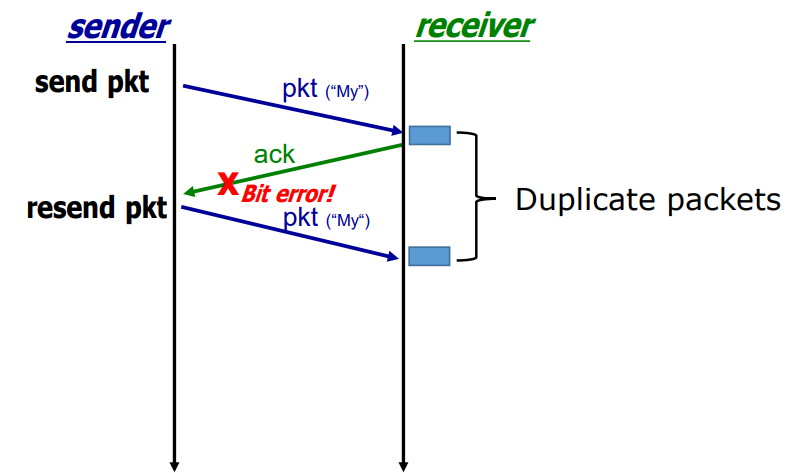
Handling Duplicate Packets
Sender adds sequence number to each packet
Sender retransmits current packet if ACK/NAK garbled
Receiver discards duplicate packet
에러가 있을 경우에 area detection을 해서 피드백을 주고 재전송 하는 동작은 에러가 발생하는 언더라인 채널에서 모든 상황을 커버하지는 않습니다. 완벽하게 신뢰성 있는 메시지 교환을 하기 위해서는 무엇인가 더 필요합니다.
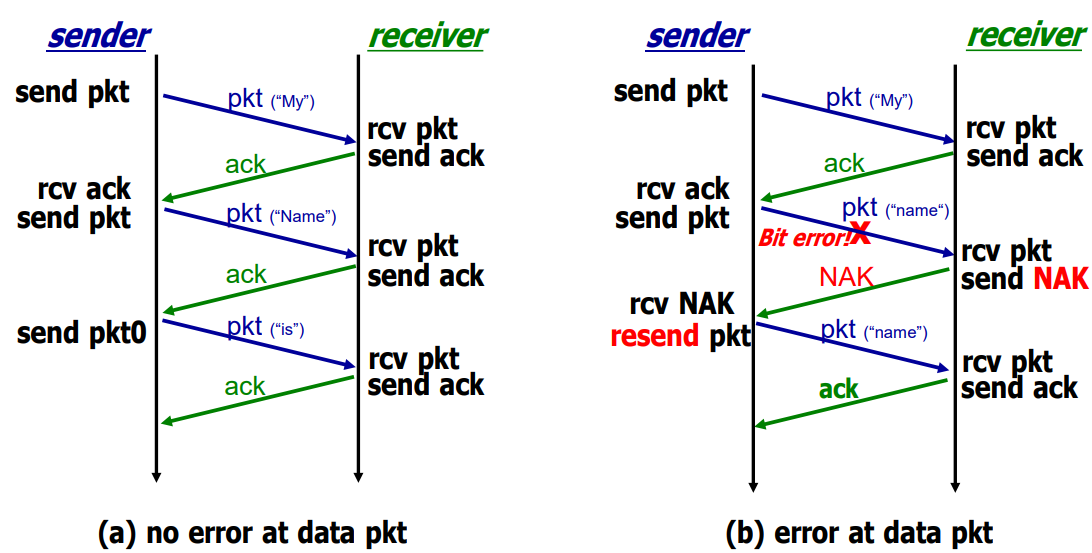
만약에 피드백에 에러가 있는 경우에 처리가 확실하지 않습니다. 위의 그림에서 왼쪽이 sender고, 오른쪽이 receiver 이고, 세로 직선은 시간 축입니다. Sender가 패킷을 보내고서 잘 받았으면 receiver는 패킷을 받고 제일 처음에 해야 될 일이 Error dection 입니다. Error dection 해봤더니 문제가 없어서 잘 받았으면 receiver는 피드백으로 ACK를 줘야합니다. 만약에 이 ACK가 가다가 에러가 생기면, sender는 딱 받았을 때 이게 ACK인지 NAK인지 알 수 없습니다.
그러니까 이 피드백 자체가 에러인지 아닌지는 데이터 패킷 뿐만 아니라, 이 피드백 패킷에도 checksum이 있어야 합니다. 그러니까 가는 거에도 checksum이 있어야 되고, 오는 거에도 다 checksum이 있어야 됩니다. 그래야 중간에 에러가 있었는지 없는지 알게 됩니다. 근데 피드백을 받았는데 checksum을 보니까 에러이면 sender 입장에서는 지금 receiver가 ACK를 보냈는지 NAK를 보냈는지 판단이 안 되게 됩니다. 받았다고 가정하고 넘어가면 너무 무책임 하게 됩니다. 그러니까 안 받았다고 가정하고, 다시 보내는 것은 임시적인 해결책 입니다.

그러면 receiver가 안 받았을 수도 있으니까 다시 보내면, 이걸 receiver 입장에서 봤을 때는, 이미 받았고 그 다음에 다시 무엇인가 왔는데, 이게 중복된 패킷인지 아니면 새로운 패킷인지 알 길이 없습니다.
예를 들어 sender가 지금 암호 같은 걸 보낸다고 가정하면 패킷 에러로 인해 재전송된 이 패킷이 새롭게 온것인지 아니면 중복되서 버려야 하는지 알 수 없습니다. 즉, sender 입장에서 피드백이 에러가 생기면 재전송하면 됩니다. 그런데 receiver 입장에서는 이게 중복된 건지, 아니면 이게 새로운 메시지인지 알 길이 없습니다.
그래서 구별을 할 필요가 있습니다. 그래서 패킷에 번호 붙이게 됩니다. 그래서 등장하는 게 시퀀스 넘버라는 입니다. 구분하라고 패킷에다가 번호를 붙이기 시작하는 것 입니다. 0부터 시작해서 0, 1, 2, 3, 4 쭉 붙여놓으면 구분이 될 것 입니다. 그러니까 중복된 경우에는 같은 번호가 올 것 이고, 그것으로 중복된 것을 판단하게 됩니다.
그래서 이 피드백에도 에러가 발생할 수 있기 때문에, 우리가 여기 시퀀스 넘버를 모든 패킷에 붙여야 합니다. 그 다음에 sender는 피드백을 받았을 때 피드백이 에러가 있을 경우는 지금 어떤 상황인지 감이 안 잡히기 때문에, 무조건 재전송 합니다. 재전송 해도 문제가 안 되는 게 receiver도 시퀀스 넘버를 트래킹하고 있기 때문에 중복된 패킷은 알아서 버려도 괜찮은 겁니다.
