
1. IP Fragmentation & Reassembly 개념

각 링크별로 링크가 한꺼번에 한 번에 보낼 수 있는 그 데이터 유닛의 맥시멈 사이즈가 정해져 있습니다. 그걸 우리가 MTU, maximum transfer unit이라고 불리는데 이 MTU는 링크 레이어 기술마다 다 다릅니다. 예를 들어 인터넷, 와이파이, 3g 아니면 옵틱, 광 케이블 이런 애들이 다 링크이고 MTU가 다 다릅니다.
MTU의 예를 들면 4000바이트짜리 패킷을 sender가 보냈는데, 특정 링크에서 처리할 수 있는 maximum transfer unit이 예를 들면 1500 바이트라면 보내지지 않습니다. 문제 해결을 위해 현재 인터넷 버전 IPv4에서는 처리할 수 있는 MTU보다 더 큰 사이즈의 패킷이 들어오게 되면 거기서 바로 분리합니다.
MTU 사이즈에 맞는 독립적인 사이즈의 프레임으로 바뀌어서 진행이 됩니다. 그래서 얘네들은 각자 이제 서로 다른 패킷이 되고 마지막에 합체해서 다시 원래 패킷으로 돌아옵니다. 이런 fragmentation, assembly 작업을 위해서 필요한 것들이 ID, flag, offset 입니다.
Network links have MTU(max.transfer size) -largest possible link-level frame
(각 링크별로 링크가 한꺼번에 한 번에 보낼 수 있는 그 데이터 유닛의 맥시멈 사이즈)
• different link types, different MTUs (MTU는 링크 레이어 기술마다 다 다름.)
Large IP datagram divided(“fragmented”) within net
• One datagram becomes several datagrams
(MTU보다 더 큰 사이즈의 패킷이 들어오게 되면 거기서 바로 분리합니다.)
• “Reassembled” only at final destination
(각자 이제 서로 다른 패킷이 되고 마지막에 합체해서 다시 원래 패킷으로 돌아옵니다.)
• IP header bits used to identify, order related fragments
(fragmentation, assembly 작업을 위해서 필요한 것들이 ID, flag, offset 입니다.)

Sender가 IP 패킷을 생성해서 헤더가 있고 데이터가 있습니다. 위 그림은 헤더 필드 중에 하나가 4000 바이트짜리인 패킷 length 입니다. ID는 패킷별로 안겹치게 sender가 정하게 됩니다.
이 패킷이 사이즈는 4000, ID는 x이고 숫자 입니다. 그리고 이 flag는 첫번째 fragment 뒤로 추가 fragment 오는지 의미합니다. flag가 처음 만들어졌을 때는 fragment가 안 된 거니까 0 입니다. 그리고 마지막 fragement는 fragment가 끝난 것 이니까 0 입니다.
예를 들어 이 4천 바이트짜리 패킷이 MTU 1500인 링크를 만났다고 가정하겠습니다. 이 4000 바이트는 헤더와 데이터를 포함한 전체를 의미 합니다. 헤더 크기가 20바이트 입니다. 그러면 실제적으로 데이터는 3980바이트 이므로 링크의 MTU 1500 보다 크므로 나눠져야 합니다.
그리고 offset은 만약에 fragment 된 경우에 첫 번째 시작 부분이 전체 패킷에서 어느 정도의 위치를 차지하는지를 나타냅니다. 즉, offset은 두번째 fragement는 원래 기존의 데이터에서 잘려져서 시작할 것 인데 잘린 부분이 어디인지를 의미합니다. 아래의 그림에서 추가설명을 하겠습니다.
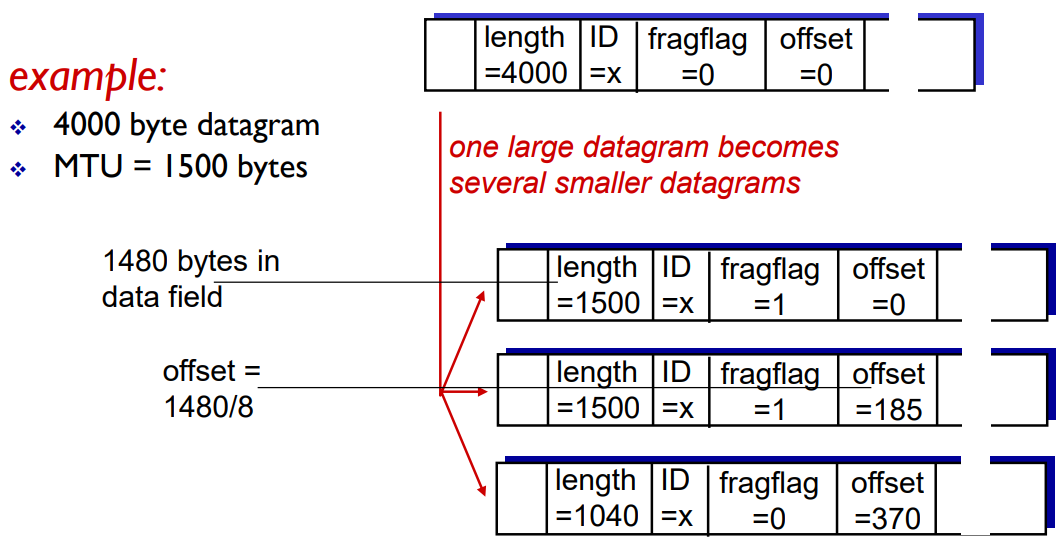
첫 번째 fragment 보면, length는 1500으로 MTU 사이즈에 맞게 첫 번째가 나오고 ID는 x 입니다. flag는 1로 바뀝니다. 내 뒤에 fragment 된 게 있다는 것 입니다. 그리고 나의 offset은 나는 제일 앞이니까 0이 됩니다.
그리고 두번 째 fragment가 또 다른 패킷으로 딱 변하고, length: 1500, ID = x, flag = 1 입니다. offset은 원래 데이터 사이즈는 3980 바이트 였는데, 쪼개가지고 첫 번째 fragment에 1480바이트 들어갔습니다. 다음 fragment도 1480 바이트 들어갔죠. 그러니까 1480을 적으면 되는데, 필드 비트 수 줄이기 위해 8을 나눠서 적어줍니다. 그래서 3비트가 줄게 됩니다.
Fragment의 이러한 정보로 나중에 병합이 가능합니다. 그러니까 이게 어떤 방식으로 분리를 했는지 기록해놓는 것 입니다. 추가로 만약에 분리돼서 독립적인 패킷이 되서 가는데 중간에 하나가 없어지면 reassembly(재결합)이 안됩니다. 예를 들면 첫 번째랑 세 번째는 갔는데 두 번째가 사라진 경우 입니다. reassembly(재결합)가 안 되면 패킷이 완성이 안 됐으니까, 위로 못 올립니다. 그런데 reassembly가 안 되니까, 없는 패킷이 됩니다. 그래서 나중에 TCP에서 타이머 터지고, 위에서 알아서 재전송을 합니다.
2. IPv6
Why IPv6?
• IPv4 will be exhausted!! (IPv4가 고갈날 까봐 생김.)
• 2^32 space = 4 billion IP Address
3. NAT: Network Address Translation
(IPv4 고갈 안나는 이유)
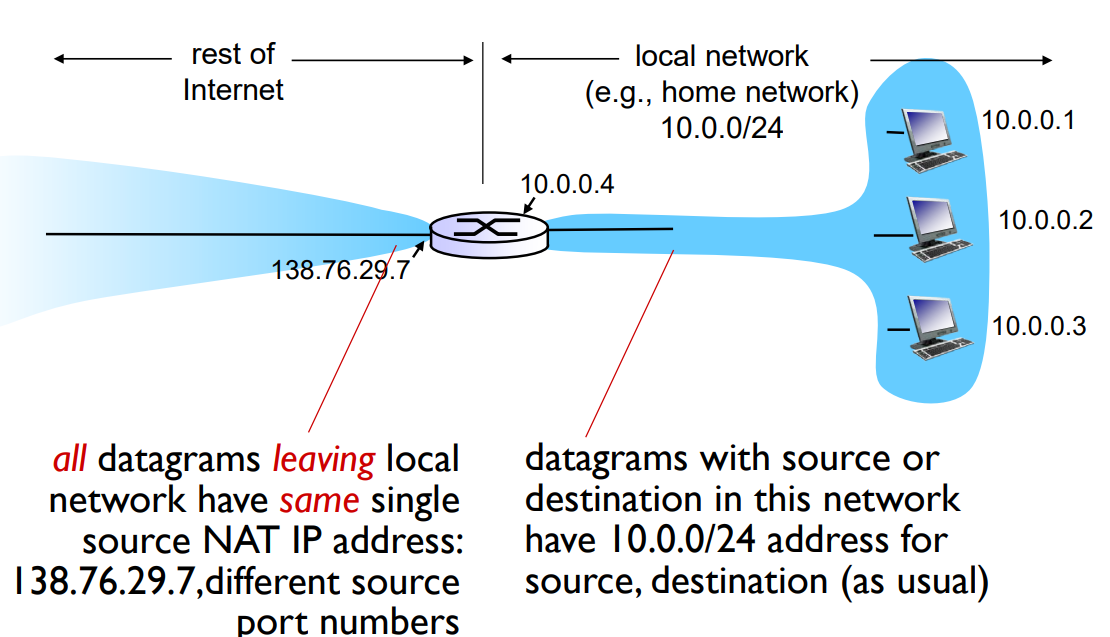
그래서 NAT 방식에서는, 네트워크 내부에서는 유일한 IP 주소를 사용합니다. 그래서 10.0.0.1, 10.0.0.2. 내부에서는 유일합니다. 그러나 내부에서만 유일하기 때문에 또 다른 네트워크의 내부에서 이 IP 주소를 사용할 수 있습니다.
그래서 이러한 IP를 가진 패킷이 외부로 나갈 때는 NAT 기능을 하는 이 게이트웨이 라우터의 IP 주소(전 세계적으로 유일)로 바꿔줍니다. 받는 사람 측에서는 라우터에서 메시지가 온 줄 압니다.
그럼 다시 리턴 패킷을 보낼 때 라우터로 보낼 것 입니다. 그러면 리턴 패킷이 들어올 때는 방금 이 변환 작업을 그대로 반대로 해주게 됩니다. 이게 바로 NAT의 동작 입니다.

게이트웨이 라우터는 NAT를 동작하고 있고, 게이트웨이 라우터에 IP 주소는 여러개 입니다. 왜냐하면 인터페이스 개수만큼 있으니까 IP 주소가 여러 개 있습니다.
그런데 이 그림 같은 경우에는 이 게이트웨이 라우터는 인터페이스가 두 군데고, 각자 IP 주소를 가지며, 서브넷 두 개의 멤버입니다.
그런데 서브넷이라는 건 뭐냐면, 같은 prefix, 같은 네트워크 아이디를 갖는 애들의 집합 입니다. 그럼 결국에는 라우터의 한 인터페이스는 오른쪽 서브넷의 prefix를 가질 수밖에 없죠.
그렇기 때문에 여기 오른쪽에서 10.0.0 이런 prefix를 가진다면, 마찬가지로 이 인터페이스도 10.0.0이라는 prefix를 가지게 됩니다. 그러나 왼쪽 서브넷은 또 주소가 다릅니다.
Implementation: NAT router must:
• Outgoing datagrams: replace (source IP address, port #) of every outgoing datagram to (NAT IP address, new port #) . . . remote clients/servers will respond using (NAT IP address, new port #) as destination addr(자기 자신의 IP 주소를 받는데, 이 IP 주소는 내부적으로는 유일하되, 외부적으로 봤을 때는 재사용 가능한 IP 주소입니다.)
• Remember (in NAT translation table) every (source IP address, port #) to (NAT IP address, new port #) translation pair
• Incoming datagrams: replace (NAT IP address, new port #) in dest fields of every incoming datagram with corresponding(source IP address, port #) stored in NAT table
