
1. Linear Probing 소개
개방 주소법(open addressing)
- 테이블의 크기(M) > 원소의 수(N)을 유지하며, 빈 공간을 collision 해결에사용
- Linear probing은 개방 주소법의 가장 단순한 형태
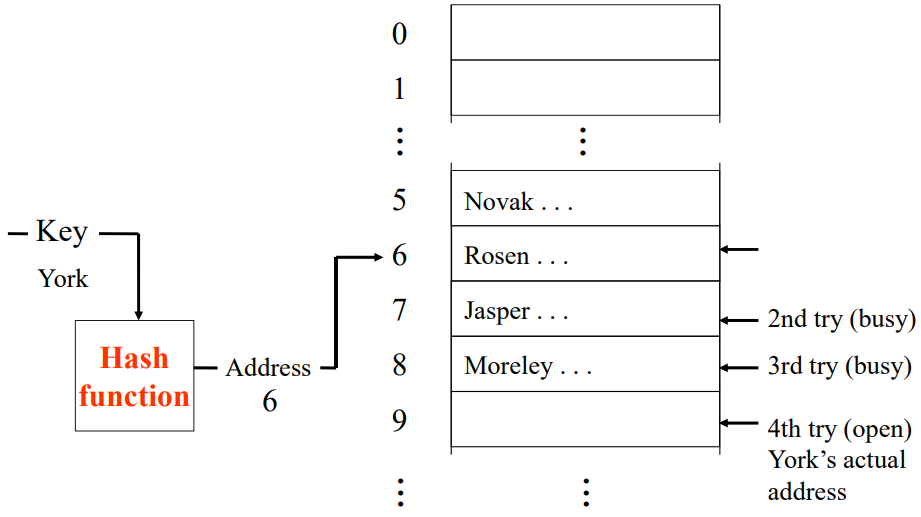
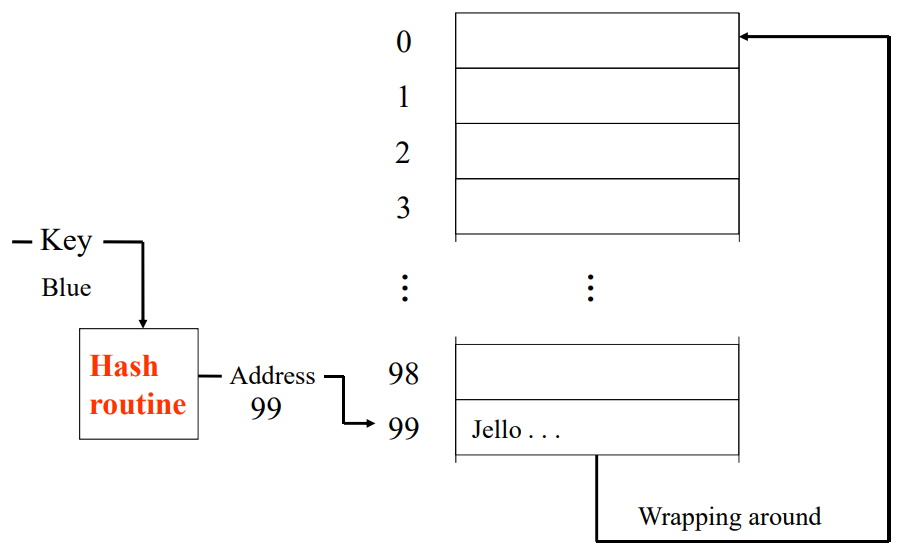
선형 탐색법(linear probing)
- h(key) -> 0 부터 M – 1 사이의 주소 i를 반환
- get(key)의 구현
i에 찾는 key가 존재할 경우: search hit
i가 null이면: search miss
i에 다른 key가 저장되어 있으면: collision 발생
(i + 1) % M부터 이후 주소를 계속 검사
언제까지? -> NULL 을 발견하거나 Key를 찾을때까지 아래로 내려가면서 검사
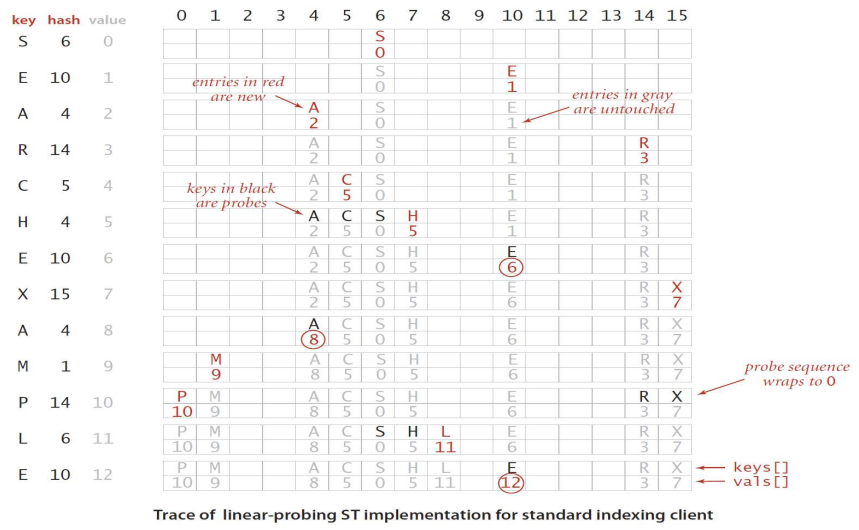
public class LinearProbingHashST<K,V> {
private int N;
private int M; // 항상 M > N을 만족하여야 함.
private K[] keys; // 키를 저장하는 배열
private V[] vals; // 값을 저장하는 배열
public LinearProbingHashST() { this(31); }
public LinearProbingHashST(int M) {
keys = (K[]) new Object[M];
vals = (V[]) new Object[M];
this.M = M;
}
public boolean contains(K key) { return get(key) != null; }
public boolean isEmpty() { return N == 0; }
public int size() { return N; }
private int hash(K key) { return (key.hashCode() & 0x7fffffff) % M; }
public V get(K key) {
for (int i = hash(key); keys[i] != null; i = (i + 1) % M) // 테이블 순회
if (keys[i].equals(key)) // search hit
return vals[i];
return null; // search miss
}
public void put(K key, V value) {
if (N >= M / 2) resize(2 * M + 1); // 테이블 재구성: 다음에 설명
int i;
for (i = hash(key); keys[i] != null; i = (i + 1) % M)
if (keys[i].equals(key)) { // 기존에 존재하는 키
vals[i] = value;
return;
}
keys[i] = key; // 새로 (키, 값)의 쌍을 추가
vals[i] = value;
N++;
}
}2. Linear Probing의 성능

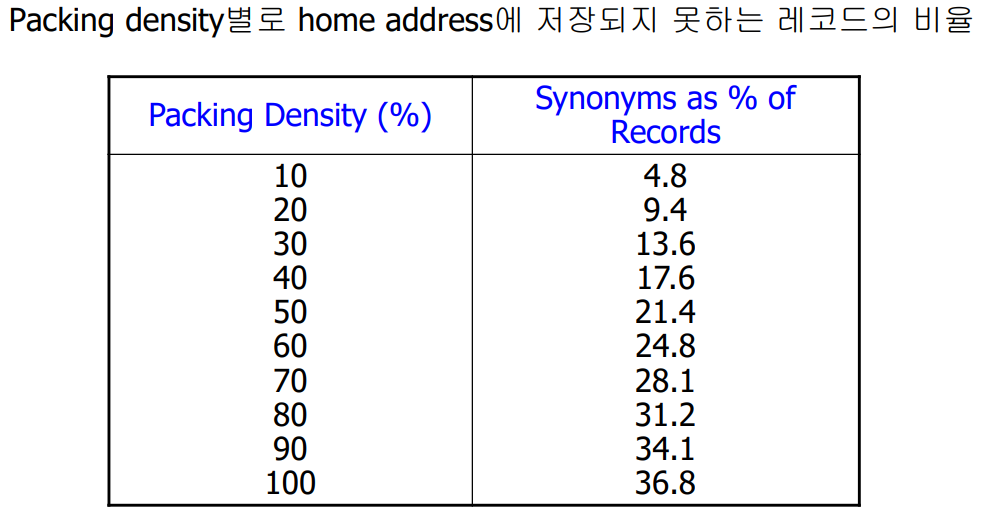
1. Effect of Packing Density
2. Linear Probing의 문제점: Clustering
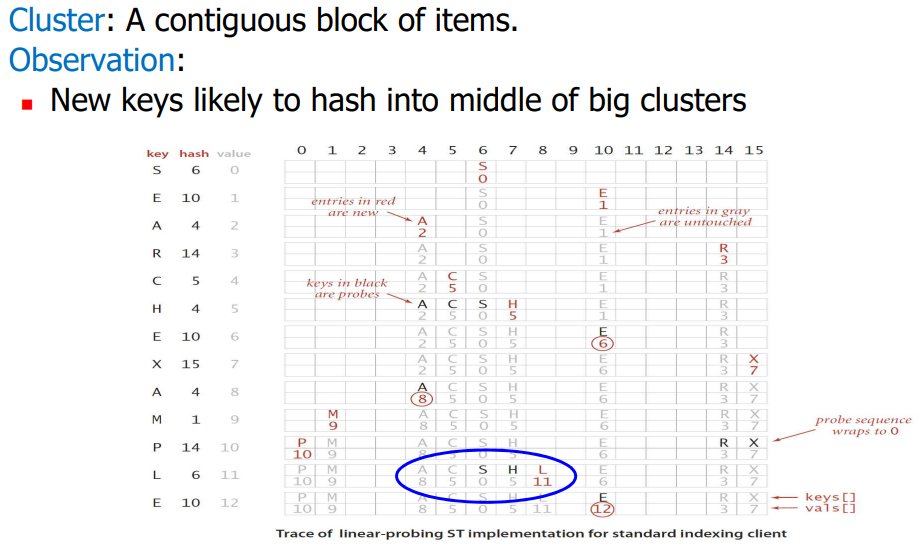
3. Search Length


average search length는 위의 공식에 따라 11/5 = 2.2 가 됩니다.
4. Packing Density와 Search Length
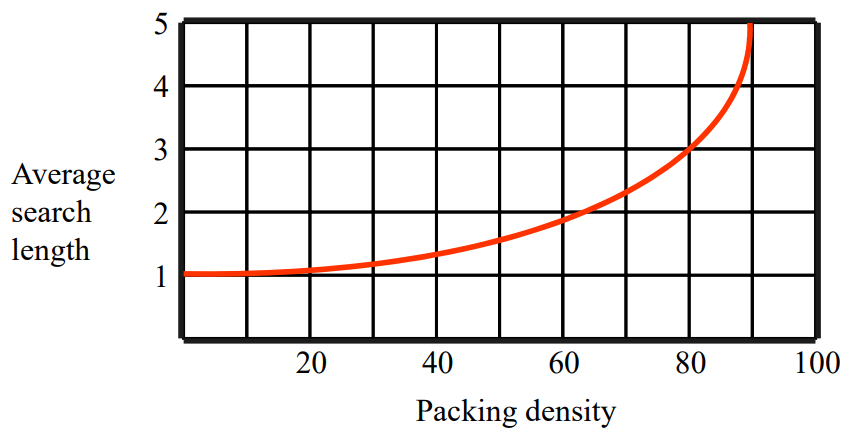
5. 해시 테이블의 재구성

3. 버킷(Bucket)
하나의 주소 공간 = 하나의 Bucket
- 해싱의 결과로 bucket 주소 결정
- 설계시 고려사항
하나의 bucket에 몇 개의 원소(B)를 저장할 것인가?
Synonym들을 하나의 bucket에 저장- 예: 100개의 메모리가 가용
방안 1: M = 100, B = 1
방안 2: M = 50, B = 2
방안 3: M = 25, B = 4
…- Bucket overflow? -> 다른 버킷에 저장.
- Bucket내에서 검색 방법? -> 순차검색
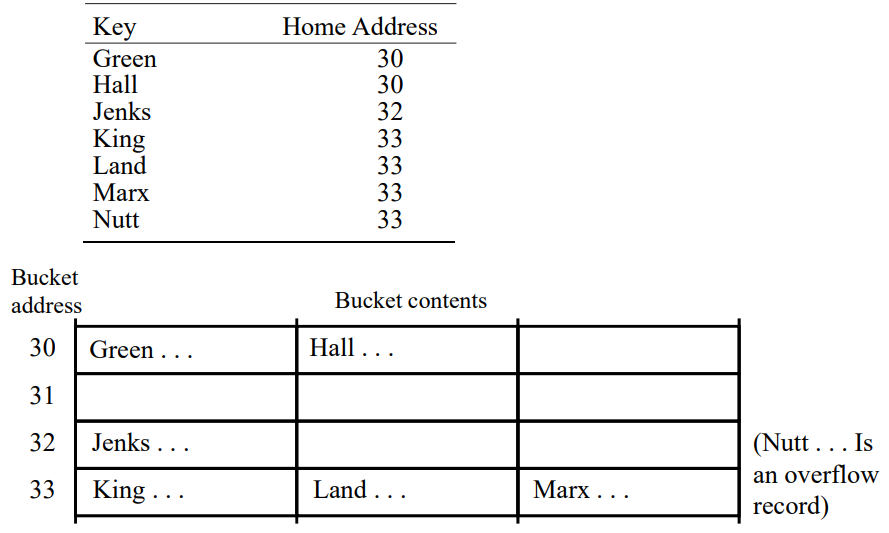
1. Bucket 크기 = 3인 경우의 예
2. Linear Probing에서 다양한 Packing density와 Bucket 크기에 따른 Average search length
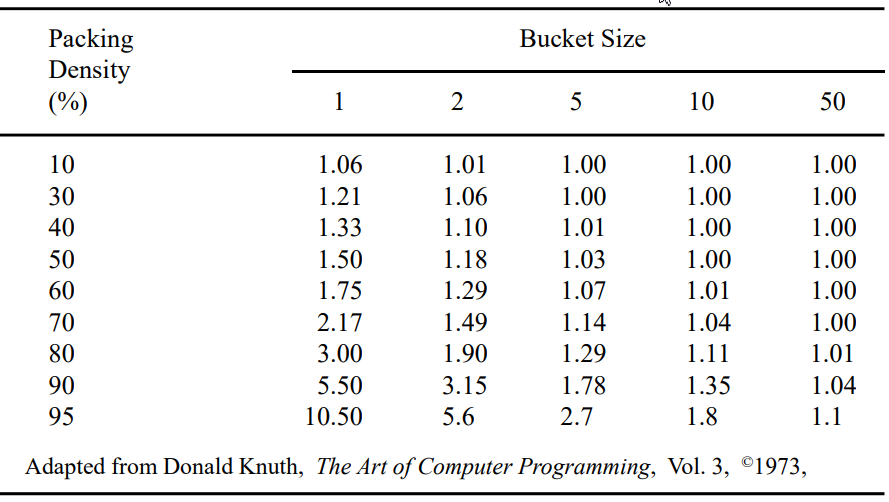
버킷 용량이 커지면 Average search length가 작아집니다.
위 표는 버킷 내에서의 순차검색의 수는 고려하지 않고 있습니다.
4. Linear Probing에서 삭제 연산
Record 삭제 시 고려 사항
- Collision으로 인해 record가 다른 위치에 존재 가능
Record 삭제 후 재배치 필요- Free slot은 이후 새로운 record에 할당 가능하도록.


1. Lazy Deletion - Tombstone
기본 개념
- Record 삭제 후, 삭제 되었다는 표시를 남기자.
- Free slot과는 구분
장점
- Search 중 tombstone이 발견되면, 계속 search
- Tombstone 위치에 새로운 record 저장 가능
주의 사항
- Searching delay : 거듭되는 deletion의 결과로, tombstone 과다 존재 NULL 이되야 Stop 하는데 NULL이 안나오니 계속 서치를 하게된다.
- 중복 확인 곤란 : 만약에 tombstone 자리를 재활용 하기위해서 새로운 Smith 삽입한다고 하면, Smith가 있는지 없는지 여부를 확인하기 위해서 tombstone이 많을 수록 쓸모없는 서치를 많이하게 된다.
2. Lazy Deletion 문제점 해결방안
Local reorganization at each deletion
Complete reorganization after threshold
다른 collision resolution algorithm 사용
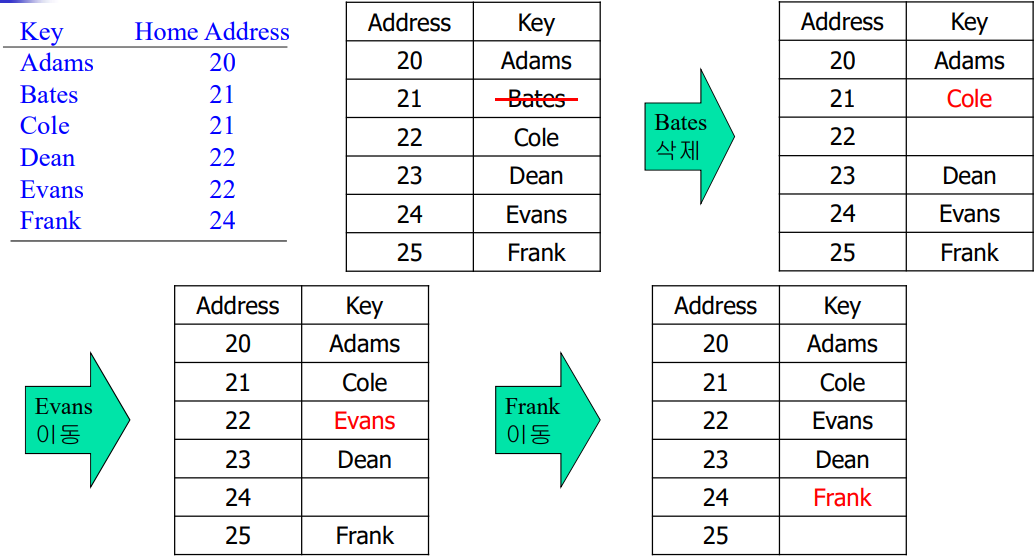
public void delete(K key) {
if (!contains(key)) return;
int i = hash(key); // 테이블에서 key가 저장된 위치를 검색
while (!key.equals(keys[i]))
i = (i + 1) % M;
keys[i] = null; vals[i] = null; // 키와 값을 삭제
i = (i + 1) % M; // rehash all keys in same cluster
while (keys[i] != null) { // delete keys[i] and vals[i], and reinsert
K keyToRehash = keys[i];
V valToRehash = vals[i];
keys[i] = null; vals[i] = null; N--;
put(keyToRehash, valToRehash);
i = (i + 1) % M;
}
N--;
}
가장 아름다운 정답은 서로의 협업안에 있다.