Prologue
Backbone과 RPN으로부터 넘어오는 data를 받아서 최종적으로 bbox와 그 안에 있는 object의 class를 예측하는 모듈이다. 2 stage detector, 1 stage detector 모두에 두루 쓰인다.
RoI Pooling Layer
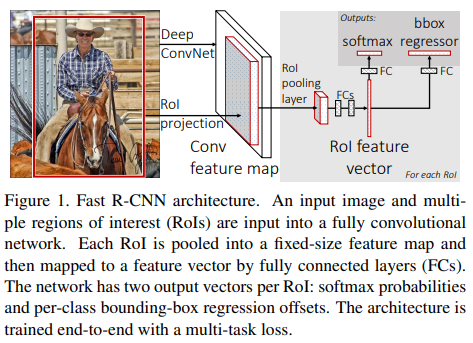
Fast R-CNN에서 제안한 방법으로 후속연구에서 지속적으로 쓰인다. selective search가 찾은 RoI를 faeture map에 projection해서 RoI에 들어있는 object의 class를 예측하고 bbox를 한 번 더 정제한다.
나는 이 다이어그램에서 projection한다는 의미가 좀 와닿지 않았는데 ResNet에서 identity mapping할 때 tensor의 크기를 맞춰주는 거랑 비슷한 작업이었다.
RoI projection
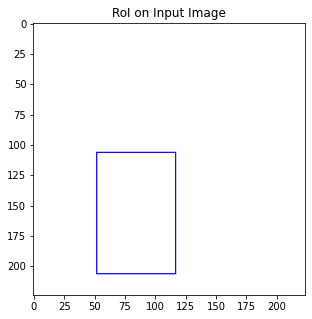
ResNet을 backbone으로 쓴다고 했을 때 편의상 spatial dimension만 따지면 입력 이미지의 크기는 , 출력 feature map은 이다. 이때 feature map은 입력 image에 비해 32배 작은데 이 점을 이용해서 입력 image의 RoI를 feature map에 대응하는 RoI로 바꿀 거다. 연구에서는 이 작업을 RoI projection이라고 부르고 있다.
예를 들어 RoI를 [52, 106, 117, 206]이라고 하자.
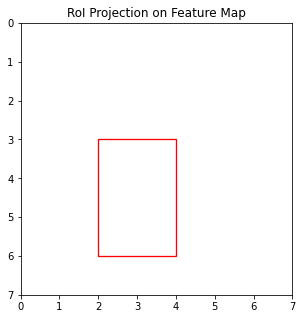
feature map상의 RoI는 [1.625, 3.3125, 3.65625, 6.4375]이다. pixel을 1보다 작은 수로 쪼갤 수 없으므로 floating point를 그대로 쓸 수는 없기 때문에 반올림해준다. 그러면 feature map상의 RoI는 [2, 3, 4, 6]이라고 대략 짐작하는 셈이다.
Pooling
FC layer에 집어넣기 위해 max pooling을 한다. feature map에서 가장 강한 신호를 하나 골라내는 작업이므로 classification 성능이 좋다. pooling layer의 output이 , feature map위의 RoI가 일 때 pool size를 계산하는 방법으로 이렇게 제안했다.
이 예시에서는 projected roi를 크기로 pooling한다고 할 때 반올림해서 만큼의 영역을 우선적으로 잘라서 max pooling을 수행한다.
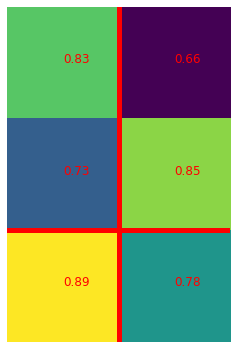
이렇게 해서 크기의 결과물을 얻을 수 있다.
여기에서는 1개 channel만 다뤘지만 ResNet은 개의 channel을 가지고 있다. 실제로 detection model이라면 크기의 feature가 남는다. 이거 가지고 나머지 레이어에 집어넣어서 처리해주면 된다.
Epilogue
사실 feature map에 project한 RoI를 다시 입력 image로 옮겨보면 [64, 96, 128, 192]로 원래 RoI [52, 106, 117, 206]와는 조금 다르다.

단순히 bbox를 그리려면 조금 차이나는 거야 detection과제에서는 좀 참고 넘어갈 수 있지만 segmentation할 때는 오차가 난다는 문제가 있다. 이점을 보완하려고 Mask R-CNN에서 정확한 segmentation을 위해 RoI projection할 때 가중치를 주는 것 같은 느낌의 RoI Align을 고안했다.
