Prologue

"parameter 4개로 코끼리 모양도 구현하겠다. 5개로는 코도 움직일 걸?" - 폰 노이만
What did the authors try to accomplish?
#1. 대규모 parameter가 가진 힘으로 딥러닝 모델은 객체탐지, 자연어 처리, 음성인식 같은 복잡한 과제를 처리할 수 있게 됐다. parameter는 양날의 검 같은 거라 많을수록 학습을 더 잘하지만 overfitting도 쉽게 일어난다. 모델학습 차원에서 이것을 피하기 위한 선택지로 early stopping, L1 & L2 regularization이 있다.
#2. 비슷한 맥락으로 overfitting을 피하면서 성능 좋은 모델을 만드려면 서로 다른 구조와 서로 다른 학습 데이터를 가진 모델 어려 개를 학습해서 평균내야 한다. 시간과 자원이 무제한이라면 가장 좋은 방법이겠지만 우리의 시간과 자원은 한정적이고 항상 모자라는 축에 속한다.
연구자들은 overfitting의 원인은 co-adaptation이라고 지목했다.
Overfitting
우리가 머신러닝, 딥러닝 모델을 사용하려는 이유는 학습데이터를 통해 새로운 데이터를 예측하는데 있다. 머신러닝 모델은 학습데이터가 가진 특성뿐만 아니라 노이즈들도 함께 학습하는데 학습데이터를 과도하게 학습하면 새로운 데이터를 예측할 수 없으므로 overfitting을 최대한 피해야 한다.
Co-adaptation
생몰학에서 온 개념이다. 어떤 특성이 집단의 생존에 유리하게 작용하면 이 특성은 후세에 더 잘 발현하고 진화한다. 반대로 불리하면 이 특성은 후세에 점점 퇴화하다가 결국 발현하지 않는다. 이것을 co-adaptation이라고 하는데 신경망 내부에서도 일어난다. 수식으로 살펴보면 인접레이어 node의 영향을 받아 학습할 수밖에 없다는 점을 알 수 있다.
for and hidden unit
where is activation function
예측하는데 유리한 신호가 입력된 node에는 가중치를 더하는 방향으로, 불리한 신호가 들어온 node에는 가중치를 빼는 방향으로 학습한다. 학습데이터를 과도하게 학습한 모델은 실제 데이터는 예측하지 못하게 되는 것이다.
What were the key elements of the approach?
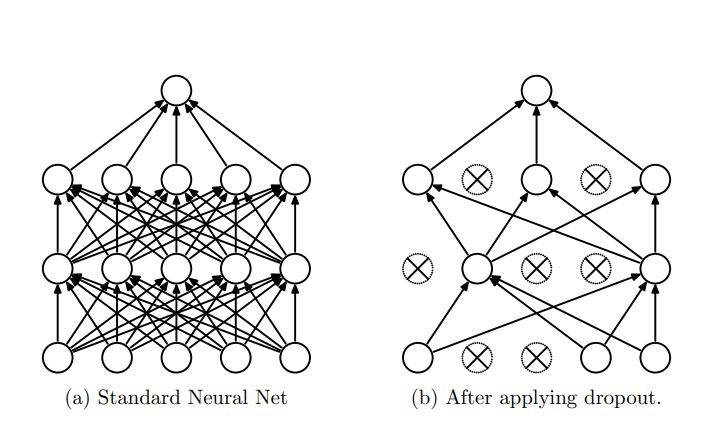
연구자들은 임의의 확률로 node를 꺼버리면 co-adaptation을 낮출 수 있을 거라고 생각했다.
수식에서 가 베르누이 분포를 따르므로 개의 node를 가진 Dropout layer의 경우의 수는 이다. iteration이 높더라도 같은 네트워크가 만들어질 가능성은 거의 없다. epoch마다 서로 다른 네트워크가 학습해서 평균내는 샘이다.
Implementation
Causion
주의할 점이 있다면 학습할 때는 p의 확률로 node가 꺼지지만 추론할 때는 모든 node가 활성화한다. 그래서 추론할 때는 node에 입력되는 신호의 강도는 학습에 비해 p만큼 비례한다고 근사한다.
class Dropout:
def __init__(self, p: float=0.5, props: str='fwd',
status: str='train', cache=None) -> None:
self.p = p
self.props = props
self.status = status
self.cache = cache
def dropout_forward(self, X: np.array):
mask = np.random.randn(*X.shape) > self.p
if self.status == 'train':
cache = mask, p
out = X * mask
return out, cache
elif self.status == 'test':
if self.cache is not None:
mask, p = cache
return X * p
def dropout_backward(self, dout: np.array):
if self.cache is not None:
mask, p = self.cache
return dout * mask
def __call__(self, **kwargs):
if self.props == 'fwd':
return dropout_foward(**kwargs)
elif self.props == 'bwd':
return dropout_backward(**kwargs)Epilogue
우리에게 시간을 벌어다 주는 연구다. 이런 논문들은 보고 있으면 읽는 내내 와..와...하게 된다. 저자들이 어떤 사람들과 어떤 대화를 하면 이런 통찰을 하나 싶다.
찾아보니까 node를 끄는 거 말고 그냥 edge를 끊는 방법도 있다는데 edge를 끊는다니 와닿지 않지만 이것도 한 번 찾아서 읽어봐야겠다.
