
안녕하세요. 현재 백엔드 개발자를 목표로 취업을 준비중인 주니어 개발자입니다. 기존에 사용 중인 Object Mapping 기술인 Mybatis를 대신하여 Object Relational Mapping 기술인 JPA를 사용하고자 학습하게 되었으며, 학습 과정에서 알게된 내용을 바탕으로 JPA가 무엇인지, 그리고 왜 사용해야 하는지에 대한 내용을 정리해 보았습니다.
What is JPA?
1. Java Persistence API. 즉, 자바 영속성 API를 뜻합니다.
-
영속성이란?
-
지속성이라고도 하며, 데이터를 생성한 프로그램이 종료되어도 사라지지지 않는 데이터의 특성을 말합니다.
처음에 이러한 개념은 JPA의 동작 방식과 연관하여 이해하기 쉽지 않았습니다.
저는 임시적으로 DB에 저장된 데이터가 영속상태라는 것을 떠올리며 학습을 이어나갔습니다.
공식적인 정의는 아래 링크를 참고 부탁드립니다.
Hubernate ORM - Persistence
-
2. 자바 진영의 ORM 기술표준이며, 애플리케이션과 JDBC 사이에 동작한다.
- ORM 이란?
- Object-Relational Mapping의 약자로 객체와 관계형 데이터베이스를 매핑한다는 의미를 가지고있습니다. 즉, 객체(Object)와 RDB를 매핑시는 기술입니다.
- 우리가 보편적으로 사용하는 RDB는 객체지향적 특성(상속, 다형성, 레퍼런스) 등이 없어 Java와 같은 객체지향적 언어로 접근하기 쉽지 않습니다. 이러한 점을 개선하기 위해 ORM을 사용하여 조금 더 객체지향적으로 RDB를 다룰 수 있게 되었습니다.
3. JPA는 인터페이스입니다.
그렇기에 Hibernate, EclipseLink, DataNucleus 등의 ORM 프레임워크를 사용해서 구현이 가능합니다.
](https://velog.velcdn.com/images/alicesykim95/post/9f8af7ab-d3e3-4045-9376-893b14c72223/%E1%84%8C%E1%85%A1%E1%84%87%E1%85%A1_%E1%84%89%E1%85%A5%E1%86%AF%E1%84%86%E1%85%A7%E1%86%BC45.jpg)
Hibernate 란?
-
인터페이스인 JPA를 구현하기 위한 구현체로
javax.persistence.EntityManage와 같은 인터페이스를 직접 구현한 라이브러리입니다.
Why use JPA?
🗣 지금부터는 제가 직접 작성한 코드를 기반으로 설명드리겠습니다. 조금 더 적절한 설명을 원하신다면 게시글 하단에 링크한 블로거분들의 글과 ‘자바 ORM 표준 JPA 프로그래밍’ 도서와 강의를 추천드립니다.
JPA를 사용하기 이전 제가 사용했던 방식에 대해 우선 설명을 드리겠습니다.
1. 순수 JDBC
Java 언어를 사용하여 DB에 데이터를 저장하기 위해서는 기본적으로 JDBC API를 사용해야 합니다.
public void updateShop(MyShopDto dto) {
Connection conn = null;
PreparedStatement pstmt = null;
String sql = "update myshop set sangpum=?,photo=?,color=?,price=?,ipgoday=? where num=?";
//db연결
conn = db.getMysqlConnection();
try {
pstmt = conn.prepareStatement(sql);
//바인딩
pstmt.setString(1, dto.getSangpum());
pstmt.setString(2, dto.getPhoto());
pstmt.setString(3, dto.getColor());
pstmt.setInt(4, dto.getPrice());
pstmt.setString(5, dto.getIpgoday());
pstmt.setString(6, dto.getNum());
//실행
pstmt.execute();
} catch (SQLException e) {
e.printStackTrace();
} finally {
db.dbclose(conn, pstmt);
}
}위 코드는 제가 개발을 시작했던 초기 시절 작성한 순수 JDBC를 사용하여 데이터를 수정하는 메서드입니다. 매번 JDBC API와 SQL을 직접 입력해야만 했기 때문에 번거로운 과정이 많았습니다.
2. Mybatis
SQL Mapper 기능을 가진 Mybatis를 사용하여 비즈니스 로직과 SQL을 분리했으며, JDBC의 제어는 Spring framwork에 위임하여 순수 JDBC만 사용했을때와는 다르게 비즈니스 로직에 조금 더 집중할 수 있게 되었습니다.
- Mabatis 란?
Java persistence framework의 하나로 SQL Mapper를 통해 객체와 SQL을 매핑(ObjectMapping)해주는 역할을 합니다.
<bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="com.mysql.cj.jdbc.Driver"></property>
<property name="url" value="jdbc:mysql://localhost:3306/schema?serverTimezone=Asia/Seoul"></property>
<property name="username" value=""></property>
<property name="password" value=""></property>
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="configLocation" value="classpath:mybatis-config.xml"/>
<property name="mapperLocations" value="classpath:mapper/*Mapper.xml"/>
</bean>
<bean id="sqlSession" class="org.mybatis.spring.SqlSessionTemplate">
<constructor-arg ref="sqlSessionFactory"/>
</bean>
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>JDBC의 제어를 위임하기 위해 Bean 으로 등록
@Repository
public class MyShopDao implements MyShopDaoInter {
String ns = "bit.data.dao.MyShopDao.";
@Autowired
SqlSession session;
@Override
public int update(MyShopDto dto) {
return session.update(ns + "updateMyShop", dto);
}
}비즈니스 로직(Cotroller - Service - Repository - Mapper 구조)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//**mybatis.org**//DTD Mapper3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="data.repository.MyShopRepository">
<update id="updateMyShop" parameterType="MyShopDto">
UPDATE myshop set sangpum=#{..},photo=#{..},color=#{..},price=#{..},ipgoday=#{..} where num=#{..}";
</update>
</mapper>Java 객체와 SQL매핑
하지만 이러한 과정도 어찌보면 객체지향스럽다는 느낌이 부족하며 개발자가 해야할 업무가 많은 것 처럼 느껴집니다. (사소한 비즈니스 내용이 수정되면 API 로직과 SQL을 매번 수정해야했습니다.)
😂
java.sql.SQLException: Parameter index out of range와 같은 오타로 인한 에러가 저를 가장 힘들게 했었기에 어쩌면 더욱 더 Mybitis에서 벗어나고 싶었던 것 같습니다.
3.JPA
위 모든 과정이 JPA를 사용함으로써 아래 코드와 같이 단순화 됩니다.
public class MyShopRepository{
@Autowired
EntityManager em;
private final EntityManager em;
public void update(MyShopDto dto){
MyShop myshop = em.find(MyShop.class, dto.getNum());
myshop.setSangpum(dto.getSangpum());
...
}
}위의 예제는 num 값으로 상품을 조회하고, 조회한 상품의 데이터를 수정하는 코드입니다. 별도의 Update 쿼리 없이 위 코드만으로 데이터 수정이 가능한 이유는 ORM 기술에 의해 DB에서 조회한 데이터들이 객체에 연결되어 있고, 객체의 값을 수정하는 것은 DB를 수정하는 것으로 인식(Dirty Checking)되기 때문입니다.
- Dirty Checking 이란?
- 변경 감지라고도 부르며 엔티티의 변경 사항을 데이터베이스에 자동으로 반영하는 기능을 의미합니다.
JPA를 제대로 사용하기 위해서는 엔티티에 추가적인 관계형성 작업(Many to one, One to Many 등)이 필요합니다. 하지만 이러한 내용들을 넣기에는 게시글의 기획 의도와 일치하지 않음으로 배제한 점을 참고 부탁드립니다.
JPA를 사용해야하는 이유
- 기본적인 CRUD 작업이 간소화됩니다.
- 유지보수가 간편해집니다.
- 테스트 작성이 용이해집니다.
- DB에 맞는 방언으로 변환해줍니다.
1. 기본적인 CRUD 작업 간소화
Mybatis를 사용시 매번 CRUD에 해당하는 쿼리들을 모두 작성해주어야했었습니다. 하지만 JPA에서는 테이블과 객체를 매핑하기에 간단한 CRUD 쿼리는 JPA가 작성하여 던지기 때문에 생산성을 높일 수 있습니다.
2. 유지보수 간편화
Mybatis와 같이 SQL을 직접 다루게 될 경우 객체에 속성을 하나만 추가하더라도 해당 객체와 관련된 SQL과 결과를 매핑하기 위한 API 코드를 모두 변경해야만 했습니다. 반면에 JPA를 사용하면 이러한 작업을 JPA가 대신 처리해주므로 수정해야 할 코드가 줄어듭니다. 이는 곧 개발자가 작성해야할 작업을 JPA대신 처리하기에 유지보수가 간편해진다는 것을 의미하게됩니다.
3. 테스트 작성이 용이해집니다.
기존 DB와 데이터를 주고 받는 테스트를 진행할 경우 매번 DB를 직접 다뤄야 했습니다. 반면, JPA는 테이블을 자동으로 만들어주는 기능을 제공하기에 DB를 직접 다루지 않고 test cast 작성에만 집중할 수 있기에 더 자주 테스트 할 수 있게 되었으며 이는 세밀한 테스트의 빈도수를 늘려주는 역할을 해주었습니다.
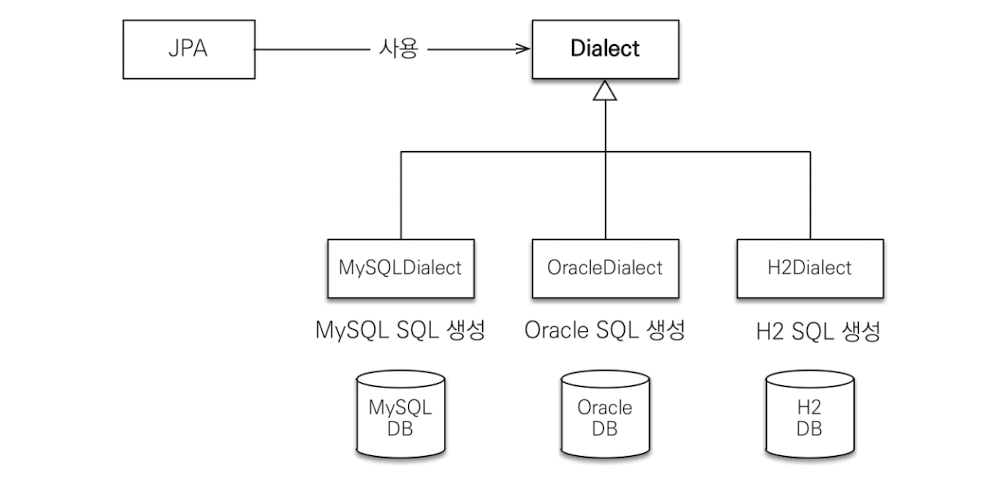
4. DB에 맞는 방언으로 변환
RDB는 동일한 기능도 각 벤더사마다 사용법이 다른 경우가 많습니다. 이러한 사항은 처음 선택한 DB 기술에 종속되게 되며 다른 데이터베이스로 변경하는 것이 매우 어려워집니다. 하지만 JPA는 애플리케이션과 DB 사이에 추상화된 데이터 접근 계층을 제공함으로 애플리케이션이 특정 데이터베이스 기술에 종속되지 않도록 합니다.(로컬 개발은 H2, 상용 환경은 MySQL 등 으로 사용이 가능해집니다.)
참고 자료
- 자바 ORM 표준 JPA 프로그래밍(도서 및 inflearn강의) - 저자 : 김영한
- https://mangkyu.tistory.com/20 - 블로거 : 망나니개발자
- https://suhwan.dev/2019/02/24/jpa-vs-hibernate-vs-spring-data-jpa/
- https://hibernate.org/orm/
