
Database
데이터를 저장하고, 연산하고, 보존하기 위한 시스템.
반대되는 개념은 Memory(휘발성이 있음). Memory와 달리, 저장되는 성질로 인해 DB는 속도가 더 느림.
따라서 저장되지 않아 속도가 빠른 Memory에서 정보를 읽어 들여 가공처리 후, 속도는 느리지만 휘발성이 없어 저장하기에 적합한 Database에 정보를 저장함
Database를 사용 시, 데이터 접근 및 편집, 가공, 관리가 편리해진다.
RDBMS
RDBMS 내에서 모든 데이터는
테이블(column(열, 테이블의 각 항목), row(행, 각 항목들의 실제 값을 의미)로 구성)로 구성(like 엑셀)
각 로우에는 고유키가 존재하는데 주로 PK(Primary Key)를 이용해 해당 로우를 찾는다.
핵심: Foreign Key로 테이블간의 관계 형성
RDBMS에서의 테이블끼리의 관계
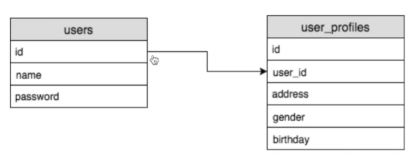
1. One To One (일대일)
유저 테이블에 기록된 하나의 유저는, 유저 프로파일에 기록된 하나의 프로파일 아이디만 가질 수 있음(하나의 유저가 하나의 정보를 참조)
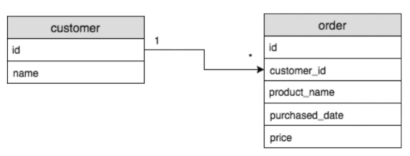
- One To Many (일대다)
한 고객이 여러 개의 주문을 할 수 있듯, 하나의 주체가 여러 개의 상태 값을 가질 수 있음
(하나의 유저가 여러 개의 정보를 참조)
하나의 카테고리에 그에 해당하는 여러 제품이 들어가는 구조도 이에 해당
- Many To Many (다대다)
위의 두 개념과 달리 좀 더 복잡하고 이해하기 어려우니 바로 예로 설명하자면,
하나의 책에 여러 명의 공동 저자가 존재한다고 가정할 때, 책의 정보를 가지고 있는 books 테이블과 공동 저자들의 정보를 담은 authors 테이블이 각각 참조되어지는 authors_books라는 중간 테이블(Association table)로 연결되는 구조. authors_books 테이블에는 여러명의 저자의 아이디와 책의 아이디가 모두 기록됨. (책은 여러 작가에 의해 쓰일 수 있고(공동 저자), 각각의 저자들은 여러 책을 쓸 수 있다)
일방적인 One To Many가 양 side에서 함께 합쳐지면, 멀리서보면 결국 Many To Many.

정규화 (Normalization)
그럼 왜 테이블을 연결하나?
하나의 테이블에 모든 정보를 넣으면
1) 동일한 테이터들의 불필요한 중복이 발생할 수도 있고
2) 더 많은 디스크를 사용하게 되고
3) 잘못된 데이터가 저장될 가능성도 높아진다
하지만 여러 테이블에 나누어 저장한 데이터들을 차후에 연결시키면 위의 문제가 사라지게 되는데,
이를 데이터 정규화(Normalization)이라고 부르는 것!
제 1, 2, 3 정규화가 있는데 제 3정규화 정도만 하면 어느 정도 괜찮은 정규화.
정규화
[출처] https://victorydntmd.tistory.com/132RDBMS를 잘 다루기위한 필수 과정으로, 관계형 모델을 전제로 구축된 DB 설계 이론.
가장 큰 장점은 모순을 방지한다는 것이다. 모순이란 논리적으로 불일치한 데이터가 발생한 상황을 말한다. 이러한 데이터 모순 상황은 정규화를 통해 중복을 제거함으로서 해결이 가능하다.
결국 정규화란 릴레이션 내의 중복을 제거하는 과정이다.정규화는 제 1정규형부터 차례로 제 6정규형까지 있는데 올라갈수록 그 정규화 정도가 까다로와진다. (높은 단계의 정규형은 그 이전까지의 정규형을 모두 만족해야하므로)
- 제 2정규형, 제 3정규형, 보이스코드 정규형은 함수 종속성의 제거를 통해 이루어진다.
- 제 4정규형, 제 5정규형, 제 6정규형은 결합 종속성의 제거를 통해 이루어진다.
정규형 알아보기
1) 제 1정규형
- 릴레이션이어야 한다
- 중복 튜플이 없다
- 구체적인 값을 가져야 한다 (NOT NULL)
- 원자성: 값은 의미가 있는 한 묶음의 데이터, 즉 원자 단위여야 한다 (각 행마다 한 컬럼에 하나의 값만을 가질 것)
2) 제 2정규형
- 제 1 정규형을 만족한다
- 후보키의 진부분집합에서 키가 아닌 속성에 대해 부분함수 종속성을 제거
위의 예제에서 정규화를 하기 전 테이블을 보면, 이름과 학과는 후보키이다. 후보키 중 하나인( 진부분집합 ) 이름을 알면 학년을 알 수 있으므로 함수 종속이 존재. 2NF는 이러한 함수 종속을 제거하는 작업! 함수 종속을 제거하려면 원래의 릴레이션을 무손실 분해시켜야 한다. 따라서 종속 관계가 있는 속성만 추출해서(projection, 프로젝션 해서 새로운 릴레이션을 만든다. 즉 1) 이름과 학년을 애트리뷰트로 갖는 새로운 릴레이션이 생성되고, 2) 기존에 있던 원래 릴레이션은 떨어져나간 애트리뷰트(학년)를 제외한 릴레이션으로 존재 함수 종속을 제거함으로써 이렇게 두 개의 릴레이션으로 쪼개지고, 두 릴레이션을 결합하면 원래의 릴레이션이 되므로 무손실 분해가 이루어진 것이다.3) 제 3정규형
- 제 1, 제 2 정규형을 만족한다
- 추이 함수 종속성을 제거
위의 예제에서 후보키인 학번을 알면 우편번호를 알 수 있고, 우편번호를 알면 나머지 모든 주소(나머지 모든 애트리뷰트 값)을 알 수 있다. 이럴 때 추이함수 종속관계라고 한다. 따라서 우편번호 애트리뷰트를 기준으로 릴레이션을 분해한다. (릴레이션 분해는 제 2정규형과 같은 방법으로 이루어진다)



트랜잭션 (Transaction)
질의를 하나로 묶음 처리하여, 만일 중간에 실행이 중단되었을 경우 처음부터 다시 실행하는 rollback을 수행하고, 오류 없이 마치면 commit을 하는 실행 단위를 의미.
한 번의 질의가 실행되면 질의가 모두 수행되거나 모두 수행되지 않는 작업 수행의 논리적 단위.
ex. 친구에게 인터넷 뱅킹으로 만원 송금 시, 내 계좌에서는 만원을 차감하고 친구의 계좌에는 만원을 증가시켜야 함. 근데 만일, 알수없는 오류로 인해 내 계좌에서는 차감되고 친구 계좌에 증가가 없다면? 망했다! 만원 공중 증발!
--> 이런 경우 다시 처음부터 없던 일로 하고 송금을 다시 실행하게 하는 것이 rollback. 반대로, 아무 일도 발생하지 않고 정말 송금이 잘 되었다? 그 경우에는 commit. 이런 논리적 수행의 단위를 트랜잭션이라고 말할 수 있는 것
DBMS의 성능은 초당 트랜잭션 실행 수로 측정. 이를 TPS라고 부름
트랜잭션은 DB서버의 여러개의 클라이언트가 동시에 액세스하거나, 응용 프로그램이 갱신을 처리하는 과정에서 중단될 수 있는 경우 등 데이터 부정확을 방지하고자할 때 사용됨
트랜잭션의 네 가지 성질, ACID
- Atomicity (원자성)
트랜잭션의 작업이 부분적으로만 실행되거나, 중간에 수행이 멈추지 않는 것을 보장한다는 성질. (All or Nothing)
- Consistency (일관성)
트랜잭션이 성공적으로 완료되면 일관적인 DB상태를 유지하는 것. 데이터의 상태가 중간 과정에서 변질되지 않는 것.
- Isolation (고립성)
트랜잭션 수행 시, 다른 트랜잭션 작업이 끼어들지 못하도록 보장하는 것.
트랜잭션끼리는 서로 간섭할 수 없다.
- Durablity (지속성)
성공한 트랜잭션이 영원히 반영되어야 함을 의미.
NoSQL (비관계형 데이터베이스 시스템)
NoSQL의 경우 RDBMS와 다르게 비관계형 데이터베이스 저장 시 주로 사용됨
관계 설정에 따른 테이블 모델인 Schema는 의미가 없기 때문에 데이터를 저장하기 전의 정형화 과정이 필요 없다. 즉, 어디에 어떻게 데이터 저장할 것인지 먼저 생각할 필요 없다
--> 정형화할 시간이 부족하거나 빠른 데이터 저장이 필요할 때 사용하는 것.
대표적으로 MongoDB, Redis, Cassandra등
SQL(RDBMS) vs. NoSQL
SQL
보다 효율적, 체계적, 안정적: Strict schema
but
테이블 미리 정의 --> 유연성 떨어지며 확장성이 떨어짐, 서버를 늘려서 하는 분산 저장 역시 쉽지 않음
--> 주로 전자상거래 정보, 은행 계좌 정보, 거래 정보에 사용
NoSQL
보다 유연 (비정형화 --> 확장성이 좋음): Flexible schema
빠르고 빅데이터 다룰 때 유리할 수 있다
but
완전성이 덜 보장하며
트랜잭션도 안될 수 있고, 비교적 불안정
--> 주로 로그 데이타에 사용
ERD (Entity Relationship Diagram)
개체간의 관계를 개념적으로 모델링한 다이어그램
Entity(개체): 현실 세계에 존재하는 사람이나 사물과 같이 구별할 수 있는 고유 개체 (--> DB로 가공 전의 것)
Attribute(속성): entity가 가지는 고유한 특성
Relationship(관계): entity 사이의 상호작용
ERD에 대한 설명
An entity-relationship diagram (ERD) is crucial to creating a good database design. It is used as a high-level logical data model, which is useful in developing a conceptual design for databases.
An entity is a real-world item or concept that exists on its own. Entities are equivalent to database tables in a relational database, with each row of the table representing an instance of that entity.
An attribute of an entity is a particular property that describes the entity.
A relationship is the association that describes the interaction between entities. Cardinality, in the context of ERD, is the number of instances of one entity that can, or must, be associated with each instance of another entity. In general, there may be one-to-one, one-to-many, or many-to-many relationships.
For example, let us consider two real-world entities, an employee and his department. An employee has attributes such as an employee number, name, department number, etc. Similarly, department number and name can be defined as attributes of a department. A department can interact with many employees, but an employee can belong to only one department, hence there can be a one-to-many relationship, defined between department and employee.
In the actual database, the employee table will have department number as a foreign key, referencing from department table, to enforce the relationship.
references:
https://myeonguni.tistory.com/210 (정규화 단계)
https://www.techopedia.com/definition/1200/entity-relationship-diagram-erd (ERD)
