무조건 해야 할 것
- Classifier Layer가 2층이다. 저번 이미지 분류 대회에서 Classifier Layer가 1개인 것이 가장 좋은 성능을 냈었는데, 이번에도 그렇지 않을까? 한번 적용해보자
- [CLS] 토큰에서 나온 값을 LSTM에 한 번 더 정제시킨 다음 Classifier Layer에 추가시키는 것은 어떨까?
- 보니까 Classifier Layer를 통과시키지 않고 그냥 LSTM에서 처리를 끝내는 Case도 존재하는 것 같다. 만약 제출 기회가 있다면 시도해보자
- 내가 봤을 때 Punctuation이 가장 좋은 성능을 내는 것은 그 부분에 집중한다 + 그 단어가 어떤 단어인지 설명해준다의 이유인 것 같다. 예를 들어, Object가 로빈슨일 경우, Punctuation을 통해 이 로빈슨이 Person이라는 것을 알려주게 된다. 또한, 이 때 활용하는 Person도 이미 Vocab에 있는 단어이기 때문에 단어 유추에 도움을 주는 것이 아닐까? 해당 부분에 집중하는 것은 이미 [SUB], [OBJ] Special Token으로 수행했으니까 한 번 Special Token 사이에 Entity Type 정보를 넣어보자
수행한 것
Classifier Layer를 1개로 적용
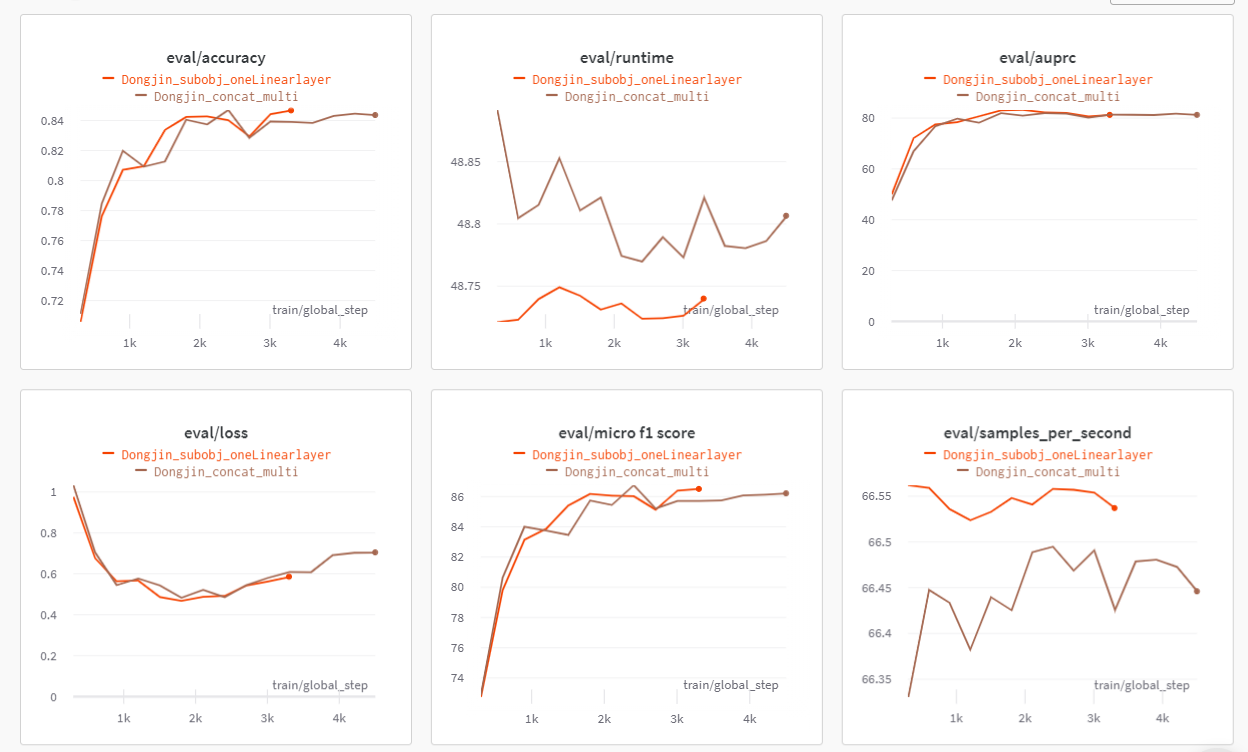
- 주황색이 Layer가 1개일 때이다.
- 그래프를 봤을 때는 더 좋아졌을 것이라고 생각했는데, 조금 떨어졌었다. 이게 Epoch을 3이 아닌 2로 주면 어떻게 될지 모르겠다.(2일때 최소 Loss를 가지기 때문)
- 하지만, 제출 횟수 제한이 있기 때문에 여기서 끝내야할 것 같다.
LSTM에 적용시켜보기
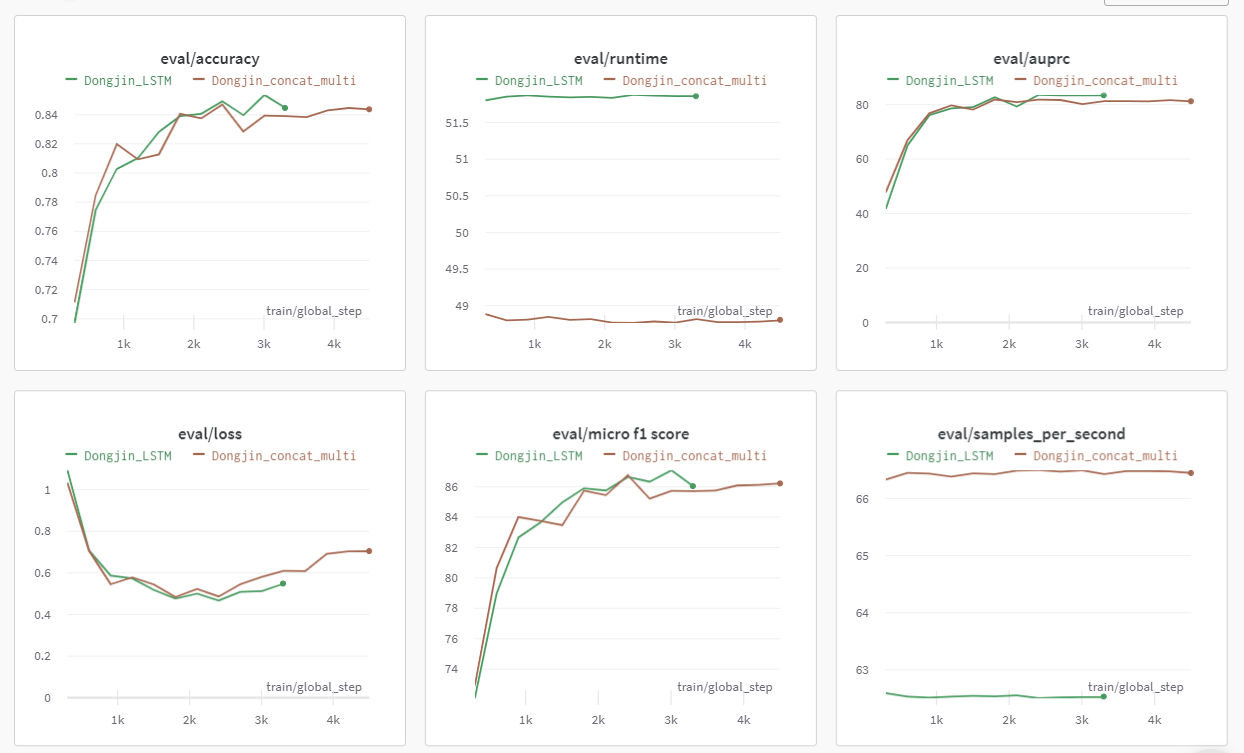
- 초록색이 LSTM을 적용시켰을 때이다. 확실히 LSTM을 적용시켰을 때 Loss 자체도 낮고 Accuracy도 높은 것 같다.
- 그런데 바보같이 이전에 잘못했던 모델을 불러와 CSV 파일을 만들어서 제출을 못하였다. 진짜 결과물 잘 확인하자. 원격 서버는 바뀌기 이전에 조금 시간이 걸린다는 점을 인지하고 있자
- 제출을 못하니 그냥 CSV 파일 2개를 띄워놓고 예측값이 틀린 것에 대해 몇 개 비교를 수행하였다. LSTM을 활용했을 경우 틀리는 Case가 더 많아졌다. 그렇게 큰 의미가 없는 것 같아서 버리게 되었다.
문장에 [SUB]에 Punctuation(*subj_type*)을 붙이기(OBJ도 동일하게)
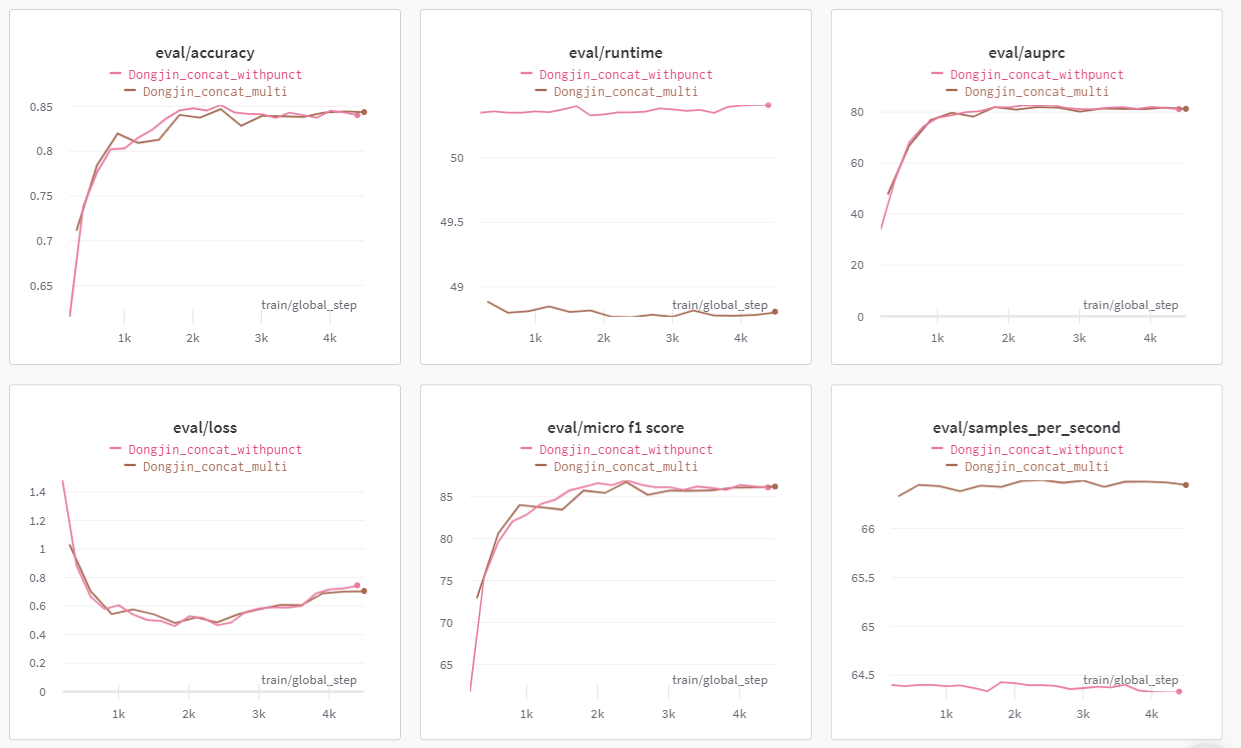
- 생각보다 괜찮은 것 같다. Loss의 경향성은 비슷한데 F1 score가 증가하는 추세도 괜찮다. 대충 결과 CSV 파일 뜯어봤을 때 결과도 괜찮았던 것 같아서 한번 제출해봐야겠다(아까운 내 실험 기회 ㅠㅠㅠ)
- 생각보다... 진짜로 많이 좋아졌다. 거의 1.2점? 정도가 오른 것 같다. 드디어 효과 있는 방법을 찾은 것 같아 매우 감격적이다 ㅠㅠㅠㅠㅠㅠㅠㅠ
내일 해야 할 것
- KoBERT 모델을 활용해달라는 부탁이 있었다(앙상블용) 그래서 한 번 KoBERT 모델을 활용해봐야겠다
- 이제 족쇄라고 생각했던 AMP를 학습 떄 풀어봐야겠다. 이게 성능이 오히려 떨어진다는 말이 있긴 한데 그래도 한 번 해봐야겠다
- 앙상블 코드를 지금까지는 활용 안했는데, 이제는 한 번 활용해 봐야할 것 같다

개념부터 확실히!