스트림 (Stream)
함수형 프로그래밍
함수형 프로그래밍의 특징
-
수학적 함수의 계산을 통해 자료를 처리하고 상태와 가변 데이터를 멀리하는 프로그래밍 패러다임
-
Java 8부터 Optional과 람다식과 같은 함수형 프로그래밍과 비동기 논블로킹의 기능 도입
- 비동기 논블로킹
- A 함수가 B 함수를 호출할 경우 A 함수는 그대로 실행이되고 B 함수 실행 완료가 되면 콜백함수를 전달하는 형태
- A 함수가 B 함수가 제대로 끝났는지 유무는 신경쓰지 않음
- ex) 사용자 이벤트 처리, 네트워크 응답 처리, 파일 입출력
- 비동기 논블로킹
-
병렬 처리, 이벤트 지향 프로그래밍에 적합
함수형 프로그래밍이 주목받기 시작한 이유
-
2000년대 초반까지는 CPU 클럭 증가, 실행 시간 최적화, Cache 크기 증가를 통해 소프트웨어의 싱글 프로세스, 싱글 스레드의 속도가 공짜로 증가했다. 하지만 전력 소모 및 발열 문제 등으로 단일코어를 통한 CPU 클럭 증가는 현실적으로 향상시키기 어려워졌다.
-
이를 대안으로 코어 수를 늘려서 CPU 의 성능을 향상시키는 방법이 등장했다. 여기서 동시에 제대로 기능을 수행하는 동시성의 개념이 중요해졌고, 절차 기반 언어의 동시성은 주어진 순간에 상태가 변경될 수 있으나 함수형 프로그래밍은 동시성을 통해 CPU 모든 코어를 활용할 수 있다는 특징 때문에 함수형 프로그래밍이 주목받기 시작했다.
함수의 순수성
- 동일한 인자를 통해 다수 호출되는 함수들은 항상 동일한 값을 반환
sum(a,b) = a+b 값을 반환하는 함수
함수를 호출하면 항상 항상 같은 값 반환
전역 변수나 임의의 종류의 활동과 같이 함수가 제어하지 않는 상태에 의존하지 않음
함수에 정의되지 않은 변수에 접근할 수 없음- 함수 실행하는 동안 side effect 존재하지 않음
- side effect : 함수 외부에 정의된 변수를 수정, 콘솔 출력, 예외 발생, 파일 입출력
- 함수 외부 어떤 종류 상태도 수정하지 않음
- 동시성 프로그래밍이나 다중 스레드에 안전
변수의 불변
- 초기화된 변수를 수정할 수 없음
- 새 변수를 잘 만들 수 있지만 기존 변수를 수정할 수는 없음
- 프로그램 실행 시간 동안 상태를 유지하는 데 도움
- 변수를 만들고 값을 설정하면 해당 변수의 값이 절대 변경되지 않을 것이라는 확신을 가질 수 있음
스트림 (Steram)
정의
- 컬렉션이나 배열의 원소를 흐름으로 간주하는 것
저장 원소를 하나씩 참조해서 람다식으로 처리할 수 있도록 해주는 내부 반복자
- 컬렉션 내부에서 요소를 반복시키고 개발자는 요소당 처리할 코드만 제공되는 코드 패턴
- 객체를 통해
무엇을 할 것인지를 중심적으로 생각 - 이미 함수가 구현되어있음
- 어떻게 요소를 반복시킬 것 인가는 컬렉션에 맡겨두고 개발자는 요소처리 코드만 집중적으로 구현 가능
- 외부 반복자보다 효율적으로 요소 반복 가능
// 스트림을 이용해서 짝수만 출력
integerList.stream()
.mapToInt(i -> i)
.filter(i -> i % 2 == 0)
.forEach(i -> System.out.print(i + ", "));외부 반복자
for, while, Iterator등을 통해 각 요소를 접근하고 원하는 데이터만 추출하여 출력 및 반환- 개발자가 코드로 직접 컬렉션 요소를 반복해서 가져오는 코드 패턴
- 자칫하면 코드가 복잡해질 수 있음
어떻게할 것인지를 중심적으로 생각- 직접 함수를 구현해야하는 경우가 많음
스트림의 종류
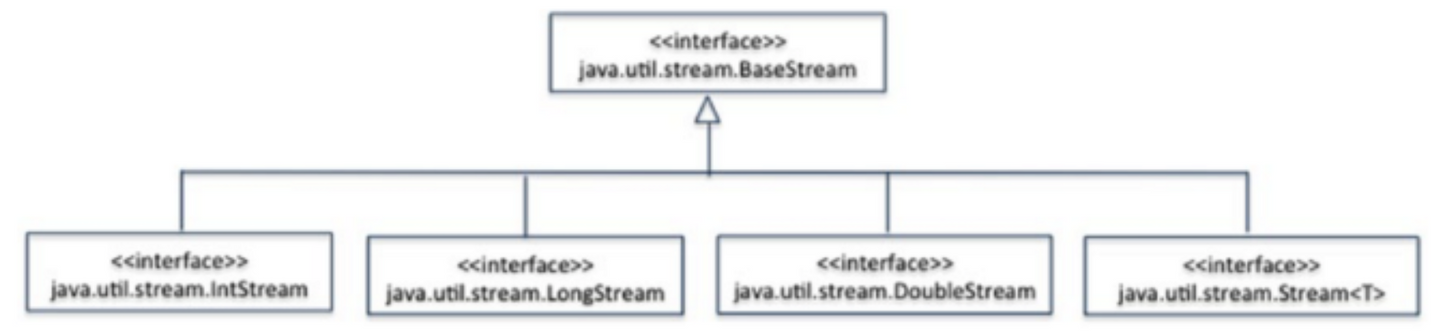
| 리턴타입 | 메소드 (매개변수) | 소스 |
|---|---|---|
| Stream | java.util.Collection.stream(), | 컬렉션 |
| java.util.Collection.parallelStream() | 컬렉션 | |
| Stream | Arrays.stream(T[]), Stream.of(T[]) | 배열 |
| IntStream | Arrays.stream(int[]), IntStream.of(int[]) | 배열 |
| LongStream | Arrays.stream(long[]), LongStream.of(long[]) | 배열 |
| DoubleStream | Arrays.stream(double[]), DoubleStream.of(double[]) | 배열 |
| IntStream | IntStream.range(int, int) | int 범위 |
| IntStream.rangeClosed(int, int) | int 범위 | |
| LongStream | LongStream.range(long, long) | long 범위 |
| LongStream.rangeClosed(long, long) | long 범위 | |
| Stream | Files.find(Path, int, BiPredicate, FileVisitOption) | 디렉토리 |
| Files.list(Path) | 디렉토리 | |
| Stream | Files.lines(Path, Charset) | 파일 |
| BufferedReader.lines() | 파일 | |
| DoubleStream | Random.doubles(…) | 랜덤 수 |
| IntStream | Random.ints(…) | 랜덤 수 |
| LongStream | Random.longs(…) | 랜덤 수 |
스트림 파이프라인
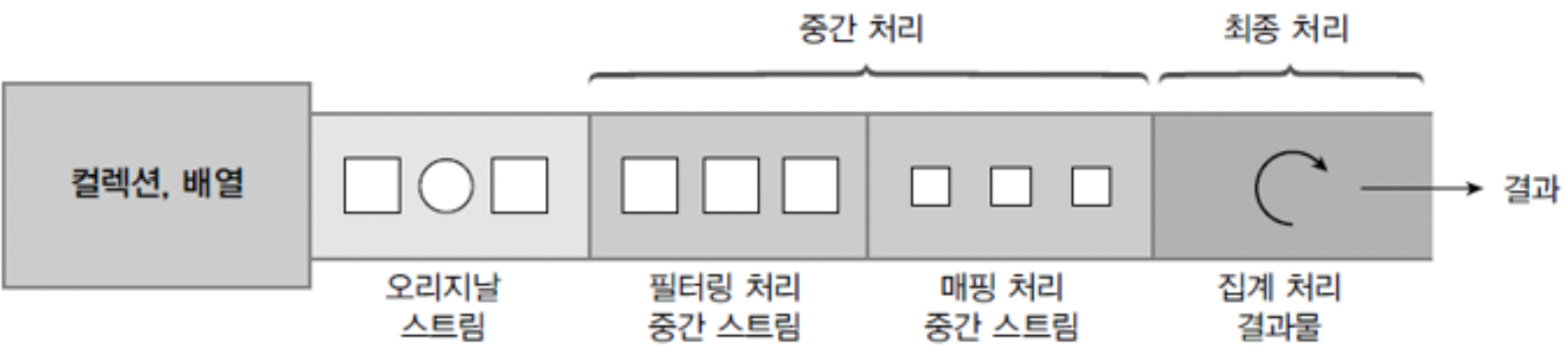
- 여러 개의 스트림이 연결된 구조 컬렉션/배열.스트림얻기().중간스트림().중간스트림().최종처리()
- 대량의 데이터를 가공해서 축소하는 것을 리덕션
reduction이라고 함 - 데이터
합계, 평균값, 카운팅, 최대값, 최소값 등이 대표적인 리덕션 결과물 - 컬렉션의 요소를 리덕션의 결과물로 바로 집계할 수 없을 경우에는 집계하기 좋도록
필터링, 매핑, 정렬, 그룹핑등의 필요함 - 중간 스트림이 생성될 때 요소들이 바로 중간 처리
필터링, 매핑, 정렬이 되는 것이 아니라 최종 처리 시작되기 전까지 중간 처리는 지연lazy되었다가 최종 처리가 시작하면 컬렉션 요소가 하나씩 중간 스트림에서 처리되고 최종 처리까지 오게 됨
중간 처리 스트림
- 반환값이 스트림 형태
- 필터링 / 중복제거
filter, distinct - 매핑
flatMapXXX, mapXXX, asDoubleStream(), asLongStream, boxed() - 정렬
sorted - 중간 결과물 반복
peek
최종 처리 스트림
- 반환값이 기본타입이거나
OptionalXXX - 매칭
allMatch, anyMatch, noneMatch - 기본집계
count, max, min, average, sum, findFirst - 커스텀 집계
reduce - 수집
collect - 최종 결과물 반복
forEach

github : https://github.com/kiaeh2323 , email : kiaeh9269@gmail.com