
학습 내용
-
시각화 라이브러리, Seaborn
-
스크래핑 결과 시각화하기 1
-
스크래핑 결과 시각화하기 2
-
뭉게뭉게 단어구름, Wordcloud
-
워드클라우드 만들기
1. 시각화 라이브러리, Seaborn
-
matplotlib을 기반으로 하는 시각화 라이브러리
-
다양한 그래프를 고수준(high-level)에서 쉽게 그릴 수 있음
-
pip3 install seaborn
-
꺾은선 그래프(Line Plot)
seaborn.lineplot(x = [1, 3, 2, 4], y = [0.7, 0.2, 0.1, 0.05])
- x, y를 명시하는 것이 좋음
- 막대 그래프(Bar Plot)
seaborn.barplot(x = [1, 3, 2, 4], y = [0.7, 0.2, 0.1, 0.05])
-
matplotlib.pyplot의 속성을 변경해 그래프에 다양한 요소 추가/변경 가능
-
pyplot.title(): 그래프에 제목 추가 -
pyplot.show(): 그래프 출력import seaborn as sns import matplotlib.pyplot as plt sns.barplot(x = [1, 3, 2, 4], y = [0.7, 0.2, 0.1, 0.05]) plt.title("Bar Plot") plt.show()
-
plt._label(): 그래프 축에 설명 추가
sns.barplot(x = [1, 3, 2, 4], y = [0.7, 0.2, 0.1, 0.05]) plt.xlabel("X Label") plt.ylabel("Y Label") plt.show()
-
plt._lim(): 그래프 축의 범위를 지정
sns.lineplot(x = [1, 3, 2, 4], y = [4, 3, 2, 1]) plt.ylim(2, 3) plt.show()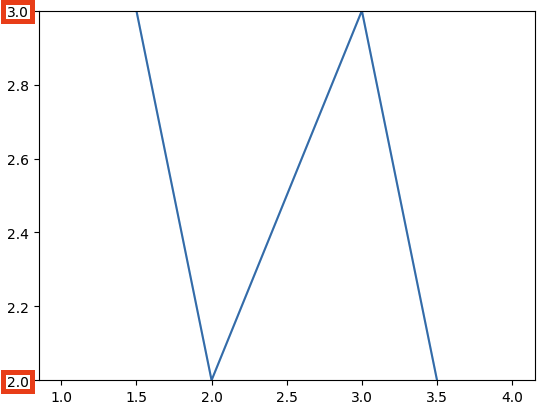
-
plt.figure(figuresize = (x, y)): 그래프의 크기 지정
plt.figure(figsize = (20, 10)) sns.lineplot(x = [1, 3, 2, 4], y = [4, 3, 2, 1]) plt.show()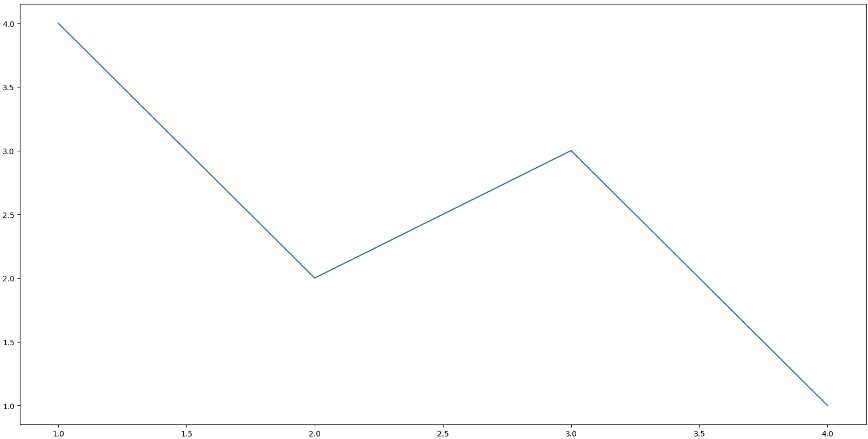
-
2. 스크래핑 결과 시각화하기 1
-
사용할 사이트: https://www.weather.go.kr/w/weather/forecast/short-term.do
-
스크래핑
from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By from webdriver_manager.chrome import ChromeDriverManager driver = webdriver.Chrome(service = Service(ChromeDriverManager().install())) driver.get("https://www.weather.go.kr/w/weather/forecast/short-term.do") driver.implicitly_wait(1) # 원하는 정보가 있는 요소를 가져온 뒤 데이터 전처리 temps = driver.find_element(By.ID, "my-tchart").text temps = [int(ele) for ele in temps.replace("℃", "").split("\n")]
-
시각화
import seaborn as sns import matplotlib.pyplot as plt # y축 범위 지정 plt.ylim(min(temps) - 2, max(temps) + 2) # 제목 지정 plt.title("Expected Temperature from now on") # x축: Elapesed Time(경과시간) # y축: 기온 sns.lineplot( x = [time for time in range(len(temps))], y = temps ) plt.show()
3. 스크래핑 결과 시각화하기 2
-
사용할 사이트: https://hashcode.co.kr/
-
스크래핑
import requests from bs4 import BeautifulSoup import time user_agent = {"User-Agent": "XXX"} # 질문 키워드 빈도 frequency = {} for i in range(1, 11): res = requests.get("https://hashcode.co.kr/?page={}".format(i), user_agent) soup = BeautifulSoup(res.text, "html.parser") ul_tags = soup.find_all("ul", "question-tags") for ul in ul_tags: li_tags = ul.find_all("li") for li in li_tags: tag = li.text.strip() if tag not in frequency: frequency[tag] = 1 else: frequency[tag] += 1 time.sleep(0.5)
-
시각화
import seaborn as sns import matplotlib.pyplot as plt from collections import Counter plt.figure(figsize = (20, 10)) plt.title("frequency of questions in hashcode") plt.xlabel("Tag") plt.ylabel("Frequency") # Counter를 사용해 가장 빈도가 높은 value 10개 추출 counter = Counter(frequency) # x: 키워드 / y: 키워드의 빈도수 x = [ele[0] for ele in counter.most_common(10)] y = [ele[1] for ele in counter.most_common(10)] sns.barplot(x = x, y = y) plt.show()
4. 뭉게뭉게 단어구름, Wordcloud
-
자주 등장하는 텍스트를 중요도나 인기도를 고려해 표현한 것
-
만들기 위한 과정
- 자연어 문장에서 키워드 추출
- 키워드 등장한 빈도 측정
- 앞에서 전처리한 정보와 Wordcloud 라이브러리를 바탕으로 Wordcloud 생성
- 자연어 문장에서 키워드 추출
-
pip3 install wordcloud-
에러 발생:
Could not build wheels for wordcloud, which is required to install pyproject.toml-based projects-
Anaconda 설치해 가상환경 생성 후 Python 3.9 버전으로 다운그레이드해서 해결
-
conda install -c conda-forge wordcloud
-
-
-
pip3 install konlpy
-
한국어 형태소 분석기 라이브러리
-
에러 발생:
Could not build wheels for lxml, which is required to install pyproject.toml-based projects- 기존 JDK를 Zulu JDK로 변경 후 명령어 재실행해서 해결
- 기존 JDK를 Zulu JDK로 변경 후 명령어 재실행해서 해결
-
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from collections import Counter
from konlpy.tag import Hannanum
# Wordcloud를 만드는 데 사용할 애국가 가사
national_anthem = """
동해물과 백두산이 마르고 닳도록
하느님이 보우하사 우리나라 만세
무궁화 삼천리 화려 강산
대한 사람 대한으로 길이 보전하세
남산 위에 저 소나무 철갑을 두른 듯
바람 서리 불변함은 우리 기상일세
무궁화 삼천리 화려 강산
대한 사람 대한으로 길이 보전하세
가을 하늘 공활한데 높고 구름 없이
밝은 달은 우리 가슴 일편단심일세
무궁화 삼천리 화려 강산
대한 사람 대한으로 길이 보전하세
이 기상과 이 맘으로 충성을 다하여
괴로우나 즐거우나 나라 사랑하세
무궁화 삼천리 화려 강산
대한 사람 대한으로 길이 보전하세
"""
# Hannanum 객체를 생성한 후, .nouns() 메서드를 사용해 명사 추출
hannanum = Hannanum()
nouns = hannanum.nouns(national_anthem)
# Counter를 사용해 각 단어의 개수 카운드
counter = Counter(nouns)
# WordCloud 객체 생성 후 로컬 환경에 있는 한국어 폰트 추가
wordcloud = WordCloud(
font_path = "/Users/XXX/Library/Fonts/NotoSansKR-Medium.otf",
background_color = "white",
width = 1000,
height = 1000,
)
img = wordcloud.generate_from_frequencies(counter)
plt.imshow(img)
5. 워드클라우드 만들기
-
사용할 사이트: https://hashcode.co.kr/
-
스크래핑
import time import requests from bs4 import BeautifulSoup user_agent = {"User-Agent": "XXX"} questions = [] for i in range(1, 6): res = requests.get("https://hashcode.co.kr/?page={}".format(i), user_agent) soup = BeautifulSoup(res.text, "html.parser") parsed_datum = soup.find_all("li", "question-list-item") for data in parsed_datum: questions.append(data.h4.text.strip()) time.sleep(0.5)
-
시각화
import matplotlib.pyplot as plt from wordcloud import WordCloud from collections import Counter from konlpy.tag import Hannanum words = [] hannanum = Hannanum() for question in questions: words += hannanum.nouns(question) # 리스트를 인자로 Counter를 생성하면 딕셔너리 형태로 반환됨 counter = Counter(words) wordcloud = WordCloud( font_path = "/Users/XXX/Library/Fonts/NotoSansKR-Medium.otf", background_color = "white", width = 1000, height = 1000 ) img = wordcloud.generate_from_frequencies(counter) plt.imshow(img)

메모
- BeautifulSoup.find() 메서드는 찾는 요소가 없을 경우 에러가 발생할 수 있음
- BeautifulSoup.find_all() 메서드로 대체 가능
- BeautifulSoup.find_all() 메서드로 대체 가능
- plt.figure(figsize = (x, y)) 메서드가 plt.title(), plt._label(), sns._plot() 등의 다른 메서드보다 먼저 와야 함
