AWS Cloud Practitioner Essentials - 모듈5
모듈 5
- 스토리지 및 데이터베이스의 기본 개념을 요약할 수 있습니다.
- Amazon Elastic Block Store(Amazon EBS)의 이점을 설명할 수 있습니다.
- Amazon Simple Storage Solution(Amazon S3)의 이점을 설명할 수 있습니다.
- Amazon Elastic File System(Amazon EFS)의 이점을 설명할 수 있습니다.
- 다양한 스토리지 솔루션을 요약할 수 있습니다.
- Amazon Relational Database Service(RDS)의 이점을 설명할 수 있습니다.
- Amazon DynamoDB의 이점을 설명할 수 있습니다.
- 다양한 데이터베이스 서비스를 요약할 수 있습니다.
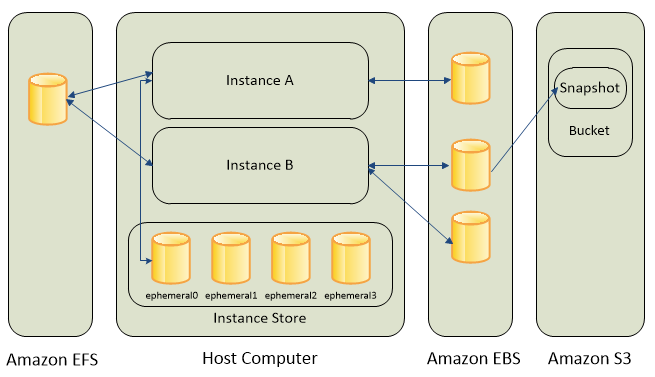
인스턴스 스토어
블록 수준 스토리지 볼륨은 물리적 하드 드라이브처럼 동작합니다.
인스턴스 스토어는 Amazon EC2 인스턴스에 임시 블록 수준 스토리지를 제공합니다. 인스턴스 스토어는 물리적으로 EC2 인스턴스의 호스트 컴퓨터에 연결되어 있고, 따라서 인스턴스와 수명이 동일한 디스크 스토리지입니다. 인스턴스가 종료되면 인스턴스 스토어의 데이터가 손실됩니다.
Amazon Elastic Block Store(Amazon EBS)는 Amazon EC2 인스턴스에서 사용할 수 있는 블록 수준 스토리지 볼륨을 제공하는 서비스입니다. Amazon EC2 인스턴스를 중지 또는 종료하더라도 연결된 EBS 볼륨의 모든 데이터를 사용할 수 있습니다.
EBS 볼륨을 생성하려면 구성(예: 볼륨 크기 및 유형)을 정의하고 볼륨을 프로비저닝합니다. EBS 볼륨을 생성한 다음 볼륨을 Amazon EC2 인스턴스에 연결할 수 있습니다.
EBS 볼륨은 보존해야 하는 데이터를 위한 것이므로 데이터 백업이 중요합니다. Amazon EBS 스냅샷을 생성하여 EBS 볼륨을 증분 백업할 수 있습니다.
Amazon EBS 스냅샷
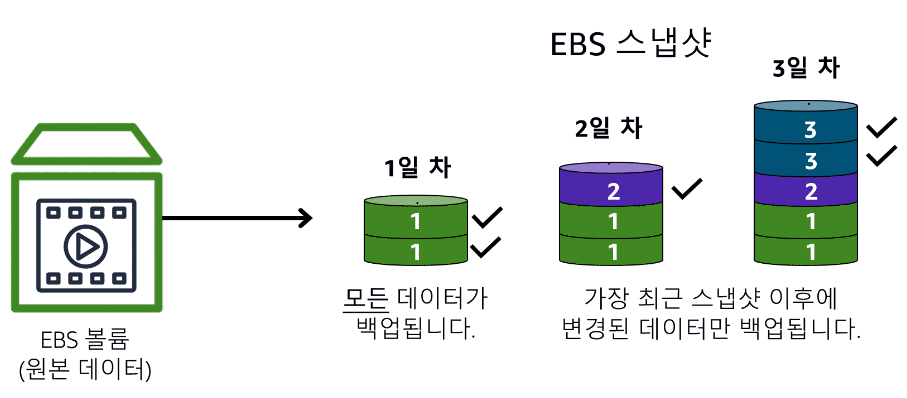
EBS 스냅샷은 증분 백업입니다. 즉, 처음 볼륨을 백업하면 모든 데이터가 복사됩니다. 이후의 백업에서는 가장 최근의 스냅샷 이후 변경된 데이터 블록만 저장됩니다.
증분 백업은 백업이 실행될 때마다 스토리지 볼륨의 모든 데이터가 복사되는 전체 백업과는 다릅니다. 전체 백업에는 가장 최근의 백업 이후 변경되지 않은 데이터도 포함됩니다.
객체 스토리지
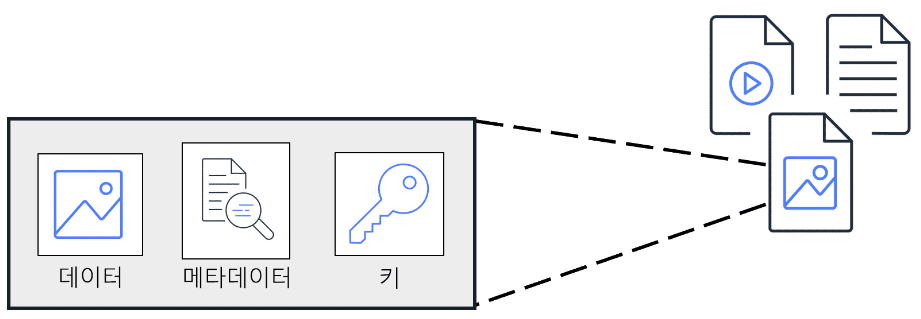
객체 스토리지에서 각 객체는 데이터, 메타데이터, 키로 구성됩니다.
데이터는 이미지, 동영상, 텍스트 문서 또는 기타 유형의 파일일 수 있습니다. 메타데이터에는 데이터의 내용, 사용 방법, 객체 크기 등에 대한 정보가 포함되어 있습니다. 객체의 키는 고유한 식별자입니다.
기억하다시피 블록 스토리지에서 파일을 수정하면 변경된 부분만 업데이트됩니다. 객체 스토리지에서 파일을 수정하면 전체 개체가 업데이트됩니다.
Amazon Simple Storage Service(Amazon S3)
Amazon Simple Storage Service(Amazon S3)는 객체 수준 스토리지를 제공하는 서비스입니다. Amazon S3는 데이터를 버킷에 객체로 저장합니다.
Amazon S3에는 이미지, 동영상, 텍스트 파일 등 모든 유형의 파일을 업로드할 수 있습니다. 예를 들어 Amazon S3를 사용하여 백업 파일, 웹 사이트용 미디어 파일 또는 보관된 문서를 저장할 수 있습니다. Amazon S3는 저장 공간을 무제한으로 제공합니다. Amazon S3에 저장할 수 있는 객체의 최대 파일 크기는 5TB입니다.
Amazon S3에 파일을 업로드할 때 권한을 설정하여 파일에 대한 표시 여부 및 액세스를 제어할 수 있습니다. Amazon S3 버전 관리 기능을 사용하여 시간 경과에 따른 객체 변경 사항을 추적할 수도 있습니다.
Amazon S3 스토리지 클래스
Amazon S3에서는 사용한 만큼만 비용을 지불합니다. 비즈니스 및 비용 요구 사항에 맞춰 다양한 스토리지 클래스 중에서 선택할 수 있습니다. Amazon S3 스토리지 클래스를 선택할 때 다음 두 가지 요소를 고려해야 합니다.
- 데이터를 검색할 빈도
- 필요한 데이터 가용성
S3 Standard
- 자주 액세스하는 데이터용으로 설계
- 최소 3개의 가용 영역에 데이터를 저장
S3 Standard는 객체에 대한 고가용성을 제공합니다. 따라서 웹 사이트, 콘텐츠 배포, 데이터 분석 등 광범위한 사용 사례에 적합합니다. S3 Standard는 자주 액세스하지 않는 데이터 및 보관 스토리지를 위한 다른 스토리지 클래스보다 비용이 높습니다.
S3 Standard-Infrequent Access(S3 Standard-IA)
- 자주 액세스하지 않는 데이터에 이상적
- S3 Standard와 비슷하지만 스토리지 가격은 더 저렴하고 검색 가격은 더 높음
S3 Standard-IA는 자주 액세스하지 않지만 필요에 따라 고가용성이 요구되는 데이터에 이상적입니다. S3 Standard 및 S3 Standard-IA는 모두 최소 3개의 가용 영역에 데이터를 저장합니다. S3 Standard-IA는 S3 Standard와 동일한 수준의 가용성을 제공하지만 스토리지 가격은 더 저렴하고 검색 가격은 더 높습니다.
S3 One Zone-Infrequent Access(S3 One Zone-IA)
- 단일 가용 영역에 데이터를 저장
- S3 Standard-IA보다 낮은 스토리지 가격
최소 3개의 가용 영역에 데이터를 저장하는 S3 Standard 및 S3 Standard-IA와 달리, S3 One Zone-IA는 단일 가용 영역에 데이터를 저장합니다. 따라서 다음과 같은 조건이 적용되는 경우 고려할 수 있는 훌륭한 스토리지 클래스입니다- 스토리지 비용을 절감하려는 경우
- 가용 영역 장애가 발생할 경우 데이터를 손쉽게 재현할 수 있는 경우
S3 Intelligent-Tiering
- 액세스 패턴을 알 수 없거나 자주 변화하는 데이터에 이상적
- 객체당 소량의 월별 모니터링 및 자동화 요금을 부과
S3 Intelligent-Tiering 스토리지 클래스에서는 Amazon S3가 객체의 액세스 패턴을 모니터링합니다. 사용자가 30일 연속 객체에 액세스하지 않으면 Amazon S3는 자동으로 해당 객체를 자주 사용하지 않는 액세스 계층인 S3 Standard-IA로 이동합니다. 사용자가 자주 사용하지 않는 액세스 계층에 저장된 객체에 액세스하면 Amazon S3는 자동으로 해당 객체를 자주 사용하는 액세스 계층인 S3 Standard로 이동합니다.
S3 Glacier
- 데이터 보관용으로 설계된 저비용 스토리지
- 객체를 몇 분에서 몇 시간 이내에 검색
S3 Glacier는 데이터 보관에 이상적인 저비용 스토리지 클래스입니다. 예를 들어 이 스토리지 클래스를 사용하여 보관된 고객 레코드나 이전 사진 또는 비디오 파일을 저장할 수 있습니다.
S3 Glacier Deep Archive
- 보관에 이상적인 가장 저렴한 객체 스토리지 클래스
- 객체를 12시간 이내에 검색
Amazon S3 Glacier와 Amazon S3 Glacier Deep Archive 간에 결정할 때 보관된 객체를 얼마나 빨리 검색해야 하는지를 고려해야 합니다. S3 Glacier 스토리지 클래스에 저장된 객체는 몇 분에서 몇 시간 이내에 검색할 수 있습니다. 이에 비해 S3 Glacier Deep Archive 스토리지 클래스에 저장된 객체는 12시간 이내에 검색할 수 있습니다.
파일 스토리지
파일 스토리지에서는 여러 클라이언트(예: 사용자, 애플리케이션, 서버 등)가 공유 파일 폴더에 저장된 데이터에 액세스할 수 있습니다. 이 접근 방식에서는 스토리지 서버가 블록 스토리지를 로컬 파일 시스템과 함께 사용하여 파일을 구성합니다. 클라이언트는 파일 경로를 통해 데이터에 액세스합니다.
블록 스토리지 및 객체 스토리지와 비교하면, 파일 스토리지는 많은 수의 서비스 및 리소스가 동시에 동일한 데이터에 액세스해야 하는 사용 사례에 이상적입니다.
Amazon Elastic File System(Amazon EFS)은 AWS 클라우드 서비스 및 온프레미스 리소스와 함께 사용되는 확장 가능한 파일 시스템입니다. 파일을 추가 또는 제거하면 Amazon EFS가 자동으로 확장하거나 축소됩니다. 애플리케이션을 중단하지 않고 온디맨드로 페타바이트 규모로 확장할 수 있습니다.
Amazon EBS와 Amazon EFS 비교

관계형 데이터베이스
관계형 데이터베이스에서는 데이터가 다른 데이터 부분과 관련된 방식으로 저장됩니다.
관계형 데이터베이스의 예로 커피숍의 인벤토리 관리 시스템을 들 수 있습니다. 데이터베이스의 각 레코드에는 제품 이름, 크기, 가격 등 단일 항목에 대한 데이터가 포함됩니다.
관계형 데이터베이스는 정형 쿼리 언어(SQL)를 사용하여 데이터를 저장하고 쿼리합니다. 이러한 접근 방식은 데이터를 쉽게 이해할 수 있고 일관되며 확장 가능한 방식으로 저장할 수 있습니다. 예를 들어 커피숍 점주는 가장 자주 구입하는 음료가 미디엄 라떼인 모든 고객을 식별하기 위해 SQL 쿼리를 작성할 수 있습니다.
관계형 데이터베이스 내의 데이터 예:

Amazon Relational Database Service
Amazon Relational Database Service(Amazon RDS)는 AWS 클라우드에서 관계형 데이터베이스를 실행할 수 있는 서비스입니다.
Amazon RDS는 하드웨어 프로비저닝, 데이터베이스 설정, 패치 적용 백업과 같은 작업을 자동화하는 관리형 서비스입니다. 이러한 기능을 사용하면 관리 작업을 수행하는 데 드는 시간을 줄이고 데이터를 사용하여 애플리케이션을 혁신하는 데 더 많은 시간을 할애할 수 있습니다. Amazon RDS를 다른 서비스와 통합하면 AWS Lambda를 사용하여 서버리스 애플리케이션에서 데이터베이스를 쿼리하는 등 비즈니스 및 운영 요구 사항을 충족할 수 있습니다.
Amazon RDS는 다양한 보안 옵션을 제공합니다. 대부분의 Amazon RDS 데이터베이스 엔진이 저장 시 암호화(데이터가 저장되는 동안 데이터를 보호) 및 전송 중 암호화(데이터를 전송 및 수신하는 동안 데이터를 보호)를 제공합니다.
Amazon RDS 데이터베이스 엔진
Amazon RDS는 메모리, 성능 또는 입/출력(I/O)에 최적화된 6개의 데이터베이스 엔진에서 사용할 수 있습니다. 지원되는 데이터베이스 엔진은 다음과 같습니다.
- Amazon Aurora
- PostgreSQL
- MySQL
- MariaDB
- Oracle Database
- Microsoft SQL Server
비관계형 데이터베이스
비관계형 데이터베이스에서는 테이블을 생성합니다. 테이블은 데이터를 저장하고 쿼리할 수 있는 장소입니다.
비관계형 데이터베이스는 행과 열이 아닌 구조를 사용하여 데이터를 구성하기 때문에 ‘NoSQL 데이터베이스’라고도 합니다. 비관계형 데이터베이스의 구조적 접근 방식 중 한 유형은 키-값 페어입니다. 키-값 페어에서는 데이터가 항목(키)으로 구성되고 항목은 속성(값)을 갖습니다. 속성을 데이터의 여러 기능으로 생각할 수 있습니다.
키-값 데이터베이스에서는 언제든지 테이블의 항목에서 속성을 추가하거나 제거할 수 있습니다. 또한 테이블의 모든 항목에 동일한 속성이 있어야 하는 것은 아닙니다.
비관계형 데이터베이스 내 데이터의 예:

Amazon DynamoDB
Amazon DynamoDB는 키-값 데이터베이스 서비스입니다. 모든 규모에서 한 자릿수 밀리초의 성능을 제공합니다.

Amazon Redshift
Amazon Redshift는 빅 데이터 분석에 사용할 수 있는 데이터 웨어하우징 서비스입니다. 이 서비스는 여러 원본에서 데이터를 수집하여 데이터 간의 관계 및 추세를 파악하는 데 도움이 되는 기능을 제공합니다.
AWS Database Migration Service(AWS DMS)
AWS Database Migration Service(AWS DMS)는 관계형 데이터베이스, 비관계형 데이터베이스 및 기타 유형의 데이터 저장소를 마이그레이션할 수 있는 서비스입니다.
AWS DMS를 사용하면 원본 데이터베이스와 대상 데이터베이스 간에 데이터를 이동할 수 있습니다. 원본 데이터베이스와 대상 데이터베이스는 유형이 동일할 필요가 없습니다. 마이그레이션하는 동안 원본 데이터베이스가 계속 작동하므로 데이터베이스를 사용하는 애플리케이션의 가동 중지 시간을 줄일 수 있습니다.
예를 들어 온프레미스에서 Amazon EC2 인스턴스 또는 Amazon RDS에 저장된 MySQL 데이터베이스가 있다고 가정해 보겠습니다. MySQL 데이터베이스가 원본 데이터베이스라고 하겠습니다. AWS DMS를 사용하여 Amazon Aurora 데이터베이스와 같은 대상 데이터베이스로 데이터를 마이그레이션할 수 있습니다.
AWS DMS의 다른 사용 사례
추가 데이터베이스 서비스
Amazon DocumentDB
Amazon DocumentDB는 MongoDB 워크로드를 지원하는 문서 데이터베이스 서비스입니다.
(MongoDB는 문서 데이터베이스 프로그램입니다.)
Amazon Neptune
Amazon Neptune은 그래프 데이터베이스 서비스입니다.
Amazon Neptune을 사용하여 추천 엔진, 사기 탐지, 지식 그래프와 같이 고도로 연결된 데이터 세트로 작동하는 애플리케이션을 빌드하고 실행할 수 있습니다.
Amazon Quantum Ledger Database(Amazon QLDB)
Amazon Quantum Ledger Database(Amazon QLDB)는 원장 데이터베이스 서비스입니다.
Amazon QLDB를 사용하여 애플리케이션 데이터에 발생한 모든 변경 사항의 전체 기록을 검토할 수 있습니다.
Amazon Managed Blockchain
Amazon Managed Blockchain은 오픈 소스 프레임워크를 사용하여 블록체인 네트워크를 생성하고 관리하는 데 사용할 수 있는 서비스입니다.
블록체인은 여러 당사자가 중앙 기관 없이 거래를 실행하고 데이터를 공유할 수 있는 분산형 원장 시스템입니다.
Amazon ElastiCache
Amazon ElastiCache는 자주 사용되는 요청의 읽기 시간을 향상시키기 위해 데이터베이스 위에 캐싱 계층을 추가하는 서비스입니다.
이 서비스는 두 가지 데이터 저장소 Redis 및 Memcached를 지원합니다.
Amazon DynamoDB Accelerator
Amazon DynamoDB Accelerator(DAX)는 DynamoDB용 인 메모리 캐시입니다.
응답 시간을 한 자릿수 밀리초에서 마이크로초까지 향상시킬 수 있습니다.
