Feature Scaling
서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 방법
- 표준화 : 일정 기준 안으로 (z-score)
- 정규화 : 0 ~ 1 값으로
Observation과 Feature
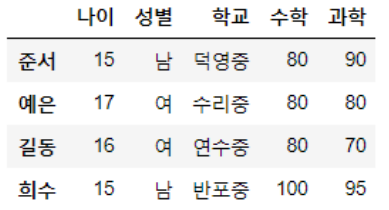
학생의 이름 정보(행, 관측대상)을 Observation이라고 하고, 관측대상들의 나이, 성별 등의 정보(열)을 Feature라고 함
표준화
평균 0, 표준편차가 1이 되도록 값을 스케일링
✔ z-score : (관측값 - 평균) / 표준편차
❗ 데이터가 가우시안 분포를 따를 때, 즉, 선형 회귀분석이나 로지스틱 회귀분석에서 사용
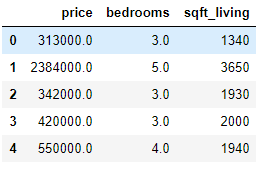
✅ 집값, 방개수, 평수 csv 파일 데이터셋 df
1. z-score을 직접 연산으로 구하기
✔ price만 구해볼까?
price_mean = df.price.mean() # 가격 평균
price_std = df.price.std() # 가격 표준편차(df.price - price_mean) / price_std0 -0.549693
1 1.779305
2 -0.517080
3 -0.429363
4 -0.283168
Name: price, dtype: float64✅ df.shape
현재 데이터 프레임의 (행, 열)수를 알려줌
df.shape(5, 3)👉 df.shape[1] : 열의 수
df.shape[1]3for i in range(df.shape[1]):
col = df.iloc[:, i] # df.iloc[:, i] : i번째 열을 의미
col = (col-col.mean())/col.std()
df.iloc[:,i] = col
df| price | bedrooms | sqft_living | |
|---|---|---|---|
| 0 | -0.549693 | -0.670820 | -0.957734 |
| 1 | 1.779305 | 1.565248 | 1.701359 |
| 2 | -0.517080 | -0.670820 | -0.278572 |
| 3 | -0.429363 | -0.670820 | -0.197993 |
| 4 | -0.283168 | 0.447214 | -0.267060 |
2. sklearn preprocessing.scale() 메서드
standardized = preprocessing.scale(df)
pd.DataFrame(standardized, columns=['price', 'bedrooms', 'sqft_living'])| price | bedrooms | sqft_living | |
|---|---|---|---|
| 0 | -0.614576 | -0.75 | -1.070779 |
| 1 | 1.989324 | 1.75 | 1.902177 |
| 2 | -0.578113 | -0.75 | -0.311453 |
| 3 | -0.480043 | -0.75 | -0.221363 |
| 4 | -0.316592 | 0.50 | -0.298583 |
정규화
값들을 특정 범위, 주로 [0,1]로 스케일링하는 것
❗ 데이터의 분포를 모르거나 가우시안 분포가 아니라는 것을 알았을 때, 즉, 최근접 이웃알고리즘(K-nearest neighbors)이나 인공신경망 같은 방법
1. MinMax Scaling x' = (x-min) / (max-min)
for i in range(df.shape[1]):
col = df.iloc[:, i]
col = (col - col.min()) / (col.max()-col.min())
df.iloc[:, i] = col
df| price | bedrooms | sqft_living | |
|---|---|---|---|
| 0 | 0.000000 | 0.0 | 0.000000 |
| 1 | 1.000000 | 1.0 | 1.000000 |
| 2 | 0.014003 | 0.0 | 0.255411 |
| 3 | 0.051666 | 0.0 | 0.285714 |
| 4 | 0.114437 | 0.5 | 0.259740 |
2. sklearn preprocessing.MinMaxScaler().fit_transform() 메서드
df = pd.read_csv('house_train.csv')
df = df.iloc[0:5, [1,2,4]]
df| price | bedrooms | sqft_living | |
|---|---|---|---|
| 0 | 313000.0 | 3.0 | 1340 |
| 1 | 2384000.0 | 5.0 | 3650 |
| 2 | 342000.0 | 3.0 | 1930 |
| 3 | 420000.0 | 3.0 | 2000 |
| 4 | 550000.0 | 4.0 | 1940 |
normalized = preprocessing.MinMaxScaler().fit_transform(df)
pd.DataFrame(normalized, columns=['price', 'bedrooms', 'sqft_living'])| price | bedrooms | sqft_living | |
|---|---|---|---|
| 0 | 0.000000 | 0.0 | 0.000000 |
| 1 | 1.000000 | 1.0 | 1.000000 |
| 2 | 0.014003 | 0.0 | 0.255411 |
| 3 | 0.051666 | 0.0 | 0.285714 |
| 4 | 0.114437 | 0.5 | 0.259740 |
차원
Observation을 표현하기 위한 Feature의 개수
👉 차원의 저주 : Feature 개수가 많아지면서 발생하는 문제
1. 차원이 증가하면 필요한 데이터 수가 지수적으로 증가
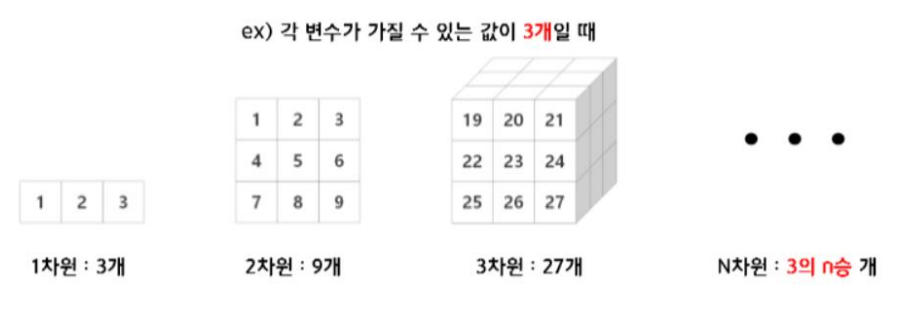
2. 차원의 저주 2



나영