본 포스팅은 Fastcampus 강의를 수강하며 일부 내용을 정리한 글임을 밝힙니다. 보다 자세한 내용은 아래 강의를 통해 확인해주세요.
참고 : Fastcampus 딥러닝을 활용한 추천시스템 구현 올인원 패키지 Online
Ch 08. Recommender System with Deep Learning
📑 Paper Review
AutoRec: AutoEncoders Meet Collaborative Filtering
AutoEncoder란
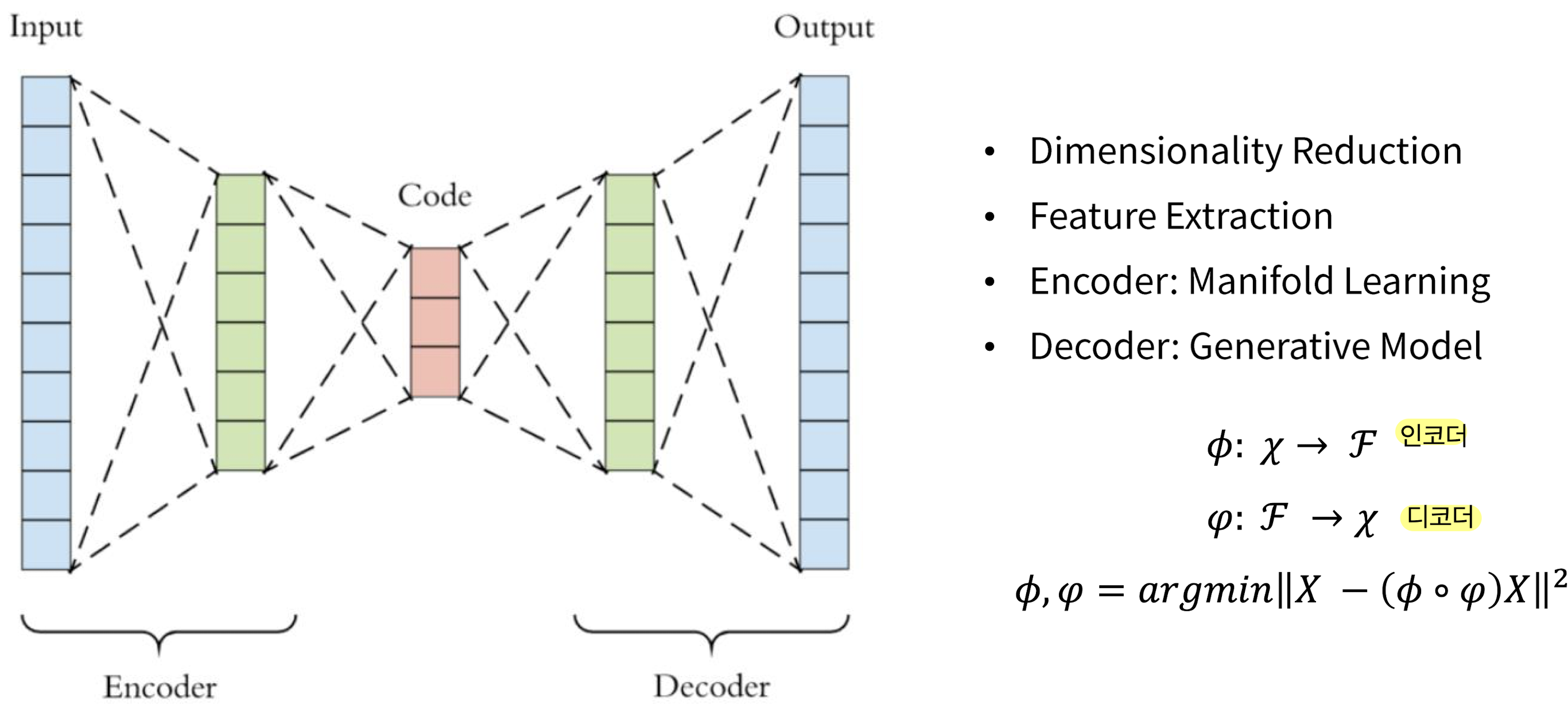
Encoder와Decoder를 통해 Input과 Output이 동일한 구조Encoder: Input에 대해 feature extraction ➡️ Manifold LearningDecoder: extracted feature를 다시 복원 ➡️ Generative Model
Manifold Learning;
고차원데이터가 있을 때 고차원 데이터를 데이터 공간에 뿌리면 샘플들을 잘 아우르는 subpsace가 있을 것이라 가정에서 학습을 진행하는 방법. 이렇게 찾은 manifold는 데이터의 차원을 축소시킬 수 있다.
-> 높은 차원에서 낮은 차원으로 변환하는 것을 임베딩이라 하며 그것에 대한 학습 과정을 Manifold Learning이라 함
- 목적: Encoder와 Decoder의 차이를 줄여나가는 과정을 학습 (즉, Input과 생성된 Output의 차이를 최소화)
AutoRec: AutoEncoders Meet Collaborative Filtering

2015 WWW Conference
- Collaborative Filtering 할 때, user based냐 item based인지에 대해 그 개념을 정확히 적용해서 input vector를 만들고, 만들어진 input vector를 autoencoder에 넣어서 학습을 하는 과정 속에서 rating을 살펴보자는 것
0. Abstract

- Autoencoder를 Collaborative Filtering에 적용한 논문
- MovieLens와 Netflix 데이터셋에 대해서 좋은 성능 입증
1. Introduction

- 최근 Vision과 Speech 분야에서 성공을 거둔 neural network를 적용한 논문
- Representation과 computation에서 모두 장점이 있음
2. The AutoRec Model
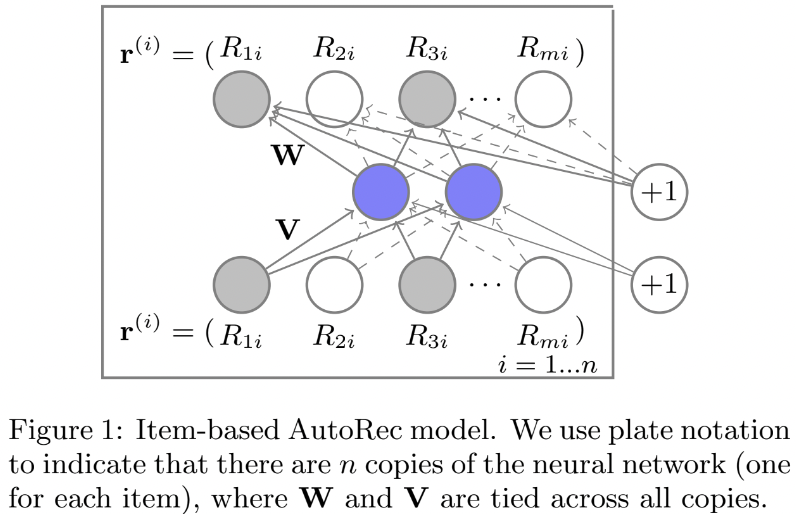
- 밑 부분이 encoder, 윗 부분이 decoder
- 중간 hidden vectore들을 통해 학습
- Collaborative Filtering ➡️ user와 item matrix 존재
- 와 가 user와 item의 rating vector

-
중요한 error term ➡️ Reconstruction error (construction을 다시 하겠다)
-
input r에 대해 다시 reconstruction을 할 때 error 값을 비교하겠다 ➡️ 즉, input과 output을 최대한 줄여나가는 과정을 하겠다
-
수식에서 첫 번째 part (Observed rating만 학습에 사용한다)
- 뒷 부분에 가 달려있는 것은 이 모델을 사용할 user들은 관측된 데이터에서만 학습을 해야한다는 것
-
수식에서 두 번째 part: Regularization term을 통해 overfitting 방지
- 각 에 대해 Backpropagation에서 observed inputs에 대해서 가중치 업데이트
-
각 파라미터가 업데이트 되는 과정에서 최종적인 Predicted Rating을 구할 수 있다
2-1. RBM-CF와의 비교
-
RBM-CF: Restricted Boltzmann Machine을 CF에 사용한 일반화된 확률 모델이지만, AutoRec은 discriminative하고
autoencoder를 활용한 모델 -
RBM-DF은 log-likelihood를 최대화하고, AutoRec은
RMSE를 최소화 -
학습할 때, RBM-CF는 대조발산(Boltzmann machine), AutoRec은 비교적 빠른
gradient-based 역전파를 사용 -
RBM-CF는 discrete rating에 적합하고 각 rating 값에 대해 파라미터를 추정하지만, AutoRec은 더 적은 parameter가 필요하고 overfitting 될 확률이 낮다
2-2. Matrix Factorization과 비교
-
MF는 linear representation이지만, AutoRec은
non-linear -
MF는 user, item 모두 latent space에 두지만, (item-based)AutoRec은 item만 embed한다.
3. Experiments
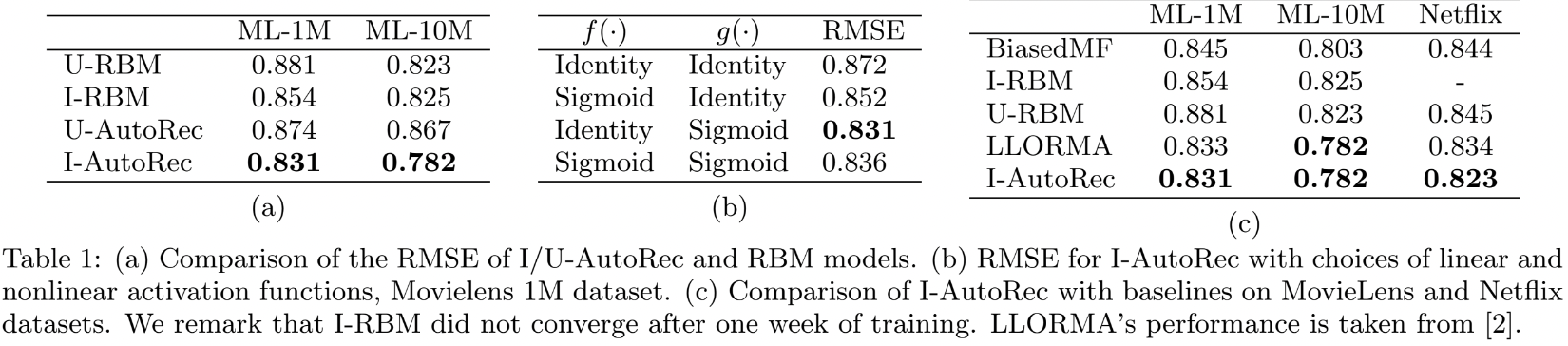
(a)
- Item-based와 User-based 비교
- Item-based가 user-based보다 더 성능이 우수
- Item 데이터가 더 많기 때문
(b)
- linear activation을 쓸 것이냐, non-linear activation을 쓸 것이냐
- Hidden layer의 non-linearity가 효과가 있다
(c)
- AutoRec이 다른 모든 baseline에 대해서 더 우수한 성능 보임
