etl pipeline을 구글 클라우드 환경에서 구축하기 위해 준비해야할 것들
- google colud cli 환경
- airflow
- google cloud 계정
전체적인 아키텍쳐
화살표 방향은 신경쓰지 말아주세요! 왼쪽에서 오른쪽으로 흐름만 보면 됩니당!
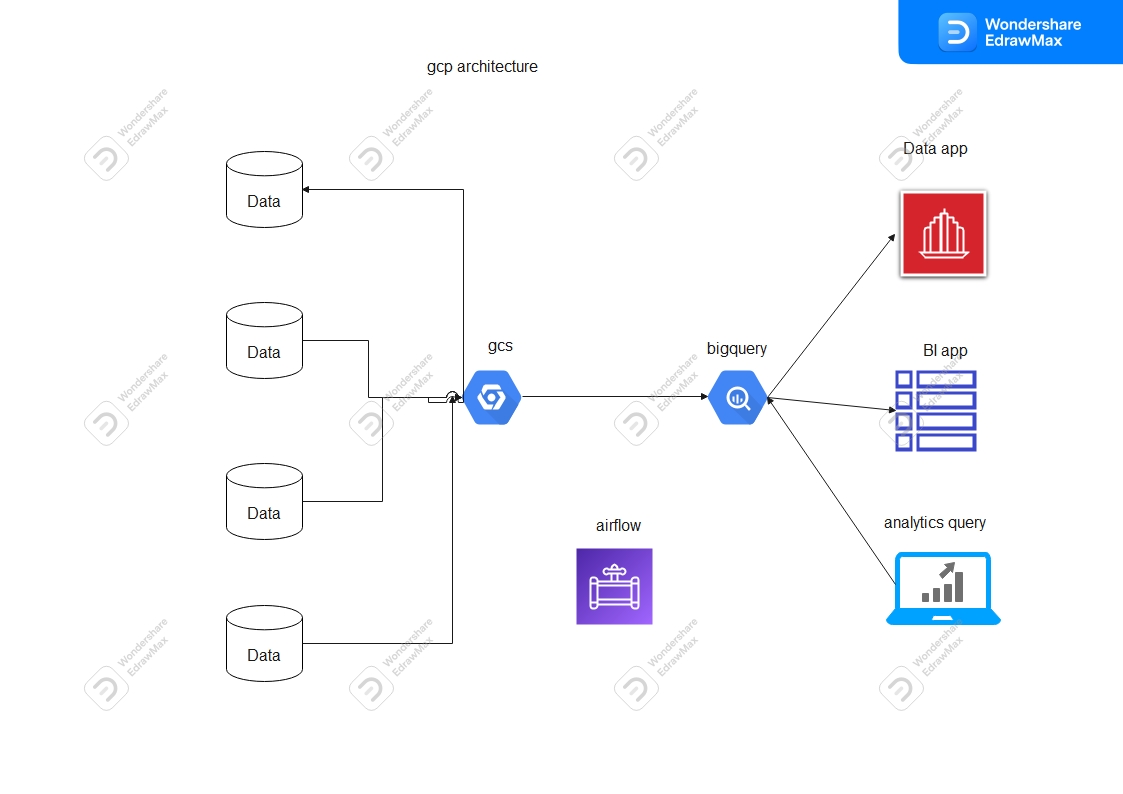
1. 데이터셋 준비하기
I94 Immigration Data: This data comes from the U.S. National Tourism and Trade Office.
https://www.trade.gov/national-travel-and-tourism-office
I94 Data dictionary: Dictionary accompanies the I94 Immigration Data
World Temperature Data: This data came from Kaggle.
https://www.kaggle.com/datasets/berkeleyearth/climate-change-earth-surface-temperature-data
U.S. City Demographic Data: This data came from OpenSoft.
https://public.opendatasoft.com/explore/dataset/us-cities-demographics/export/
Airport Code Table: This is a simple table of airport codes and corresponding cities. It comes from here. https://datahub.io/core/airport-codes#data
데이터셋의 전반적인 아키텍쳐

- F_IMMIGRATION_DATA: contains immigration information such as arrival date, - departure date, visa type, gender, country of origin, etc.
- D_TIME: contains dimensions for date column
- D_PORT: contains port_id and port_name
- D_AIRPORT: contains airports within a state
- D_STATE: contains state_id and state_name
- D_COUNTRY: contains country_id and country_name
- D_WEATHER: contains average weather for a state
- D_CITY_DEMO: contains demographic information for a city
우리가 사용할 구글 클라우드 플랫폼 인프라 설정하기.
해당 데이터를 전부 extract해서 버킷에 올리는 과정은 일정부분 생략하겠음
기존 버킷에 있는 내용물을 자신의 버킷으로 옮기는 프로세스를 사용할 예정
https://cloud.google.com/sdk/docs/install?hl=ko#mac
위의 링크에서 cli 환경을 구축한다.
google cloud cli환경에서 아래의 스크립트를 입력한다.
gsutil -u {gcp-project-id-of-reader} cp -r gs://cloud-data-lake-gcp/ gs://{gcs_bucket_name_of_reader}https://cloud.google.com/storage/docs/using-requester-pays#gsutil_2 참조
Data Pipeline 구축하기
전반적인 흐름은 아래와 같다.
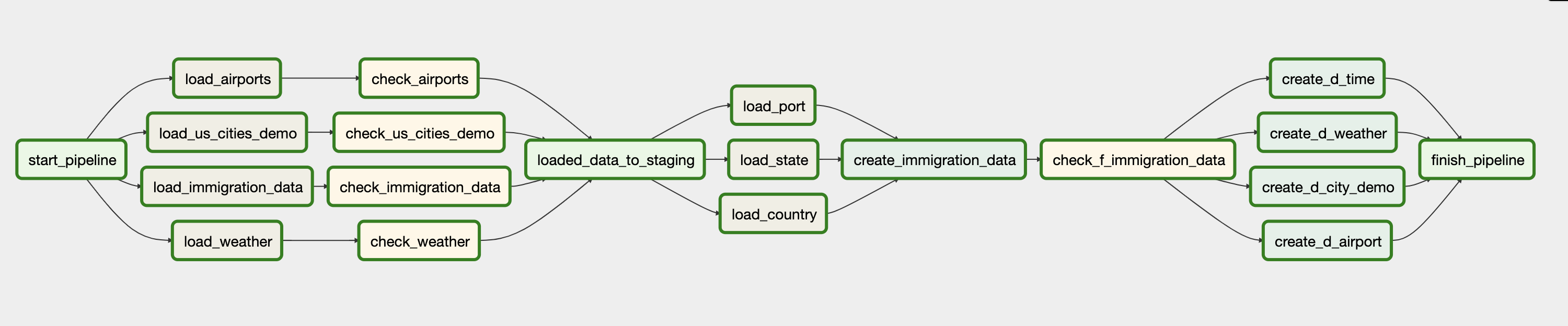
-
Dummy Operator를 사용해 pipeline의 start_point를 생성해주고, 각각의 데이터들을 GCS bucket에서 bigquery table로 옮긴다.(staging to bigquery) -
옮기는 과정에서 중복되는게 없는지 체크가 된다.
-
F_IMMIGRATION_DATA가 만들어진 후 다른 테이블도 만들어진 후 파이프라인이 종료된다.
from airflow import DAG
from airflow.contrib.operators.bigquery_operator import BigQueryOperator
from airflow.operators.dummy_operator import DummyOperator
from datetime import datetime, timedelta
from airflow.contrib.operators.gcs_to_bq import GoogleCloudStorageToBigQueryOperator
from airflow.contrib.operators.bigquery_check_operator import BigQueryCheckOperator
default_args = {
'onwer': 'HyunWoo Oh',
'depends_on_past': False,
'email_on_failure': False,
'email_on_retry': False,
'retries': 5,
'retry_delay': timedelta(minutes=5),
}
## google cloud platform imformation
project_id = 'theta-cider-344811'
staging_dataset = 'IMMIGRATION_DWH_STAGING'
dwh_dataset = 'IMMIGRATION_DWH'
gs_bucket = 'hyunwoo_airflow_example/cloud-data-lake-gcp'
"""
Define DAG
"""
with DAG('cloud-data-lake-pipeline',
start_date=datetime.now(),
schedule_interval='@once',
concurrency=5,
max_active_runs=1,
default_args=default_args
) as dag:
start_pipeline = DummyOperator(
task_id = 'start_pipeline')
# Load data from GCS to BQ
load_us_cities_demo = GoogleCloudStorageToBigQueryOperator(
task_id = 'load_us_cities_demo',
bucket = gs_bucket,
source_objects = ['cities/us-cities-demographics.csv'],
destination_project_dataset_table = f'{project_id}:{staging_dataset}.us_cities_demo',
schema_object = 'cities/us_cities_demo.json',
write_disposition='WRITE_TRUNCATE',
source_format = 'csv',
field_delimiter=';',
skip_leading_rows = 1
)
load_airports = GoogleCloudStorageToBigQueryOperator(
task_id = 'load_airports',
bucket = gs_bucket,
source_objects = ['airports/airport-codes_csv.csv'],
destination_project_dataset_table = f'{project_id}:{staging_dataset}.airport_codes',
schema_object = 'airports/airport_codes.json',
write_disposition='WRITE_TRUNCATE',
source_format = 'csv',
skip_leading_rows = 1
)
load_weather = GoogleCloudStorageToBigQueryOperator(
task_id = 'load_weather',
bucket = gs_bucket,
source_objects = ['weather/GlobalLandTemperaturesByCity.csv'],
destination_project_dataset_table = f'{project_id}:{staging_dataset}.temperature_by_city',
schema_object = 'weather/temperature_by_city.json',
write_disposition='WRITE_TRUNCATE',
source_format = 'csv',
skip_leading_rows = 1
)
load_immigration_data = GoogleCloudStorageToBigQueryOperator(
task_id = 'load_immigration_data',
bucket = gs_bucket,
source_objects = ['immigration_data/*.parquet'],
destination_project_dataset_table = f'{project_id}:{staging_dataset}.immigration_data',
source_format = 'parquet',
write_disposition='WRITE_TRUNCATE',
skip_leading_rows = 1,
autodetect = True
)
# Check loaded data not null
check_us_cities_demo = BigQueryCheckOperator(
task_id = 'check_us_cities_demo',
use_legacy_sql=False,
sql = f'SELECT count(*) FROM `{project_id}.{staging_dataset}.us_cities_demo`'
)
check_airports = BigQueryCheckOperator(
task_id = 'check_airports',
use_legacy_sql=False,
sql = f'SELECT count(*) FROM `{project_id}.{staging_dataset}.airport_codes`'
)
check_weather = BigQueryCheckOperator(
task_id = 'check_weather',
use_legacy_sql=False,
sql = f'SELECT count(*) FROM `{project_id}.{staging_dataset}.temperature_by_city`'
)
check_immigration_data = BigQueryCheckOperator(
task_id = 'check_immigration_data',
use_legacy_sql=False,
sql = f'SELECT count(*) FROM `{project_id}.{staging_dataset}.immigration_data`'
)
loaded_data_to_staging = DummyOperator(
task_id = 'loaded_data_to_staging'
)
# Load dimensions data from files directly to DWH table
load_country = GoogleCloudStorageToBigQueryOperator(
task_id = 'load_country',
bucket = gs_bucket,
source_objects = ['master_data/I94CIT_I94RES.csv'],
destination_project_dataset_table = f'{project_id}:{dwh_dataset}.D_COUNTRY',
write_disposition='WRITE_TRUNCATE',
source_format = 'csv',
skip_leading_rows = 1,
schema_fields=[
{'name': 'COUNTRY_ID', 'type': 'NUMERIC', 'mode': 'NULLABLE'},
{'name': 'COUNTRY_NAME', 'type': 'STRING', 'mode': 'NULLABLE'},
]
)
load_port = GoogleCloudStorageToBigQueryOperator(
task_id = 'load_port',
bucket = gs_bucket,
source_objects = ['master_data/I94PORT.csv'],
destination_project_dataset_table = f'{project_id}:{dwh_dataset}.D_PORT',
write_disposition='WRITE_TRUNCATE',
source_format = 'csv',
skip_leading_rows = 1,
schema_fields=[
{'name': 'PORT_ID', 'type': 'STRING', 'mode': 'NULLABLE'},
{'name': 'PORT_NAME', 'type': 'STRING', 'mode': 'NULLABLE'},
]
)
load_state = GoogleCloudStorageToBigQueryOperator(
task_id = 'load_state',
bucket = gs_bucket,
source_objects = ['master_data/I94ADDR.csv'],
destination_project_dataset_table = f'{project_id}:{dwh_dataset}.D_STATE',
write_disposition='WRITE_TRUNCATE',
source_format = 'csv',
skip_leading_rows = 1,
schema_fields=[
{'name': 'STATE_ID', 'type': 'STRING', 'mode': 'NULLABLE'},
{'name': 'STATE_NAME', 'type': 'STRING', 'mode': 'NULLABLE'},
]
)
# Transform, load, and check fact data
create_immigration_data = BigQueryOperator(
task_id = 'create_immigration_data',
use_legacy_sql = False,
params = {
'project_id': project_id,
'staging_dataset': staging_dataset,
'dwh_dataset': dwh_dataset
},
sql = '/Users/ohyeon-u/airflow/dags/sql/F_IMMIGRATION_DATA.sql'
)
check_f_immigration_data = BigQueryCheckOperator(
task_id = 'check_f_immigration_data',
use_legacy_sql=False,
params = {
'project_id': project_id,
'staging_dataset': staging_dataset,
'dwh_dataset': dwh_dataset
},
sql = f'SELECT count(*) = count(distinct cicid) FROM `{project_id}.{dwh_dataset}.F_IMMIGRATION_DATA`'
)
# Create remaining dimensions data
create_d_time = BigQueryOperator(
task_id = 'create_d_time',
use_legacy_sql = False,
params = {
'project_id': project_id,
'staging_dataset': staging_dataset,
'dwh_dataset': dwh_dataset
},
sql = '/Users/ohyeon-u/airflow/dags/sql/D_TIME.sql'
)
create_d_weather = BigQueryOperator(
task_id = 'create_d_weather',
use_legacy_sql = False,
params = {
'project_id': project_id,
'staging_dataset': staging_dataset,
'dwh_dataset': dwh_dataset
},
sql = '/Users/ohyeon-u/airflow/dags/sql/D_WEATHER.sql'
)
create_d_airport = BigQueryOperator(
task_id = 'create_d_airport',
use_legacy_sql = False,
params = {
'project_id': project_id,
'staging_dataset': staging_dataset,
'dwh_dataset': dwh_dataset
},
sql = '/Users/ohyeon-u/airflow/dags/sql/D_AIRPORT.sql'
)
create_d_city_demo = BigQueryOperator(
task_id = 'create_d_city_demo',
use_legacy_sql = False,
params = {
'project_id': project_id,
'staging_dataset': staging_dataset,
'dwh_dataset': dwh_dataset
},
sql = '/Users/ohyeon-u/airflow/dags/sql/D_CITY_DEMO.sql'
)
finish_pipeline = DummyOperator(
task_id = 'finish_pipeline'
)
# Define task dependencies
start_pipeline >> [load_us_cities_demo, load_airports, load_weather, load_immigration_data]
load_us_cities_demo >> check_us_cities_demo
load_airports >> check_airports
load_weather >> check_weather
load_immigration_data >> check_immigration_data
[check_us_cities_demo, check_airports, check_weather,check_immigration_data] >> loaded_data_to_staging
loaded_data_to_staging >> [load_country, load_port, load_state] >> create_immigration_data >> check_f_immigration_data
check_f_immigration_data >> [create_d_time, create_d_weather, create_d_airport, create_d_city_demo] >> finish_pipeline이후 에어플로우 ui로 들어가서 실행하면 된다... 라고 생각했다.
전반적인 에어플로우 흐름.
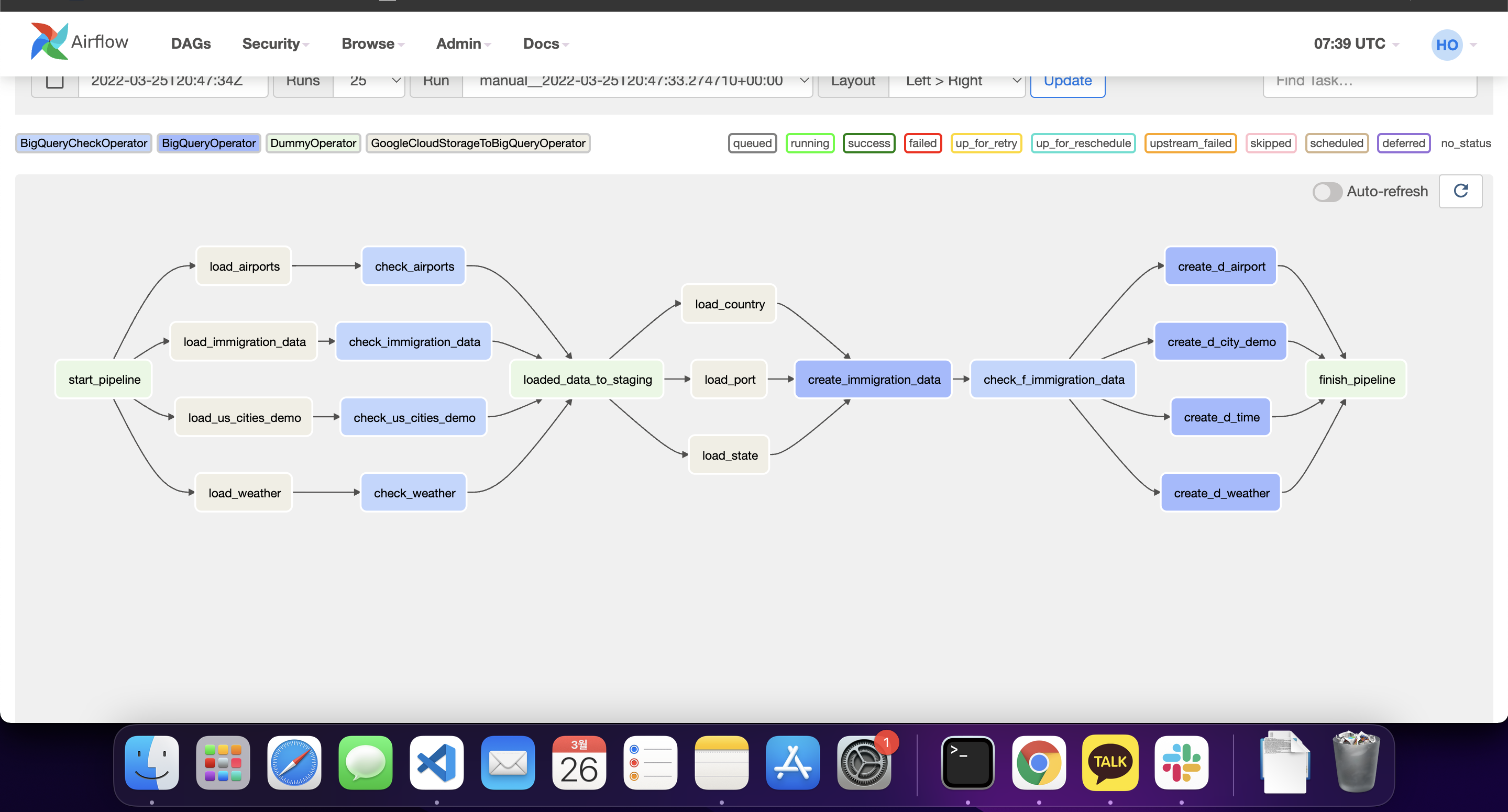
dag들은 정상적으로 실행은 되는데, 빅쿼리로 데이터가 올라오지 않는다. 해당 문제를 해결하기 위해서는 단서가 있어야 하는데, 어떠한 단서도 airflow에서 얻을 수 없었다. 때문에 일관된 환경을 조성하는 것과 디버깅툴의 필요성을 느끼면서 해당 실습은 일단 마쳐야 할 것 같다.
나만의 방법으로 해당 리소스를 해결해보려 했는데, 힘이 들어서 해당 환경을 일관되게 세팅해줄 수 있은 도커의 필요성을 다시 한번 느낀다.

안녕하세요. 작성해주신 글 잘보았습니다.
한 가지 여쭤볼 게 있는데, 파이프라인 소스코드 중간에 D_AIRPORT.sql 과 같은 파일들은 테이블 생성 create 문일까요??