지난 시간 리뷰
우리는 지난 시간에 웹에 존재하는 csv파일을 가져와 gcs bucket에 업로드하는 과정을 거쳤다. 이제 우리는 bigquery로 데이터를 옮기려 한다.
빅쿼리에 데이터 세트 만들기
gcp 안에서 해당 프로젝트에 동일한 리전으로 데이터세트를 만들어주자.
리전이 다르면 gcstobigquery를 사용할 수 없다.
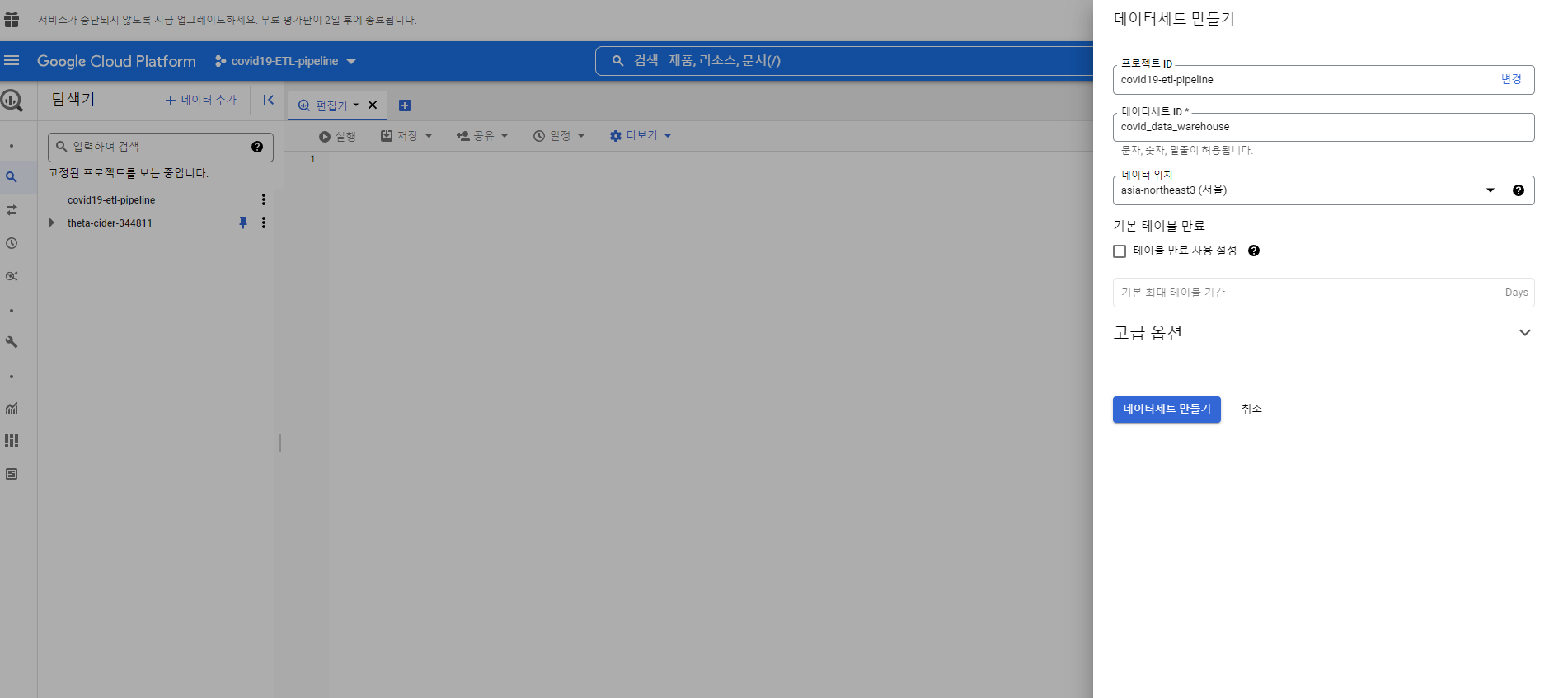
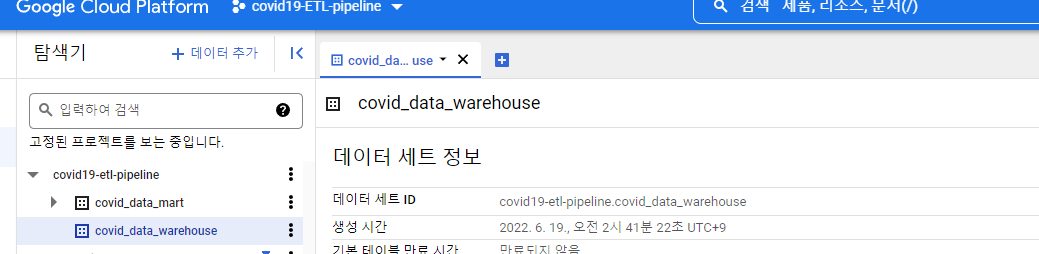
총 2개의 데이터 세트를 만들어주자.
하나는 원본 데이터를 하나는 원본 데이터 즉 데이터 웨어하우스로 부터 만든 데이터 마트를 구성해주자.
DAG Second step!! Transform DATA
load to bigquery and make data warehouse!
먼저 우리는 Biquery에 원본 데이터를 그대로 올릴 것이다.
load_to_bigquery = GCSToBigQueryOperator(
task_id='load_to_bigquery',
gcp_conn_id="gcs_conn_id",
bucket=gs_bucket,
source_objects=['covid-19.csv'],
destination_project_dataset_table=f"{staging_dataset}.covid_data",
source_format='csv',
autodetect=True,
skip_leading_rows=1,
write_disposition='WRITE_TRUNCATE'
)
csv 파일의 헤더에 메타데이터가 저장되어 있으므로 autodetect=True, skip_leading_rows=1 을 통해 해당 메타데이터가 어디 있는지 알려주자.
해당 태스크를 테스트 해보자.
docker exec 1da627d47024 airflow tasks test Covid-19_ETL load_to_bigquery 2022-01-01
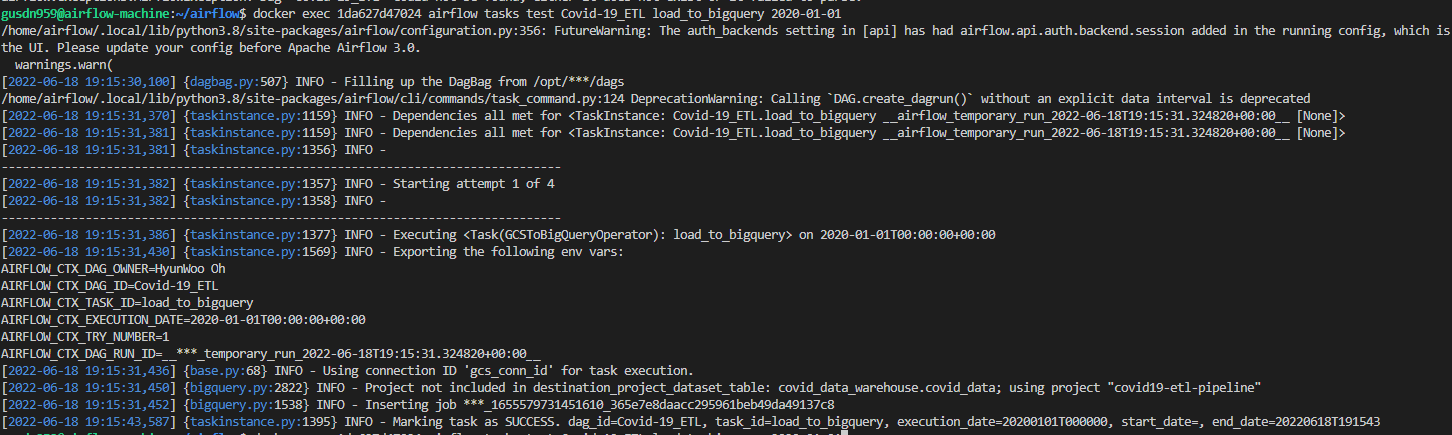
정상적으로 해당 빅쿼리 데이터 세트에 올라갔다.
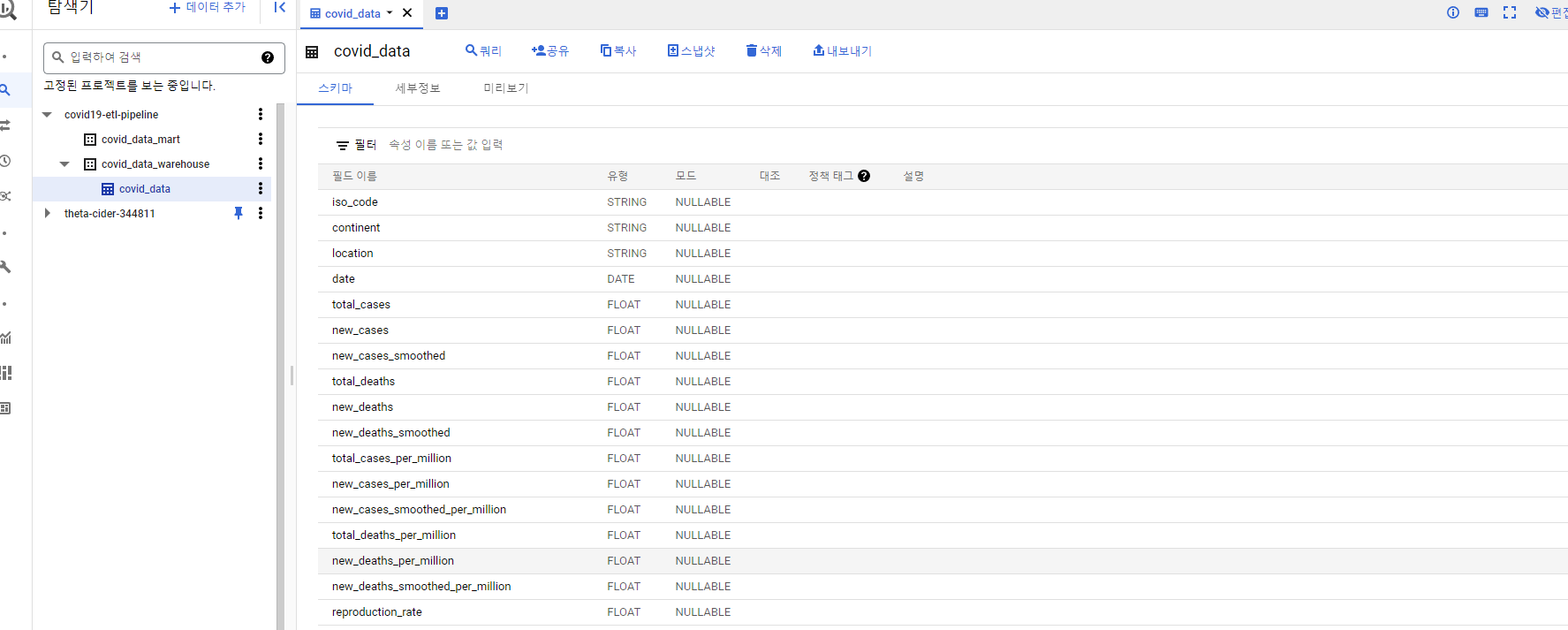
이제 우리가 할 내용은 저장된 데이터를 기반으로 sql문을 작성하여 우리가 자주 사용하는 변수들만으로 구성된 데이터 마트를 구성하는 것이다.
현재는 그냥 단순히 하나의 파일로 구성된 csv 파일이라 체감되지 않을 내용이다.
하지만 데이터 웨어하우스는 모든 관계형 db들을 하나의 스타스키마의 형태로 조인 시킨다.
그럼 나중에 조인을 하지 않아도 되어서 쿼리의 효율성이 높아진다.
하지만 데이터의 크기가 커지니 우리는 쓸데없는 컬럼을 계속해서 불러오게 된다.
이럴 때 필요한 것이 바로 데이터 마트이다. 해당 데이터 마트는 자주 쓰는 컬럼별로 모아서 데이터 마트를 구성해 놓으면 우리는 효율좋고 빠르게 우리가 원하는 데이터를 불러 올 수 있다.
Data mart 만들기!
우선 해당 데이터는 다양한 데이터 과학자들이 각각의 변수들을 조합해 좋은 피쳐들을 만들어 놓았다. 때문에 우리는 66개의 변수중에서 가장 많이 사용할 변수만 채택해서 일단 데이터 마트를 구성하려고 한다.
일단 우리는 2가지 케이스를 고려 해야한다.
- 데이터 마트에 데이터가 없는 경우
- 데이터 마트에 데이터가 이미 존재하는 경우
때문에 쿼리를 아래와 같이 짜주자.
CREATE OR REPLACE TABLE
`{{ params.dwh_dataset }}.data_mart`
AS SELECT
iso_code AS ISO_CODE,
continent AS Continent,
location AS Country,
total_cases,
new_cases,
total_deaths,
new_deaths,
total_cases_per_million,
new_cases_per_million,
total_deaths_per_million,
new_deaths_per_million,
reproduction_rate,
icu_patients,
icu_patients_per_million,
hosp_patients,
hosp_patients_per_million,
weekly_icu_admissions,
total_tests_per_thousand,
new_tests_per_thousand,
total_vaccinations,
new_vaccinations
FROM
`{{ params.project_id }}.{{ params.staging_dataset }}.covid_data`;exist 문도 괜찮지만 해당 파일의 크지않을 뿐더러 해당 파일의 컬럼의 갯수가 지속적으로 달라지고 있다. 때문에 지속적으로 테이블을 생성해주는 것이 적절하다고 생각하였다.
그리고 태스크를 정의해주자.
build_data_mart = BigQueryInsertJobOperator(
task_id="build_data_mart",
gcp_conn_id="gcs_conn_id",
configuration={
"query":{
"query": "{% include './sql/covid.sql' %}",
"useLegacySql": False,
}
},
params={
'project_id': project_id,
'staging_dataset': staging_dataset,
'dwh_dataset': dwh_dataset
},
)이제 테스트 해보자.
docker exec -it 1da627d47024 airflow tasks test Covid-19_ETL build_data_mart 2022-01-01
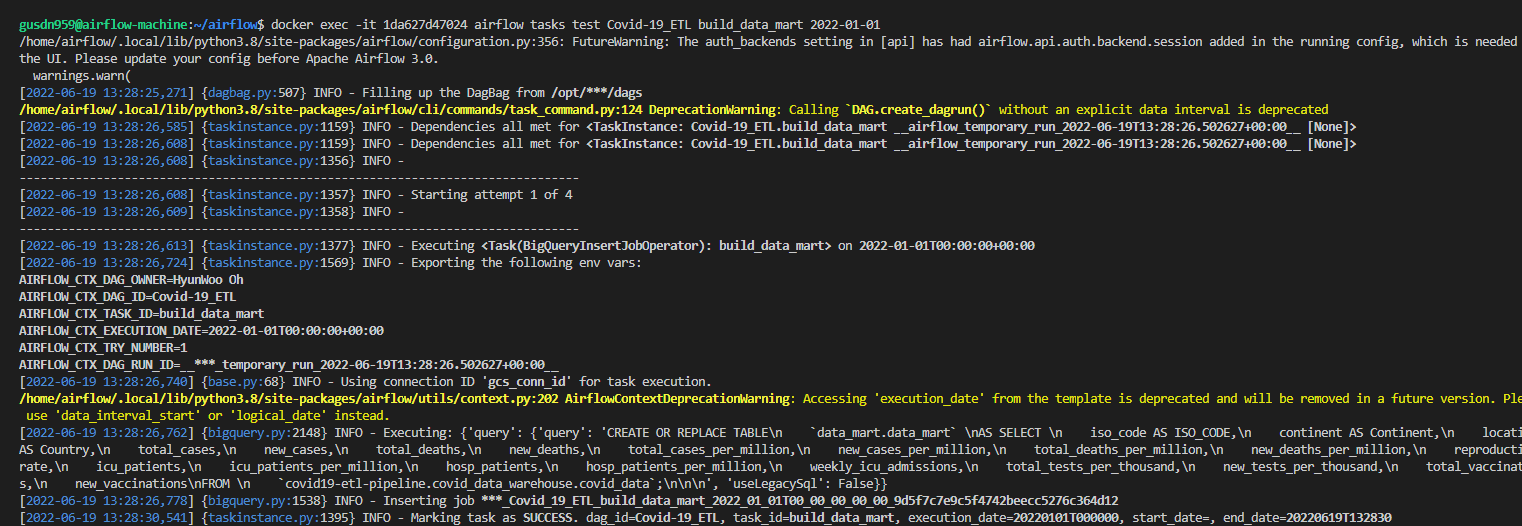
정상적으로 쿼리문이 빅쿼리에 전달되어서 하나의 데이터 마트를 구성했다.
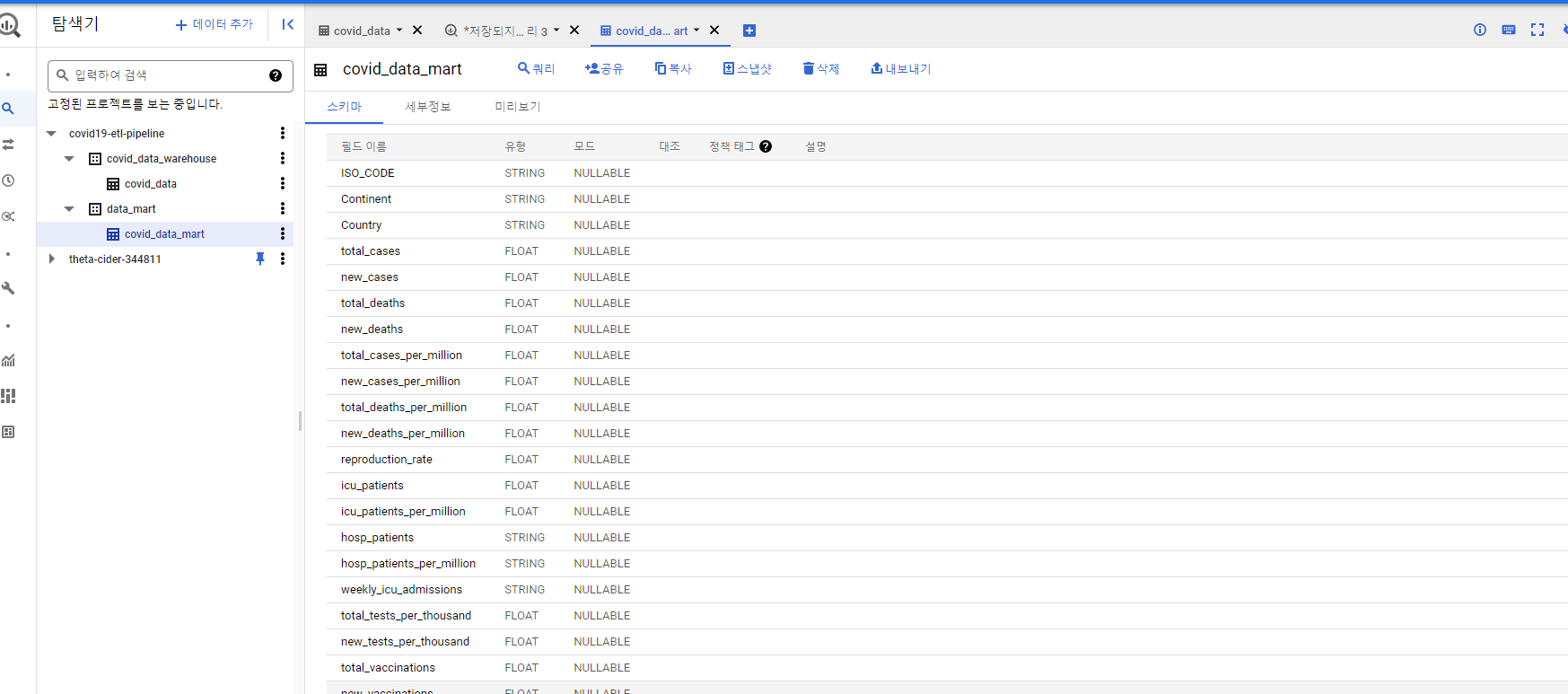
데이터 파이프라인!!!
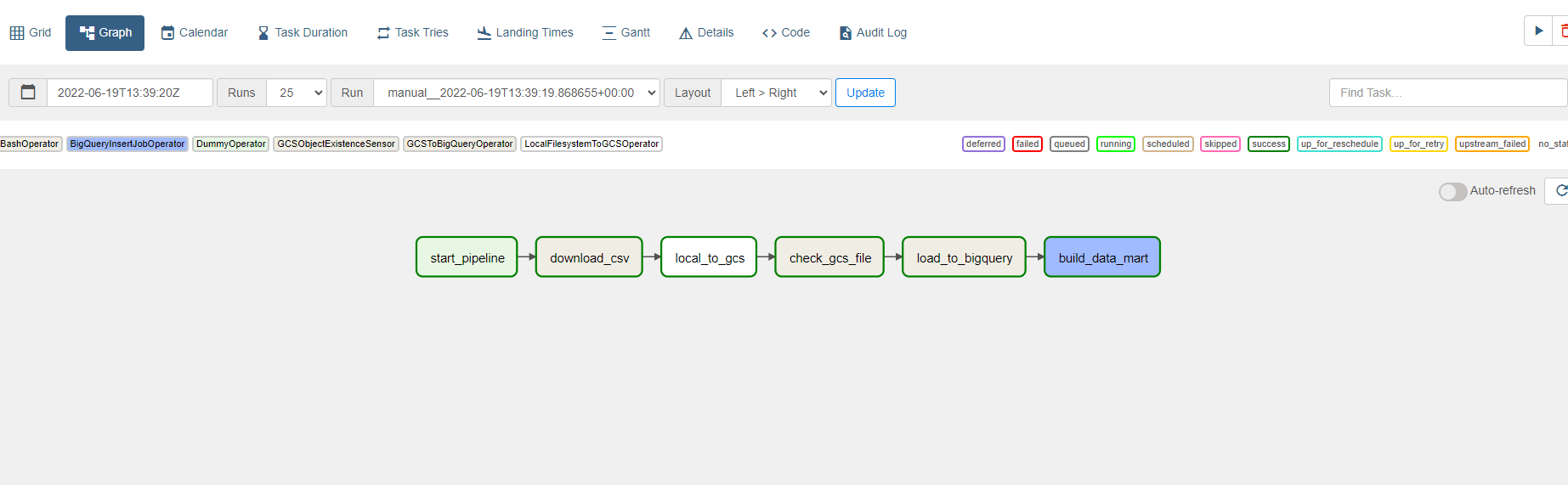
해당 데이터 파이프라인 구축 프로젝트를 마치며...
위의 프로세스 적은 데이터이며 하나의 파일이라 그냥 사람이 직접 전부 진행하는 것이 편하다.
그러나 우리는 아래와 같은 이점이 있기 때문에 airflow를 사용한다.
-
확장성: airflow는 task만 추가하면 되며 또한 VM을 활용하여 노드를 추가할 수 있다.
-
안정성: 사람은 일관적이지 못하다. 항상 조금씩 달라진다. 때문에 우리는 워크플로우를 자동화하여 안정성을 만들 수 있다.
-
규칙성: airflow를 통해 규칙적으로 지속적으로 스케쥴링이 가능하다.
하지만 airflow를 활용하려면 많은 환경 세팅이 필요하다. 본인도 환경 세팅에 많은 시간을 할애하였다.
때문에 이러한 환경세팅을 자동화할 수 있는 도커에 대해 필요성을 다시 느끼면서 위의 프로젝트를 마친다.
해당 프로젝트의 부록으로 tableau를 활용해 빅쿼리와 연동하여 위에서 구축한 정보를
토대로 시각화하여 대시보드를 만들어 볼 예정이다.

github 주소
본인이 airflow 환경 구축을 위해 만든 yaml dags plugin 들이다.
확인해가면서 진행하도록 하자.
