
하나의 컴퓨터로 불가능한 작업을 나눠 처리 가능하게 해주는 하둡
위의 제목에서 하둡이 필요한 이유를 명확히 알 수 있다. 우리의 기술이 이제 컴퓨터의 성능을 극한으로 끌어 올리는 것보다 컴퓨터를 대량으로 늘리는 것이 싸게 먹히는 시대가 도래한 것이다.
HADOOP DISTRIBUTED FILE SYSYTEM
이름에서 어느정도 유추할 수 있듯이 분산처리를 가능하게 하는 것이 하둡이다.
대용량 분산 처리 기술의 특징을 정의하자면 3가지 정도가 존재한다.
-
분산 컴퓨팅과 분산 파일 시스템이 존재한다.
-
소수의 서버가 고장나도 전체가 정상적으로 동작해야한다.
-
SCALE OUT이 용이해야한다. (SCALE UP > 고성능으로 업그레이드 , SCALE OUT > 장비를 추가하여 확장)
하둡 1.0은 1번 특징을 가능하게 하기 위해 아래와 같은 아키텍쳐를 사용한다.
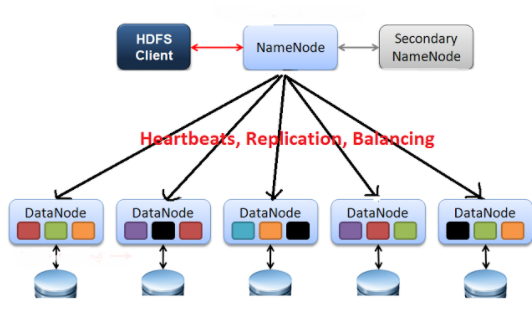
Secondary Namenode의 경우 hadoop 2.0에서 나온 개념이므로 제외하고 보는게 좋다.
Name Node
data 노드에 분산되어 저장된 파일들의 위치를 추적가능하게 하며, 각각의 데이터 노드들에 일을
할당 가능하게 하는 master node의 역할을 수행한다.
Data Node
각각의 데이터 노드들은 디스크에 블럭의 크기가 맞춰 하나의 파일을 여러 블럭에 남아 담는다.
(예를 들어 400mb인 파일을 128mb의 크기가 디폴트라고 가정할 때 총 4개의 블럭으로 나눠 각각의 데이터 노드에 저장가능하게 한다.)
하드디스크에 저장하는 단점 때문에 속도가 느림 추후 스파크에서는 메모리에 저장하여 더빠른 연산이 가능하게 함
하둡 1.0에서 2번 특징은 하나의 블럭을 3개 복사하여 각각의 임의의 데이터 노드에 넣어 보관한
다.
이렇게 함으로써 하나의 컴퓨터가 녹아 사라지더라도, 나머지 2개의 컴퓨터가 멀쩡하다면 정상적으로 동작가능하게 설계하였다. (3개가 전부 사라진다면...? 끔찍하다... 정보손실)
3번 특징은 아주 간단하게 해결이 가능하다.
데이터 노드의 숫자를 늘려주면 된다.
이러한 하둡 1.0버전은 이론상 완벽해 보이지만 치명적인 단점이 존재한다.
네임노드의 상실은 모든 하둡 시스템의 마비로 이어진다.
예를 하나 들어보자면, 1번 데이터 노드 3초에 한번씩 심장 박동처럼 네임 노드에 시그널을 보낸다
고 생각해보자.1번 데이터 노드의 신호에 네임노드가 응답이 없으면 네임 노드의 상실로 판단하게
된다. 이러한 일이 발생한다면 1번 데이터 노드에서 처리한 일의 내용과 각각의 데이터 노드에 생
성된 블럭들의 이용가치가 모두 상실하게 된다.(내이름을 아는 모든 사람이 사라졌다고 생각해보라.. 정말 끔찍하다.)
하둡의 특징은 이정도로 정리 하도록 하고, 어떻게 하둡이 대용량 분산 처리가능하게 하는 방법을 다음 포스팅에서 다루도록 하겠다. 이만 총총~
