이 글은 강의 : 김영한님의 - "[스프링 DB 2편 - 데이터 접근 활용 기술]"을 듣고 정리한 내용입니다. 😁😁
✈️ JPA 설정
build.gradle에 라이브러리 의존성을 추가하고 필요한 경우 application.properties에 로그 설정값을 추가하면 된다.
build.gradle 설정
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
위 코드를 build.gradle에 추가하면 된다. 이 의존성이 추가되면 다음 코드들이 추가된다.
jakarta.persistence-api : JPA 인터페이스
hibernate-core : JPA 구현체인 하이버네이트 라이브러리
spring-data-jpa : 스프링 데이터 JPA 라이브러리
JdbcTemplate 관련 라이브러리
(JPA의 구현체가 하이버네이트이기 때문에 하이버네이트라고 말하면 JPA라고 생각할 것.)
Spring Data JPA의 의존성을 추가해주면 JdbcTemplate 관련 라이브러리들이 알아서 추가된다. 따라서 JdbcTemplate을 위해서 build.gradle에 의존성을 추가해두었다면 그 부분을 삭제해도 무방하다.
로깅 정보
# JPA Log
logging.level.org.hibernate.SQL=DEBUG
logging.level.org.hibernate.type.descriptor.sql.BasicBinder=TRACE
# JPA Log
spring.jpa.show-sql=true위 코드를 application.properties에 추가해서 JPA 로그를 남길 수 있다. 각 명령어는 다음과 같이 동작한다.
- org.hibernate.SQL : 하이버네이트가 생성하고 실행하는 SQL 확인 가능하다. Logger를 통해 출력 돼.
- org.hibernate.type.descriptor.sql.BasicBinder : SQL에 바인딩 되는 파라미터를 확인할 수 있다. Logger를 통해 출력 돼
- spring.jpa.show-sql : 하이버네이트가 생성하고 실행하는 SQL 확인 가능하다. System.out을 통해 출력됨. (비추천)
🚀 JPA 적용
라이브러리 설정을 완료했으면 이제 도메인과 리포지토리 영역에 JPA 사용을 위한 설정을 진행해야한다.
🎈 JPA 도메인 설정 (매우 중요 !😀)
JPA를 사용하기 위해서는 기본적으로 사용하고자 하는 도메인(Item 도메인) JPA를 위한 어노테이션을 추가해야한다. JPA에서 사용하는 많은 어노테이션이 있으며 아래는 그 중에 극소수의 어노테이션이다.
- @Entity : JPA가 사용하는 객체라는 뜻이다. 이 어노테이션이 있어야 JPA가 인식한다.
- @Id : 테이블의 PK와 객체의 필드를 맵핑한다.
- @GeneratedValue(strategy = GenerationType.IDENTITY) : PK 생성 전략을 설정할 수 있다. Identity는 DB에서 생성한 PK 값을 사용
- @Column : 테이블의 컬럼명과 객체의 필드명을 맵핑
- name : 테이블의 컬럼명을 표시.
- length : JPA가 DDL을 수행할 때 컬럼의 길이값으로 사용됨. length = 10 → varchar 10
- @Column을 생략하면 필드명으로 컬럼에 매칭한다.
- @Column은 카멜 케이스를 언더스코어로 자동으로 변환해준다. (itemName → item_name)
@Data
@Entity // JPA가 사용하는 객체라는 뜻. 이게 있어야 JPA가 인식함.
//@Table(name = "item") // 테이블명 = 객체명이면 생략해도 가능함.
public class Item {
// DB에서 ID 값을 넣어줌.
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "item_name", length = 10)
private String itemName;
@Column(name = "price")
private Integer price;
// 컬럼명 == 필드명이면 @Column 생략 가능함.
private Integer quantity;
// JPA는 public으로 default 생성자가 필요함. (프록시를 위해서)
public Item() {
}
public Item(String itemName, Integer price, Integer quantity) {
this.itemName = itemName;
this.price = price;
this.quantity = quantity;
}
}🎈 JPA는 기본 생성자가 반드시 필요하다.
JPA는 프록시를 이용해서 구현되어있다. 프록시를 원활하게 사용하기 위해서는 기본 생성자가 필요한데, JPA는 기술 스펙으로 반드시 기본 생성자를 요구한다. 따라서 위와 같이 사용 도메인에 기본 생성자를 추가한다.
😀 JPA Repository 설정
가장 크게 추가되는 설정값은 다음 두 가지다.
🎈 EntityManager
-
JPA의 모든 동작은 EnitytManager 객체를 이용해서 실행된다. 따라서 Repository에는 EntityManager를 제공해줘야한다.
-
EntityManager는 EntityManagerFactory, JpaTransactionManager, DataSource 등 다양한 설정을 해야한다. 스프링부트는 이 과정을 모두 자동화해서 EntityManager를 스프링 빈으로 등록해준다.
🎈 @Transactional
- JPA는 트랜잭션 기반으로 동작한다. 단순 조회는 트랜잭션 없이도 읽기 전용 쿼리로 조회가 가능하긴 하다.
- 일반적으로는 Service 계층에서 트랜잭션을 시작한다.
JPA를 이용할 때의 Repository
@Slf4j
@Repository
@Transactional // JPA는 트랜잭션을 이용해서 동작한다.
@RequiredArgsConstructor
public class JpaItemRepository implements ItemRepository {
private final EntityManager em;
@Override
public Item save(Item item) {
em.persist(item);
return item;
}
// 더티 체크를 이용한 업데이트.
@Override
public void update(Long itemId, ItemUpdateDto updateParam) {
Item item = em.find(Item.class, itemId);
item.setItemName(updateParam.getItemName());
item.setPrice(updateParam.getPrice());
item.setQuantity(updateParam.getQuantity());
}
@Override
public Optional<Item> findById(Long id) {
return Optional.ofNullable(em.find(Item.class, id));
}
@Override
public List<Item> findAll(ItemSearchCond cond) {
String itemName = cond.getItemName();
Integer maxPrice = cond.getMaxPrice();
String jpql = "select i from Item i";
boolean firstFlag = false;
if (StringUtils.hasText(itemName) ) {
jpql = jpql + " where i.itemName like concat('%', :itemName, '%')";
firstFlag = true;
}
if (maxPrice != null) {
if (firstFlag) {
jpql = jpql + " and i.price <= :maxPrice";
}else{
jpql = jpql + " where i.price <= :maxPrice";
}
}
log.info("jpql={}", jpql);
TypedQuery<Item> query = em.createQuery(jpql, Item.class);
if (StringUtils.hasText(itemName)) {
query.setParameter("itemName", itemName);
}
if (maxPrice != null) {
query.setParameter("maxPrice", maxPrice);
}
return query.getResultList();
}
}- 기본적으로 JPA에서 데이터를 변경할 때는 항상 @Transactional이 있어야 한다. + JPA에서는
EntityManager를 DI 받아야 한다. 이게 있어야 JPA이다.. 여기에 저장하고 조회하고 등등 실행될 것이다.
😀 save 쿼리
em.persist(item);
- 해당 코드는 맵핑 정보를 가지고 insert 쿼리를 만들어서 DB에 저장한다.
insert into item (id, item_name, price, quantity) values (default, ?, ?, ?)
위와 같이 JPA가 쿼리를 생성한다. 쿼리에서 확인해볼 부분은 id에 default 값이 들어간다는 점.
- PK 키 생성 전략을 Identity로 사용한다면 JPA는 위와 같은 쿼리를 생성한다. 비록 JPA는 쿼리를 보낼 때, Item 객체의 Id 필드에 default 값이 들어가서 DB가 생성한 PK 값이 들어가게 된다. 그렇지만 Insert 쿼리 실행 이후에 생성된 ID 결과를 받아서 넣어준다.
Update 쿼리
public void update(Long itemId, ItemUpdateDto updateParam) {
Item findItem = em.find(Item.class, itemId);
findItem.setItemName(updateParam.getItemName());
findItem.setPrice(updateParam.getPrice());
findItem.setQuantity(updateParam.getQuantity());
}🎈 JPA를 사용할 때는 Update 쿼리를 직접 작성하지 않는다. 대신에 영속성 컨텍스트의 더티체크를 이용해서 실행된다.
🎈 JPA는 트랜잭션 커밋 전, flush()전, jpql 실행 전에 영속성 컨텍스트를 flush한다. flush하는 시점에 더티체크를 이용해서 변경점이 있는 엔티티에는 UPDATE SQL을 실행한다.
🎈 테스트 코드에서는 @Transactional 어노테이션 안에서 commit이 실행되지 않는다. 따라서 아래 두 가지 방법을 이용해서 수동 Commit 한 후에, Update 쿼리를 확인해 볼 수 있다.
- @commit 어노테이션 추가.
- em.flush()
JPA에서 여러 데이터를 복잡한 조건으로 데이터를 조회하려면 ?
JPA에서 단순히 PK를 기준으로 조회하는 것이 아닌, 여러 데이터를 복잡한 조건으로 데이터를 조회하려면 어떻게 하면 될까 ?
😀 JPQL
JPA는 JPQL(Java Persistence Query Language)라는 객체지향 쿼리 언어를 제공한다.
SQL이 테이블을 대상으로 한다면, JPQL은 엔티티 객체를 대상으로 한다. 따라서 JPQL을 사용할 때, from 절 뒤에 엔티티 객체의 이름이 들어간다. 그리고 모든 필드는 엔티티 객체의 별칭 + 컬럼명으로 접근한다. 아래에서 예시를 확인할 수 있다. (엔티티 객체와 속성의 대소문자는 구분해야 한다!)
// JPQL
SELECT i from Item i
WHERE i.itemName like concat('%',:itemName'%')
and i.price <= :maxPrice
// JPQL을 통해 실행된 SQL
select
item0_.id as id1_0_,
item0_.item_name as item_nam2_0_,
item0_.price as price3_0_,
item0_.quantity as quantity4_0_
from item item0_
where (item0_.item_name like ('%'||?||'%'))
and item0_.price<=파라미터
JPQL에서 파라미터는 다음과 같이 입력한다.
where price <= :maxPrice
- 파라미터 바인딩은 ?
query.setParameter("maxPrice", maxPrice)
순수 JPA의 문제점
순수 JPA 문제점 중 하나는 동적쿼리를 작성하기가 어렵다는 것이다. 예를 들어 검색 조건에 따라서 동적쿼리를 생성하는 경우, 그 때 작성된 쿼리는 아래와 같고, 문제점도 살펴볼 수 있다.
- 로직이 복잡해지면 많은 오류가 수반된다.
- 쿼리가 문자열로 작성된다.
- 동적 쿼리에서 사용하는 조건문들이 재반복되지 않는다. 즉, 코드가 길어진다.
순수 JPA에서 동적 쿼리를 작성할 때는 위 같은 문제점이 있기 때문에 QueryDSL과 함께 사용된다.
- QueryDsl을 사용하면 매우 깔끔해져 !! (이상적인 방법)
@Override
public List<Item> findAll(ItemSearchCond cond) {
String itemName = cond.getItemName();
Integer maxPrice = cond.getMaxPrice();
String jpql = "select i from Item i";
boolean firstFlag = false;
if (StringUtils.hasText(itemName) ) {
jpql = jpql + " where i.itemName like concat('%', :itemName, '%')";
firstFlag = true;
}
if (maxPrice != null) {
if (firstFlag) {
jpql = jpql + " and i.price <= :maxPrice";
}else{
jpql = jpql + " where i.price <= :maxPrice";
}
}
log.info("jpql={}", jpql);
TypedQuery<Item> query = em.createQuery(jpql, Item.class);
if (StringUtils.hasText(itemName)) {
query.setParameter("itemName", itemName);
}
if (maxPrice != null) {
query.setParameter("maxPrice", maxPrice);
}
return query.getResultList();
}🎈 JPA와 예외변환
JPA는 EntityManager를 이용해서 DB와 Repository 계층 사이에서 인터페이스한다. 만약 JPA가 동작하다가 문제가 발생하면 EntityManager에서 예외가 발생되게 될 것이다. 이 때, JPA는 스프링과 관련이 없기 때문에 JPA에서 사용하는 예외를 발생시킨다. 이 때 발생되는 예외는 PersistenceException, IllegalSTateException, IllegalArgumentException들이다.
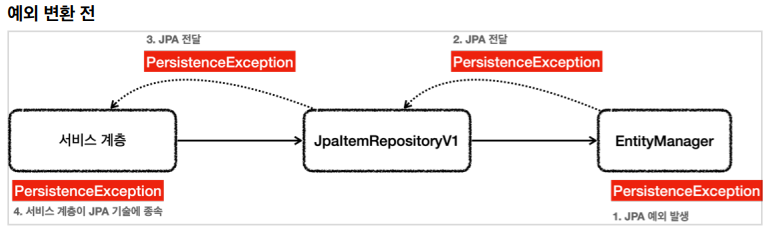
만약 JPA, 정확하게는 EntityManager에서 Exception이 발생하게 된다면 여기서 발생하는 Exception이 서비스 계층까지 바로 다이렉트로 전달되게 될 것이다. 그리고 서비스 계층에서 바라보는 예외는 PersistenceException이고, 이 예외는 JPA와 관련된 예외다. 서비스 계층에서는 이 예외를 처리하기 위해서 PersistenceException을 캐치하는 로직이 들어가야한다. 이렇게 구성되게 된다면 Service 계층은 JPA 기술에 종속되게 된다. 계층별로 기술 종속성이 분리가 되지 않았다는 것이다.
- 그렇다면 어떻게 JPA 예외를 스프링 예외 추상화(DataAccessException)로 어떻게 변환할 수 있을까 ?
🎈 비밀은 바로 @Repository에 있다.
JPA와 Service 계층의 분리의 핵심 - @Repository
🎈 @Repository를 Repository 계층에 설정해주면 위 문제가 해결된다. @Repository는 아래 두 가지 기능을 가진다.
-
Component Scan의 대상이 된다.
-
어노테이션이 달린 클래스를 예외변환 AOP의 적용 대상으로 만든다.
- 예외변환 AOP는 JPA 관련 예외가 발생하면, JPA 예외 변환기를 이용해 발생한 예외를 스프링 데이터 접근 예외로 변환한다.
- 예외변환 AOP는 스프링부트가 자동으로 등록해준다.
-
결국 런타임 예외를 잡아주고 스프링 예외로 변환해준다고 이해하면 된다.
