
이 글은 강의 : 김영한님의 - "[모든 개발자를 위한 HTTP 웹 기본지식]"을 듣고 정리한 내용입니다. 😁😁
API URI 설계 시 포인트
URI 설계시 가장 중요한 것은 리소스 식별이다.
리소스란?
동작을 제외한 자원 그 자체를 리소스라한다. 회원 등록 시스템을 예로 들면, 회원을 등록하거나 수정 혹은 삭제하는 행위는 리소스가 아니다.오직 회원이라는 개념만이 리소스라 할 수 있다.
리소스 기반의 회원 관리 URI 설계
동작은 HTTP 메서드로 구분한다. (EX. GET, POST, PUT, PATCH, DELETE)

✨ 게층 구조상 상위 자원을 컬렉션으로 보기에 복수형으로 사용하는게 좋다.
EX: member-> members
리소스와 행위를 분리
가장 중요한 것은 리소스를 식별하는 것!
- URI는 리소스만 식별!
- 리소스와 해당 리소스를 대상으로 하는 행위를 분리
🎄 리소스 : 회원
🎄 행위 : 조회, 등록, 삭제, 변경 - 리소스는 명사, 행위는 동사 (미네랄을 캐라)
- 행위(메서드)는 어떻게 구분하는가? --> HTTP 메서드
우리는 리소스만 식별하면 된다. 행위는 HTTP메서드가 구분해주니까!
HTTP 메서드
클라이언트가 서버에 요청을 할 때 기대하는 행동!
ex) GET은 무언가를 달라는 것이고 POST는 요청 데이터를 처리해줘! 이런 식으로 활용할거야.
GET
- 리소스 조회에 사용된다.
- 서버에 전달할 데이터는 query string을 통해 전달한다.
- EX:
q=hello&hl=ko - 메세지 바디는 사용은 가능하지만, 지원되지 않는 곳이 많아 권장되지 않는다.
POST
- 메세지 바디를 통해 서버로 요청 데이터를 전달하면 서버는 해당 데이터를 처리한다.
- 주로 등록 혹은 프로세스 처리등에 사용된다.
(메세지 바디를 통해 들어온 데이터를 처리하는 모든 기능을 수행한다.)
1.리소스 등록 : 서버가 아직 식별하지 않은 새 리소스 생성(회원 등록)
2.요청 데이터 처리 : 단순한 데이터 생성을 넘어 프로세스를 처리해야 하는 경우로, 꼭 새로운 리소스가 생성되지 않을 수도 있다.
POST /order/{orderId}/start-delivery (컨트롤 URI)
이처럼 경우에 따라 리소스단위가 아닌 행위가 포함된 URI 설계를 할 수도 있는데 이런 경우를 Control URI라 한다.
- 다른 메서드로 해결하기 어려운 경우 POST를 사용하고는 한다.
ex) JSON으로 조회 데이터를 넘겨야 하는데, GET메서드를 사용하기 어려운 경우
-> 애매하면 POST
PUT
-
리소스 대체의 목적으로 리소스가 있을 경우 대체, 없을 경우 생성한다.
- (쉽게 이야기해서 리소스를 완전히 대체한다고 이해하자) -
특정 리소스를 식별하기에 POST와는 구별점을 가진다.
즉 클라이언트가 리소스 위치를 알고 URI를 지정한다.
ex)PUT/members/100 HTTP/1.1
PATCH
- 리소스 부분 변경
- PUT과 비슷해 보이고 보내는 양식도 비슷하지만, 대체가 아닌 필요한 부분만 없데이트하는 방식이다.
DELETE
- 리소스를 제거할 때 사용한다.
- 리소스 식별자를 DELETE로 보낼 경우 해당 리소스를 삭제한다.
HTTP 메서드의 속성
- 안전(safe Methods)
- 멱등(Idempotent Methods)
- 캐시가능(Cashable Methods)
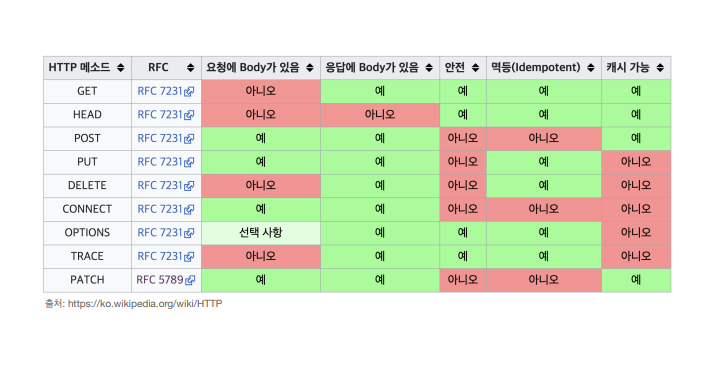
안전(safe Methods)
- 호출해도 리소스가 변경되지 않는다.
- GET, OPTIONS, TRACE등은 조회의 성경을 가지고 있기에 리소스를 변경하지 않고, 그렇기에 안전하다.
- 이때 안전의 범위는 해당 리소스에만 해당되며 그 외적인 요소는 고려하지 않는다.
--> 리소스 호출시마다 로그가 남는다 하여도 이는 리소스에 대한 영향은 아니기 때문에 고려하지 않는다.
멱등(Idempotent Methods)
-
메서드를 반복해서 호출하더라도 결과가 동일해야 한다.
-
GET, PUT, DELETE같은 경우 여러번 호출하더라도 GET같은 데이터를 조회, PUT은 대체된 값을 반환하기에 동일, DELETE도 결과를 삭제하기에 같은 요청을 하더라도 삭제된 내용이 복구되지는 않기에 멱등성을 성립한다.
-
POST의 경우 회원 등록을 두번하거나 주문을 두번할 경우 에러가 발생하거나 주문 중복이 생길 수 있기 때문에 멱등성이 성립하지 않는다.
멱등은 외부 요인으로 중간에 리소스가 변경되는 것까지 고려하지는 않는다.
캐시 가능(Cashable Methods)
캐시는 뒤에서 자세히 공부할꺼야.
- 표에서는 GET, HEAD, POST, PATCH가 캐시 가능이라 되있지만, 실제로는 GET, HEAD정도만 캐시로 사용된다.
- POST, PATCH는 본문 내용(Message Body)까지 캐시 키로 고려해야 하는데 구현이 쉽지 않다!
