멀티 스레드를 공부하면서 자주 접하는 동시성(concurrency)과 병렬성(parallelism)에 대해 공부하다 보니 점점 양이 많아져 정리해 보려고 합니다.
동시성과 병렬성


동시성(Concurrency)
작업이 동시에 발생하는 것처럼 보이기 위해 번갈아 가면서 작업을 수행하는 것.
병렬성(Parallelism)
실제로 독립적으로 동시에 작업을 수행하는 것.
Java에서의 동시성과 병렬성
멀티 스레드 환경인 자바에서는 이 동시성과 병렬성에서 어떤 문제가 있고 어떻게 해결할까요?
멀티 스레드에서는 공유 자원에 동시에 여러 스레드가 접근할때, 공유 자원이 변경되어 다른 스레드 작업에 영향을 미쳐 올바른 결과를 반환하지 못하게 됩니다. 이를 동시성 문제라고 합니다.
자바에서는 이런 동시성 문제를 해결해주기 위해 여러가지 방법을 제공해주고 있습니다.
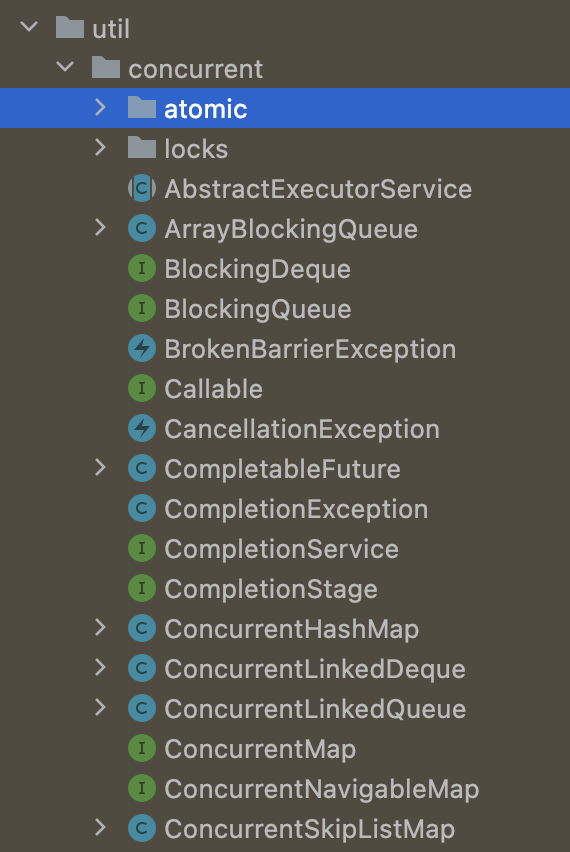
자바에서 제공해주는 concurrent 패키지의 일부분입니다. aotmic패키지도 있고 Thread-Safe하면 많이 알고있는 ConcurrentHashMap도 여기에 구현되어있었군요.
동시성
synchronized
공유 자원을 사용하려고 하는 경우 동시성 문제를 해결하기 위해 synchronzied를 사용해주게 되면 해당 객체에 락을 걸어주어 다른 스레드의 접근을 제한해주어 Thread-Safe하게 객체를 사용할 수 있게 됩니다.
public class synchronizedTest {
public static void main(String[] args) {
SyncClass sc = new SyncClass();
System.out.println("start");
new Thread(()->{
for(int i=0;i<100;i++){
try {
sc.checkSync(i);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}).start();
new Thread(()->{
for(int i=0;i<100;i++){
try {
sc.checkSync(i);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}).start();
System.out.println("end");
}
static class SyncClass{
int shareSource = 0;
public synchronized void checkSync(int source) throws InterruptedException { //synchronized 적용
this.shareSource = source;
Thread.sleep((long)(Math.random()*100));
System.out.println("shareSource : "+shareSource+" / source : "+source);
if(this.shareSource != source) {
// System.out.println("shareSource : "+shareSource+" / source : "+source);
System.out.println("동기화 실패");
}
}
}
}
가장 일반적인 방법이긴하지만, 동기화 처리에 많은 비용이 발생한다고 합니다.
Atomic
특정 타입을 감싸고 있는 Wrapper클래스로서, 여러 스레드에서 쓰기 작업을 해도 동시성을 보장합니다.
Synchronized는 스레드가 사용하는 특정 블럭에 락을 걸어 blocking을 발생시키고, 접근하려는 스레드는 아무작업을 하지 못하고 대기하여 성능이 저하될수 있습니다.
Atomic은 Nonblocking하면서 Synchronized보다 저렴하게 동기화 문제를 해결해 줄 수 있다. 대표적으로 AtomicInteger가 있습니다.
AtomicInteger는 CAS(Compare And Swap)을 이용해 동시성 문제를 해결해 주게 됩니다.
CAS (Compare And Swap)
CAS란, 스레드가 가지고 있는 값(캐시)과 메인 메모리가 가지고 있는 값이 동일한 경우에만 새로운 값을 적용하는 방법입니다.
즉, CPU의 도움을 받아 하나의 스레드만 값을 변경할 수 있도록 제공합니다.
AtomicInteger의 incrementAndGet메서드를 살펴보겠습니다.
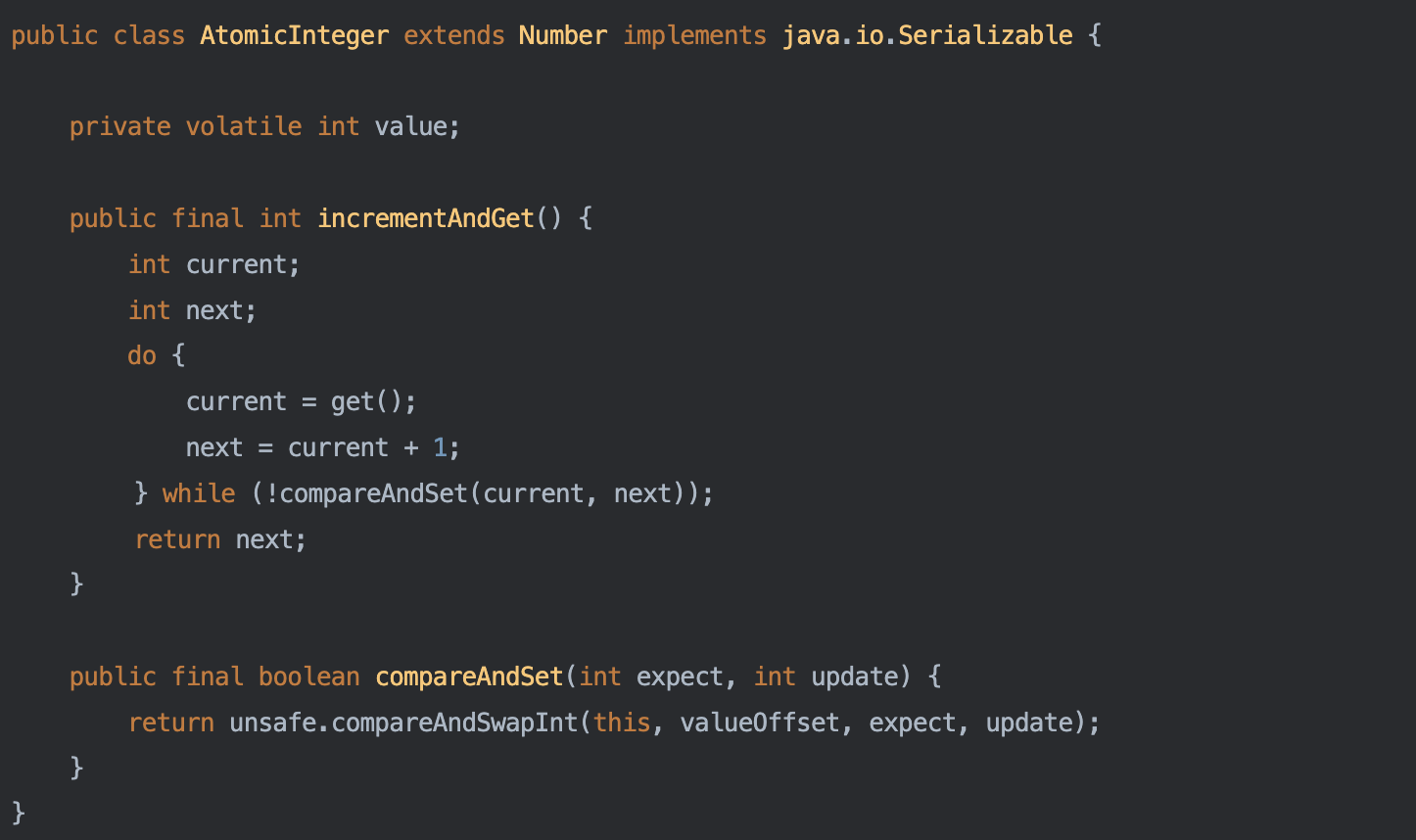
해당 메서드를 가독성 좋게 요약해주신게 있어서 해당 코드로 대체하겠습니다.
- incrementAndGet
어떤 스레드가 incrementAndGet메서드를 요청했을 경우, AtomicInteger에서 현재값을 가져온 current와 다음 변경할 값인 next를 가지고 comapreAndSet메서드가 true를 반환할때까지 반복합니다. - compareAndSet
스레드가 가지고 있는 값과 메인 메모리에 있는 값과 비교하여 동일 한지 여부를 판단합니다.
compareAndSwap이라는 메서드를 사용하는 것을 확인할 수 있습니다.
이를 통해 메인 메모리에 있는 값과 동일한 값을 가지고 있는 하나의 스레드만이 증가된 next값을 적용하는 걸 보장해주게 됩니다.
Volatile
위의 요약 코드에서 보면 volatile이라는 선언이 있습니다.
Volatile은 캐시가 아닌 메인 메모리에서 값을 참조하는 방법을 사용합니다.
일반적으로 스레드는 CPU에 데이터를 캐시하여 캐시된 데이터를 참조하여 사용하게됩니다.
만약 여러 스레드가 쓰기 작업을 한다면.. 다른 스레드가 작업한 결과를 현재 스레드에서는 다른 값을 가지고 있다는것입니다. 이러한 문제를 가시성 문제라고 합니다.
각 스레드는 각 코어에 캐시되어있는 데이터를 참조하고 메인 메모리값과 다른 값을 가져 동시성 문제가 발생할 것입니다.
즉, 캐시로 인해 동시성 문제가 발생하게 되는것입니다.
Volatile을 사용하게된다면 해당 자원에 대해 캐시값이 아닌 메인 메모리에 있는 최신값을 참조하기 때문에 가시성 문제가 해결됩니다.
그리고 동시성 문제도 해결될까요?
Volatile은 하나의 스레드에서 쓰기 작업을, 나머지 스레드에서는 읽기 작업을 할 경우, 안정성을 보장할 수 있습니다.
만약 여러 스레드에서 동시에 쓰기작업을 하게된다면, 특정 스레드가 작업을 위해 메인 메모리에서 데이터를 가져오고 작업을 하려는 순간, 다른 스레드에서 변경되지 않은 값을 가져오게되면 이 두개의 스레드는 같은 값에 대한 작업을 수행하게됩니다.
이를 해결하기 위해서는 Atomic한 연산자를 통해 동시성 문제를 해결해주어야합니다.
Synchronized, Atomic, Volatile을 정리하자면
- synchronized
- 대상 객체에 락을 걸어주어 동시성 문제를 해결해주지만 blocking방법이기 때문에 병목현상이 발생할 수 있고 많은 비용이 발생합니다.
- Atomic
- 캐시 메모리와 메인 메모리의 값을 비교하여 동일한 경우 새로운 값을 할당해주어 여러 스레드에서 쓰기 작업을 하여도 동시성 문제를 해결해 줄 수 있습니다. 또한 synchronized보다 저렴합니다.
- Volatile
- 메인 메모리의 값을 참조하는 것으로서, 하나의 스레드가 쓰기작업, 나머지 스레드는 읽기 작업시 안정성을 보장해 줄 수 있습니다.
Thread-Safe 자료구조
자바에서는 동시성 문제를 해결해주기 위해 concurrent 패키지를 준비해주었습니다. 그리고 직접 synchronized, atomic, volatile을 사용하지 않아도 이미 Thread-Safe하게 작업을 처리해 줄수 있는 자료구조를 제공합니다.
대표적으로 ConcurrentHashMap이 있습니다.
ConcurrentHashMap은 HashMap과 동일하게 key,value형태로 값을 저장하는 자료구조입니다.
차이점이라면 쓰기작업은 동기화 작업을 해주지만, 읽기작업은 동기화를 보장해주지 않습니다.
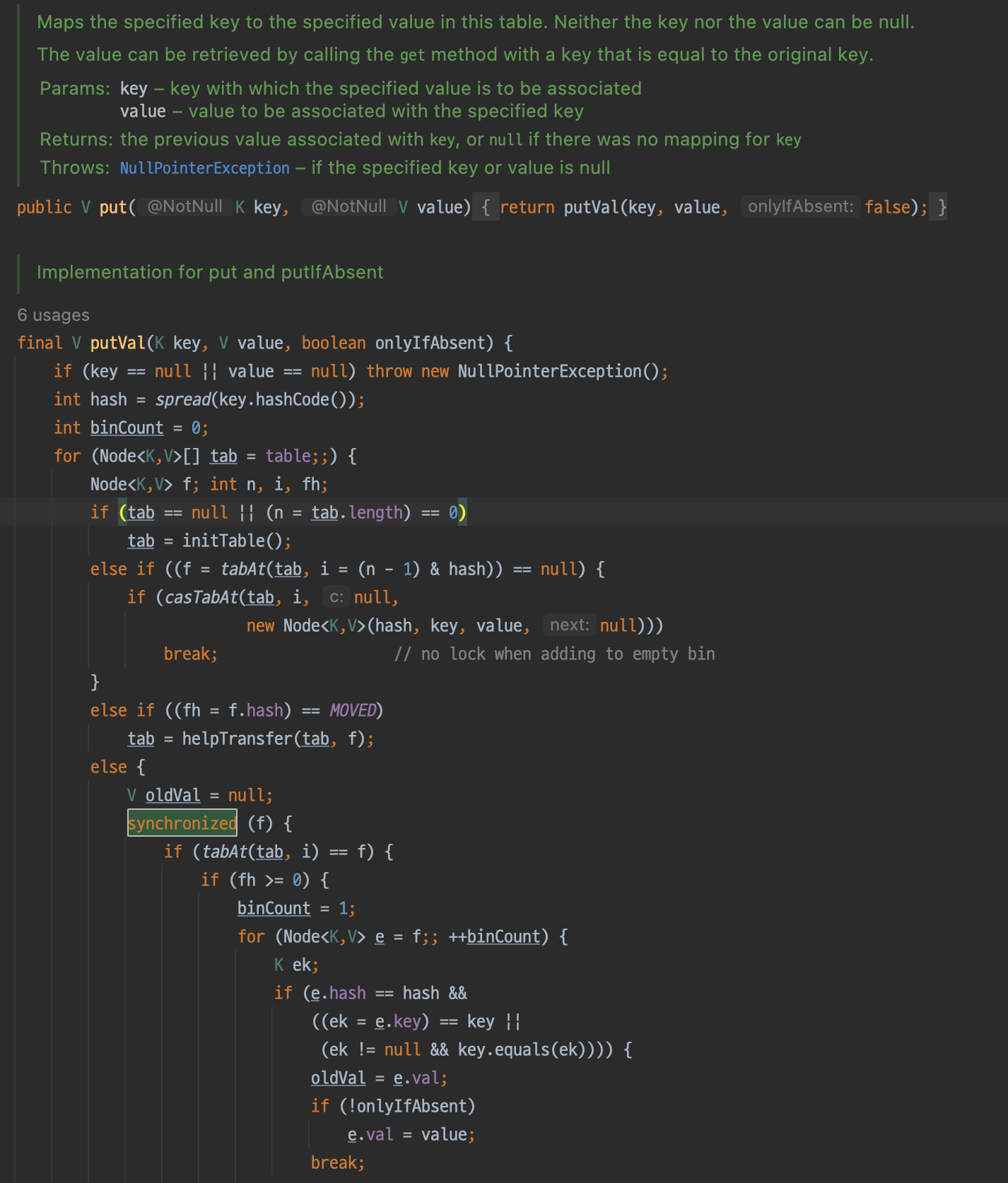
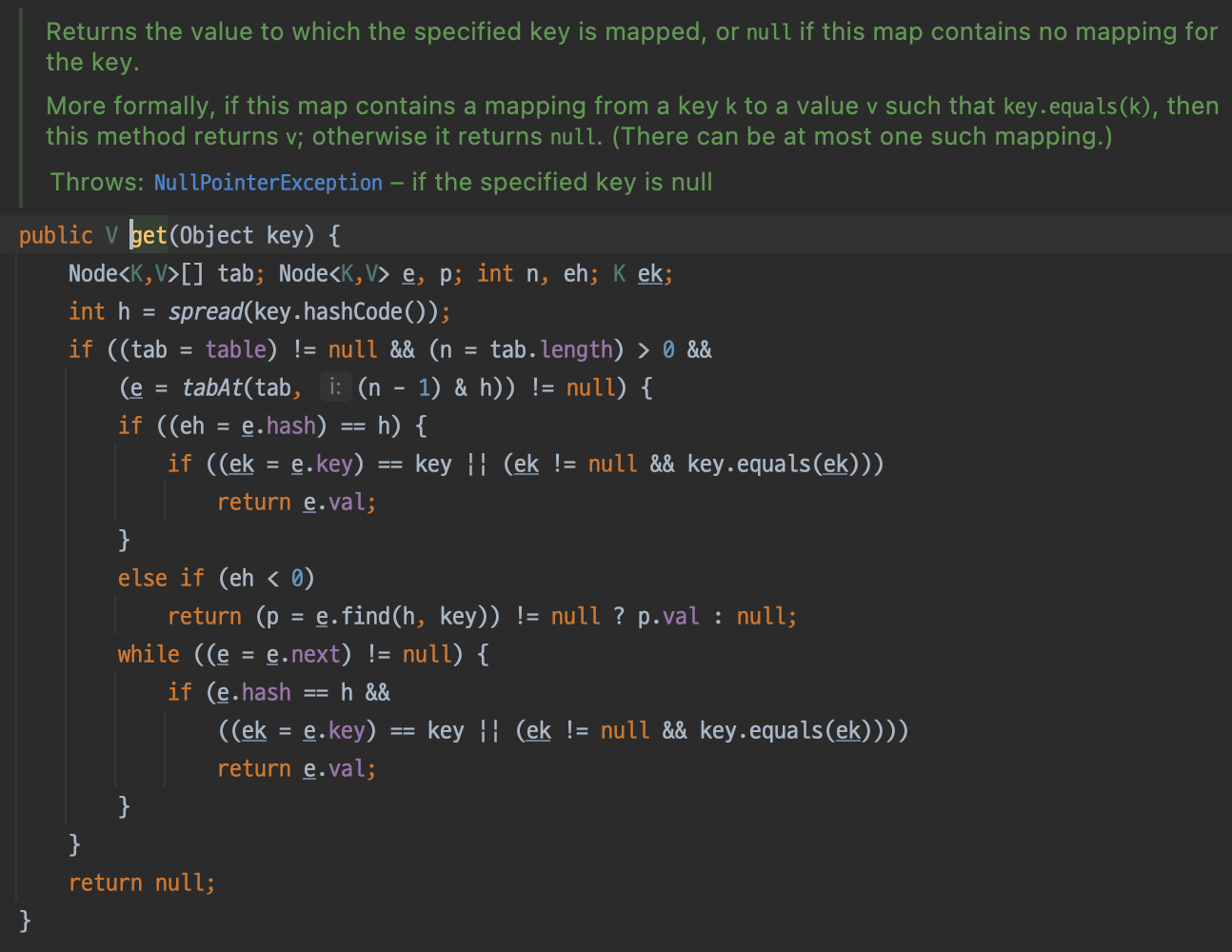

ConcurrentHashMap의 쓰기 작업인 put()을 살펴보시면, 테이블 값이 있는 경우, synchronized block을 통해 해당 Node에 락을 걸어주는 것을 확인할 수 있습니다.
또한 읽기 작업인 get(), containsValue()를 살펴보시면, 별도의 동기화 코드가 없는 것을 확인할 수 있습니다.
그렇기 때문에 멀티 스레드 환경에서 좀 더 효율적인 성능을 보장할 수 있습니다.
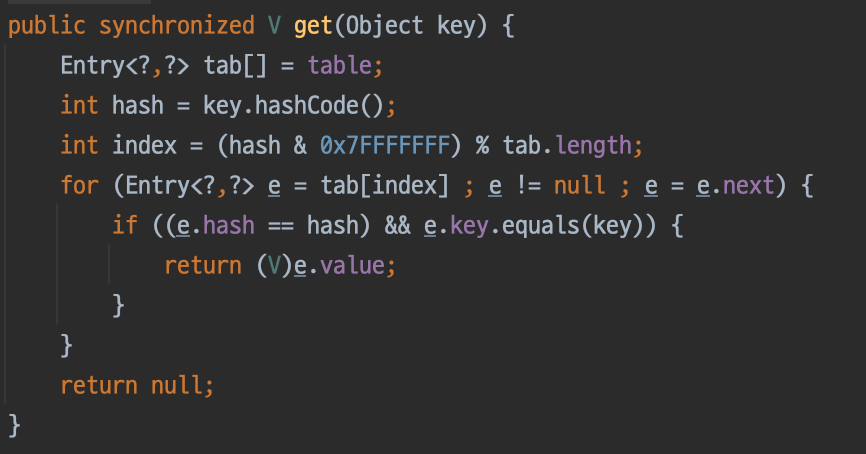
참고로, 비교대상으로 HashTable이 있습니다. HashTable은 쓰기작업 뿐만 아니라, 읽기 작업에서도 락을 걸어주게됩니다. 그리고 synchronized block이 아닌 synchronized를 선언함으로서 객체 전체에 락을 걸어줍니다.
그렇기 때문에 ConcurrentHashMap과 비교했을때, 상대적으로 성능이 저하될수 있습니다.
Immutable Instance
동시성 문제를 해결해줄수 있는 또다른 방법은 불변객체입니다.
불변객체이란, 한번 할당된다면 내부 데이터를 변경할 수 없고, 재할당만 가능한 객체를 말합니다.
대표적으로 String이 있습니다.
String을 선언하는 방법에는 new를 이용한 객체 생성과 ""을 이용한 리터럴 생성방법이 있습니다.
자바에서는 객체를 런타임 시점에 생성하게되면 Heap메모리에 저장되게 됩니다. new를 통한 객체 생성은 Heap영역에 저장되게 됩니다. 하지만 리터럴로 생성한 객체는 Heap영역의 String Pool영역에 저장되게 되는데, String Pool에 저장된 문자열은 Immutable이기 때문에 다른 스레드에서 해당 문자열을 변경할 수 없고 재할당을 해야합니다.
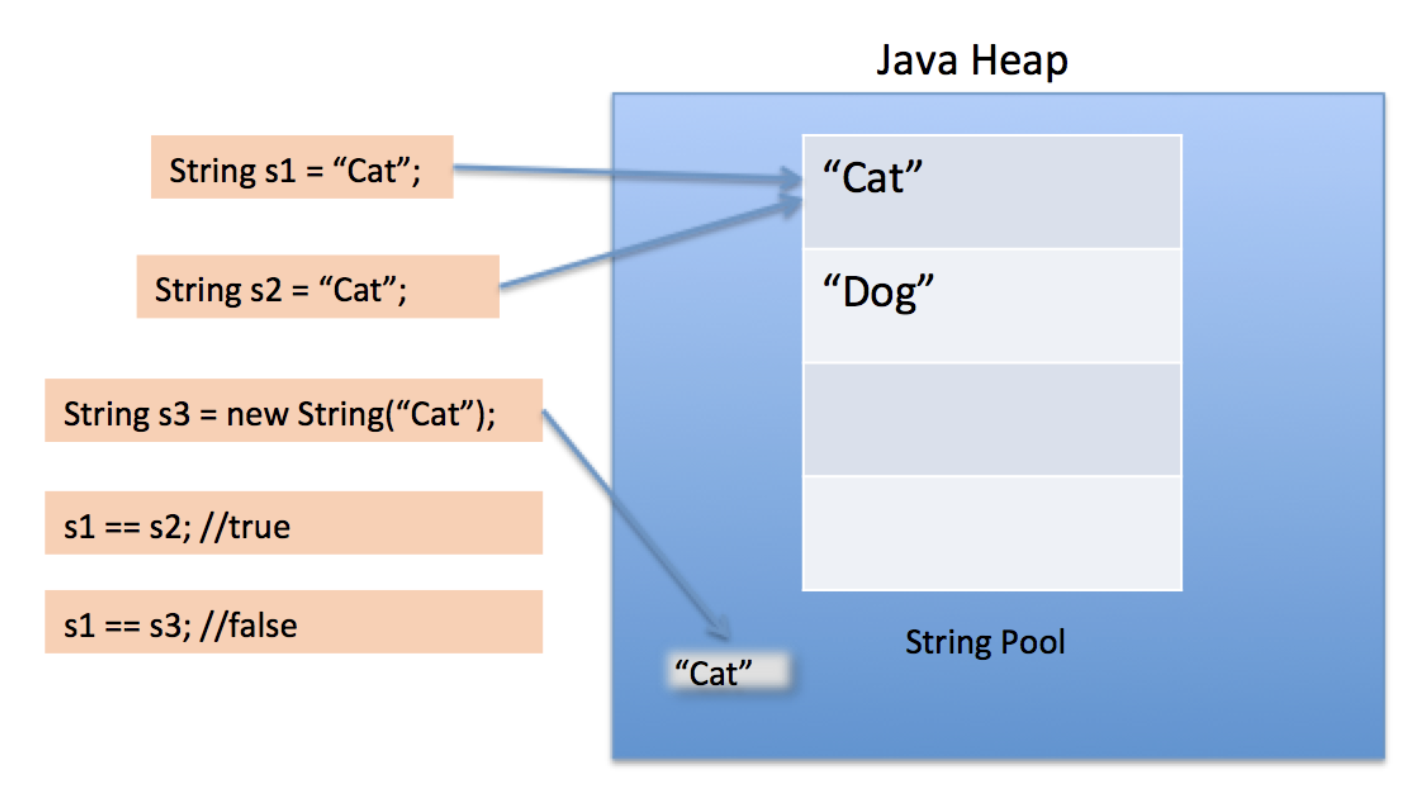
출처 : https://starkying.tistory.com/entry/what-is-java-string-pool
이러한 불변 객체는 멀티 스레드 환경에서 다른 스레드가 불변 객체를 변경하더라도 내부 값은 변경되지 않기때문에, 다른 스레드에 영향을 받지 않아 동시성 문제를 해결해 줄수 있습니다.
다만 주의할 점은 불변 객체의 내부 데이터를 변경할 수 없도록 구성해야합니다. 즉, 접근 제어자를 상황에 맞게 선언하고 setter와 같은 메서드를 지양해야 합니다.
병렬성
Parallel
자바에서 병렬처리를 제공해주는 기능 중 하나는 Stream의 Parallel이 있습니다.
Stream내부 요소를 Fork-Join을 이용하여 병렬 처리합니다.
public class Main{
ExecutorService executorService = Executors.newFixedThreadPool(5);
List<Future<String>> futures = new ArrayList<>();
for(int i=0;i<10;i++){
final int index = i;
futures.add(executorService.submit(()->{
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return Thread.currentThread().getName()+" id - "+index+" / date - "+new Date();
}));
}
for(Future<String> future : futures){
System.out.println(future.get());
}
}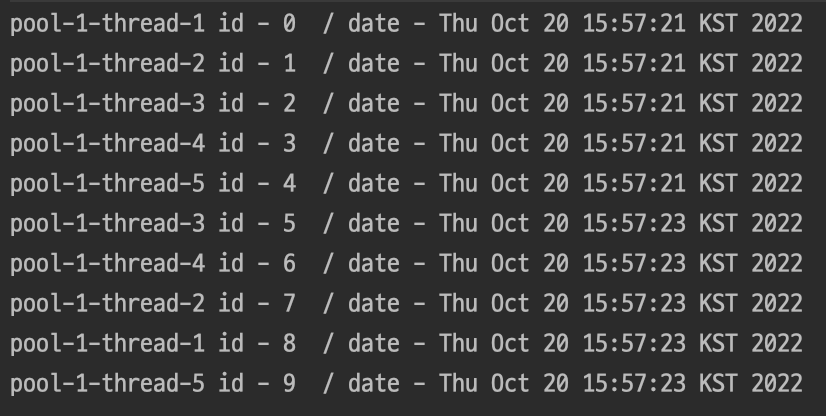
일반적인 ThreadPool을 사용한 경우는 위와 같습니다.
IntStream.range(0,10).parallel().forEach((index)->{
System.out.println(Thread.currentThread().getName()+" id - "+index+" / date - "+new Date());
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});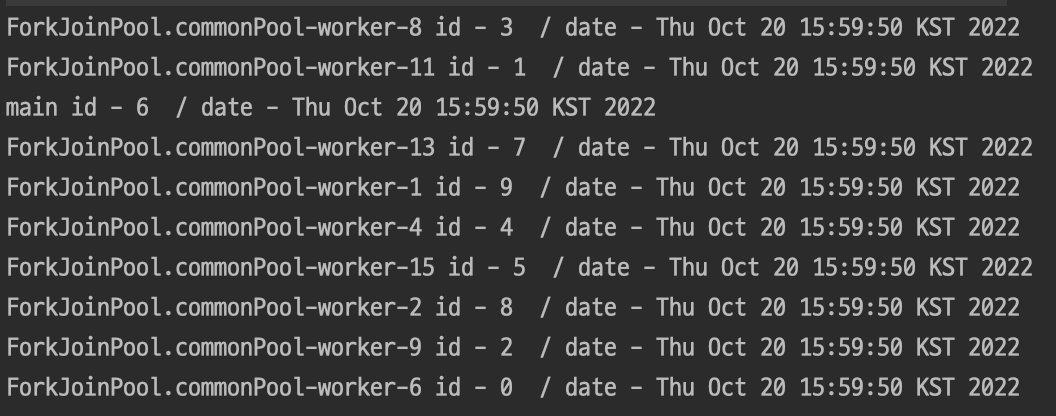
Stream의 parallel을 사용하니 ForkJoinPool의 commonPool의 스레드를 사용하는 것을 확인할 수 있습니다.
병렬 Stream처리를 할때 사용되는 Fork-Join이란 무엇일까요?
Fork-Join
Fork-Join이란 하나의 작업을 여러 Task로 쪼개고 Fork-Join Pool에 있던 여러 스레드가 제귀적으로 Task을 Fork하고 쪼개는 과정을 반복하여 작업을 수행하게 됩니다.
그리고 작업을 마친 스레드는 결과를 취합(Join)하여 결과를 반환하는 병렬처리 방법입니다.
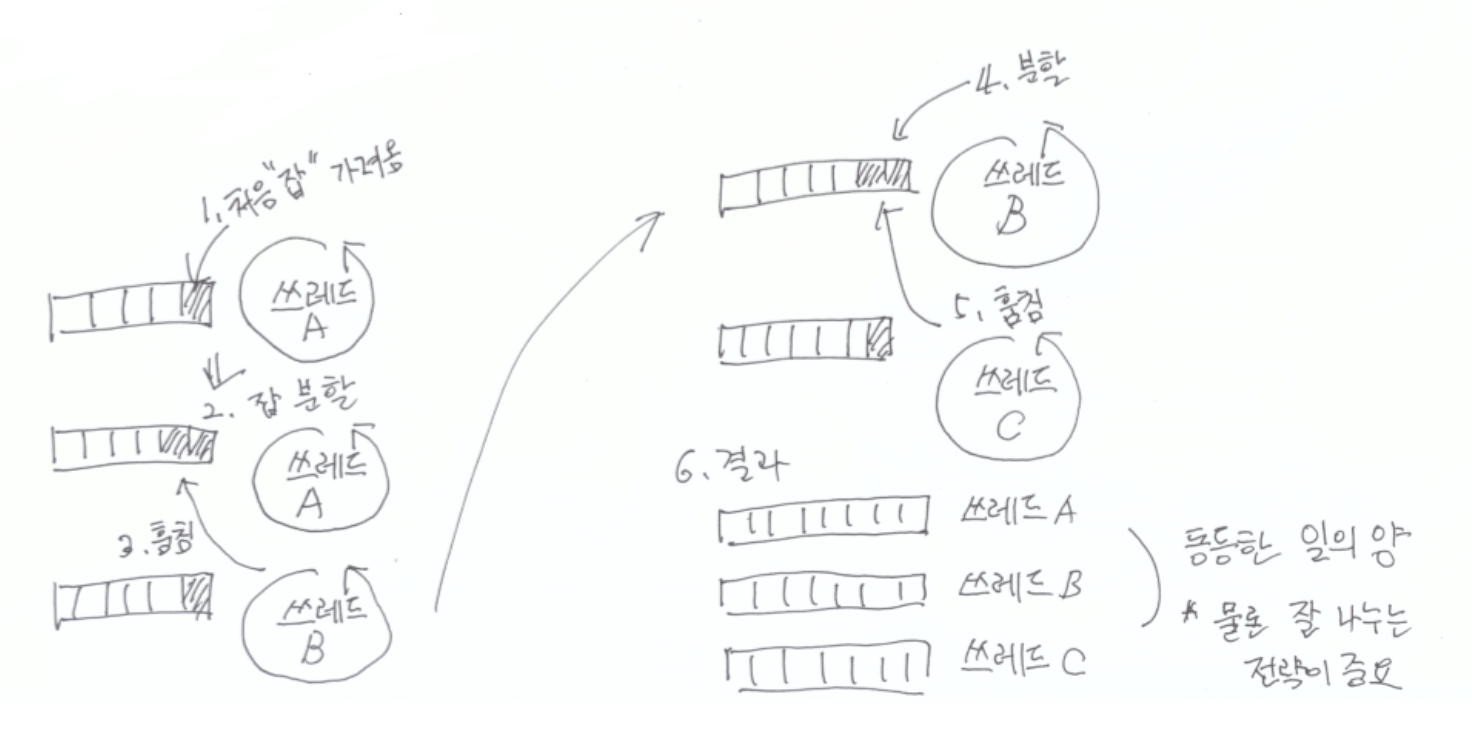
Fork-Join을 한번에 이해시켜준 그림입니다.
- ThreadPool 크기 제어
java.util.concurrent.ForkJoinPool.common.parallelism Property를 이용해System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","6")으로 pool size를 조절할 수 있습니다.- 하지만 Fork-Join Pool의 commonPool에 영향을 줄 수 있기 때문에, 권장하지 않는 방법입니다.
ForkJoinPool forkjoinPool = new ForkJoinPool(5)을 이용하여 커스텀 Fork-Join Pool을 사용할 수 있습니다.
- Stream 종류
- 장점
- Fork-Join Pool에 있는 스레드를 이용하여 동등하게 작업을 병렬처리 할 수 있습니다.
- 작은 Task가 많은 경우 효과적입니다.
- 단점
- Thread-Safe하지 않아 별도의 처리가 필요합니다.
- DeadLock이 발생할 수 있으며, 의도하지 않게 많은 스레드가 만들어질 수 있습니다.
- ThreadPool이 global하게 사용되기 때문에 어떤 메서드에서 병렬Stream을 사용하는 경우 다른 곳에서는 사용하지 못해 대기하는 문제가 발생할 수 있습니다.
- 주의사항
- 독립되지 않는 작업은 병렬처리 하지 말것.
- stream의 중간 연산자에서 sort나 distinct는 각 작업들의 정보를 공유하고 있기 때문에 병렬처리는 비효율적입니다.
- 내부 요소의 개수가 적다면 순차처리가 더 효율적입니다.
- 싱글코어보다는 멀티코어인 경우 더 효율적입니다.
- 독립되지 않는 작업은 병렬처리 하지 말것.
Reference
https://tourspace.tistory.com/54
https://javaplant.tistory.com/23
https://seamless.tistory.com/42
https://readystory.tistory.com/53
https://www.popit.kr/java8-stream%EC%9D%98-parallel-%EC%B2%98%EB%A6%AC/
https://wonyong-jang.github.io/java/2021/02/07/Java-Stream-parallel.html
