Spring Batch Multi Thread 모델
Spring Batch에서는 일반적으로 단일 스레드로 배치 작업을 수행합니다. 즉, 순차적으로 작업을 실행해주게 됩니다. 하지만 여러 작업들을 병렬적으로 처리하여 빠르게 처리하기 위해 Spring Batch에서는 여러 Multi Thread 모델을 제공해주고 있습니다.
AsyncItemProcessor / AsycnItemWriter- ItemProcessor에게 별도의 스레드를 할당하고 비동기적으로 처리하는 방식
Multi Thread Step- Step내에서 Chunk구조인 ItemReader, ItemProcessor, ItemWriter에서 멀티 스레드를 통해 작업을 처리하는 방식
Parallel Step- 여러 Step이 있을때 각 Step에 스레드를 할당시켜 병렬적으로 처리하는 방식
Partition- Master/Slave 방식으로 Master가 데이터를 파티셔닝하고 각 파티션에게 스레드를 할당하여 Slave가 독립적으로 작동하는 방식
Remote Chunking- 분산 환경처림 Step처리가 여러 프로세스로 분할되어 외부 다른 서버로 전송되어 처리하는 방식
AsyncItemProcessor / AsycnItemWriter
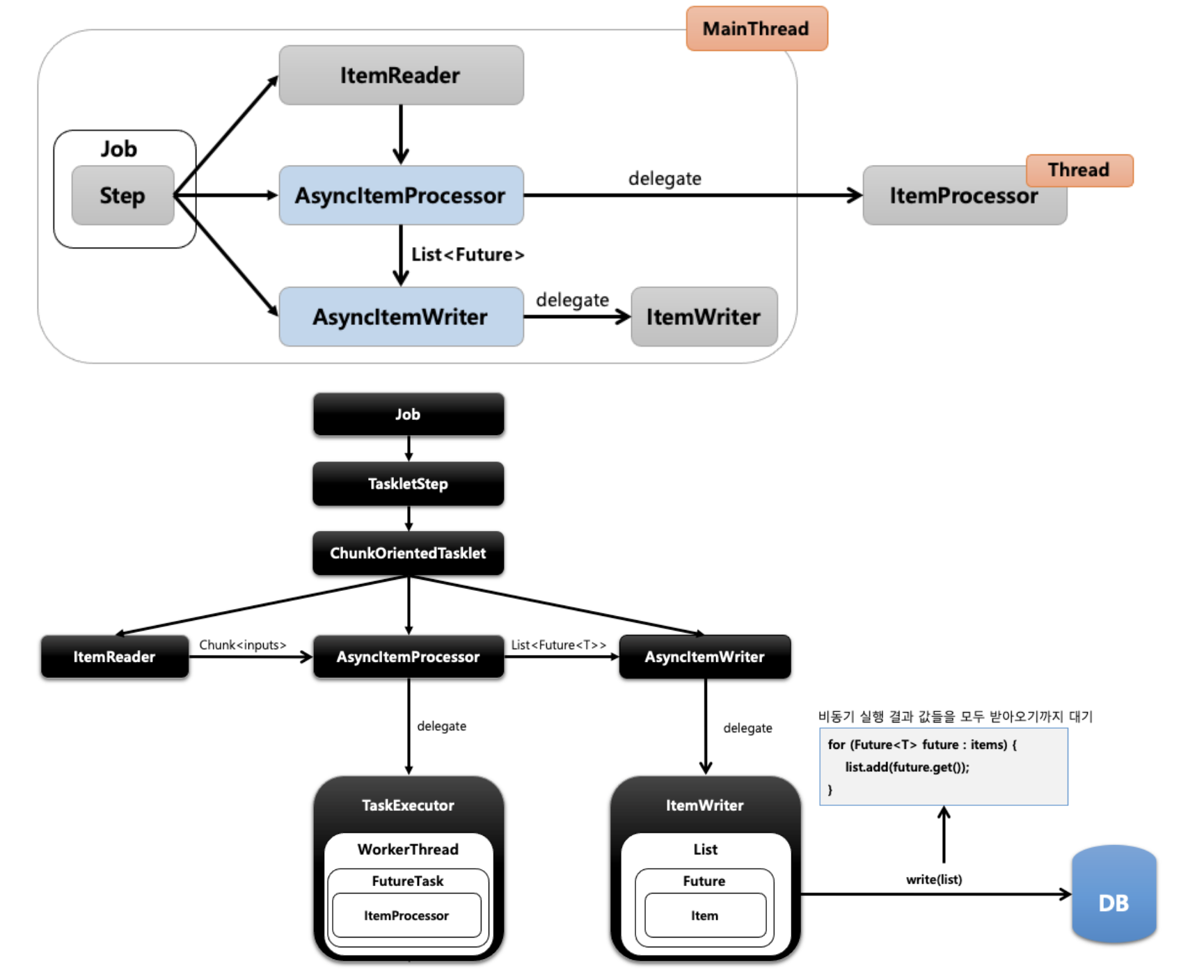
- AsyncItemProcessor가 ItemProcessor에게 작업을 위임하여 비동기적으로 동작하는 구조
- AsyncItemProcessor의 결과는
List<Future<?>>으로 반환 - ItemProcessor에게 작업을 위임하고 메인 스레드는 다음 작업을 수행
- AsyncItemWriter에서 AsyncItemProcessor의 작업이 완료될때까지 대기하고 받아온 Futre에 있는 Item을 읽어오는 작업 수행
Step 설정

- Step설정
- chunk size
- ItemReader설정
- AsyncItemProcessor를 적용한 ItemProcessor 설정
- AsyncItemWriter를 적용한 ItemWriter 설정
- Step빌드
그리고 의존성 추가가 필요합니다.
implementation 'org.springframework.batch:spring-batch-integration'
@Configuration
@RequiredArgsConstructor
public class HelloJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final DataSource dataSource;
private final EntityManagerFactory entityManagerFactory;
private int chunkSize = 10;
@Bean
public Job helloJob() {
return jobBuilderFactory.get("job")
.start(step1())
.incrementer(new RunIdIncrementer())
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step")
.<Customer, Future<Customer2>>chunk(chunkSize) // Future 타입
.reader(customItemReader())
.processor(customAsyncItemProcessor())
.writer(customAsyncItemWriter())
.build();
}
@Bean
public ItemReader<? extends Customer> customItemReader() {
return new JpaPagingItemReaderBuilder<Customer>()
.name("customItemReader")
.pageSize(chunkSize)
.entityManagerFactory(entityManagerFactory)
.queryString("select c from Customer c order by c.id")
.build();
}
@Bean
public AsyncItemProcessor<Customer, Customer2> customAsyncItemProcessor() {
AsyncItemProcessor<Customer, Customer2> asyncItemProcessor = new AsyncItemProcessor<>();
asyncItemProcessor.setDelegate(customItemProcessor()); // customItemProcessor 로 작업 위임
asyncItemProcessor.setTaskExecutor(new SimpleAsyncTaskExecutor()); // taskExecutor 세팅
return asyncItemProcessor;
}
@Bean
public ItemProcessor<Customer, Customer2> customItemProcessor() {
return new ItemProcessor<Customer, Customer2>() {
@Override
public Customer2 process(Customer item) throws Exception {
return new Customer2(item.getName().toUpperCase(), item.getAge());
}
};
}
@Bean
public AsyncItemWriter<Customer2> customAsyncItemWriter() {
AsyncItemWriter<Customer2> asyncItemWriter = new AsyncItemWriter<>();
asyncItemWriter.setDelegate(customItemWriter()); // customItemWriter로 작업 위임
return asyncItemWriter;
}
@Bean
public ItemWriter<Customer2> customItemWriter() {
return new JdbcBatchItemWriterBuilder<Customer2>()
.dataSource(dataSource)
.sql("insert into customer2 values (:id, :age, :name)")
.beanMapped()
.build();
}
}별도의 작업없이 기존의 ItemProcessor와 ItemWriter에 AsyncItemProcessor와 AsyncItemWriter를 적용하여 각각 setDelegate를 통해 작업을 위임해주면 됩니다.
Multi Thread Step
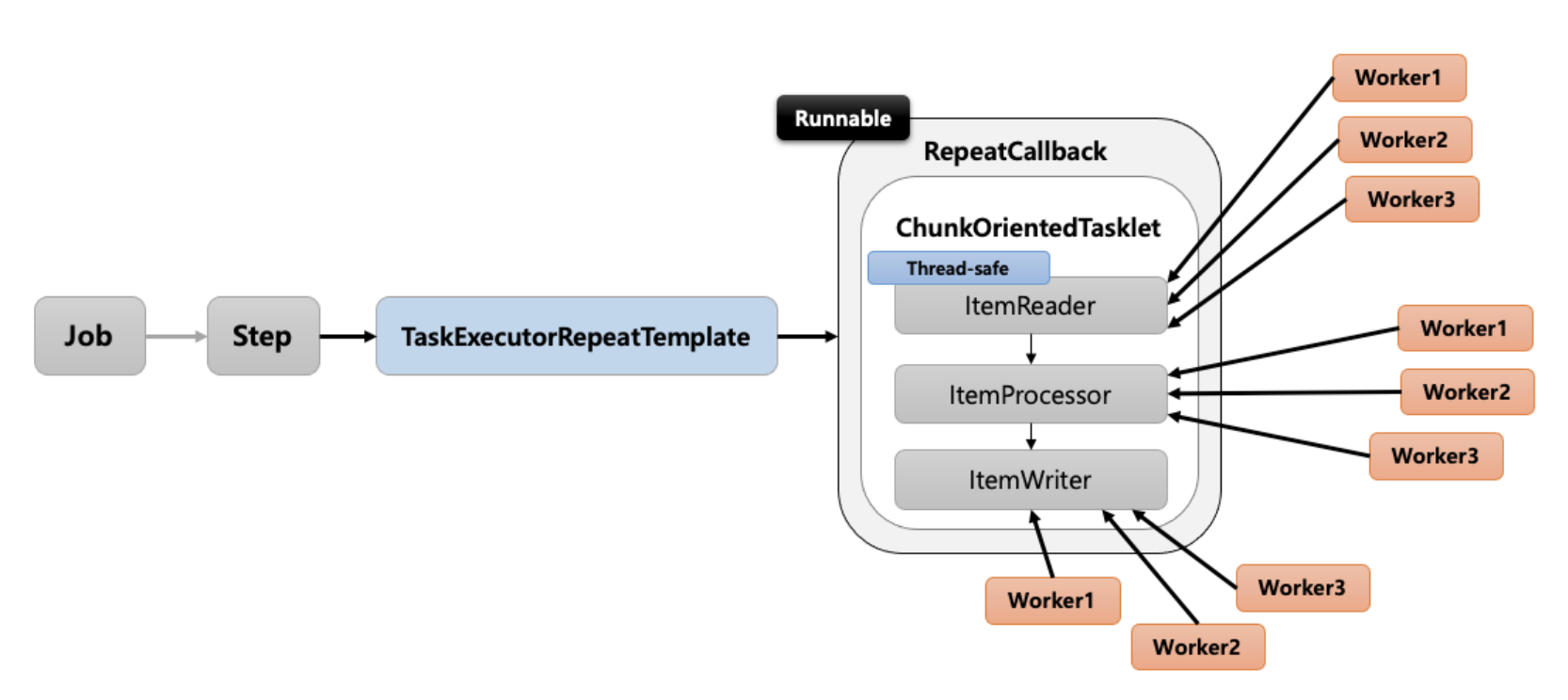
- Step내에 Chunk구조인 ItemReader, ItemProcessor, ItemWriter마다 여러 스레드가 할당되어 실행하는 방식.
즉, Step내에서 멀티스레드로 Chunk기반 처리가 이루어지는 구조 - TaskExecutorRepeatTemplate가 반복자로 사용되고 사용할 스레드 개수(throttLimit)만큼 스레드를 생성하여 수행
주의사항
- ItemReader, ItemWriter가 Thread-Safe한지 확인해야합니다.
- Spring Batch에서 제공하는 PagingItemReader를 상속받는 구현체는 모두 Thread-Safe입니다. (JpaPagingItemReader, HibernatePagingItemReader, JdbcPagingItemReader)
- JpaItemWriter, HibernateItemWriter, JdbcBatchItemWriter는 Thread-Safe입니다.
- 멀티스레드로 각 Chunk들이 개별적으로 수행되기 때문에 실패지점에서 재시작이 불가능 합니다.
- 단일스레드로 작업시 10개의 작업이 있을때 8번째 작업에 문제가 발생하면 이전의 7번째까지의 작업은 정상 처리되었다는 뜻입니다. 그래서 8번째부터 작업을 재시작할 수 있습니다.
- 하지만 Chunk별로 작업이 수행되기 때문에 8번째 작업에 문제가 생겨도 이전의 작업의 정상 처리 여부를 알 수 없습니다.
그래서 ItemReader의 설정에서saveState(false)의 설정을 추가해주어야 합니다.
@Bean(name = JOB_NAME+"taskPool")
public TaskExecutor executor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); // (1)
executor.setCorePoolSize(poolSize);
executor.setMaxPoolSize(poolSize);
executor.setThreadNamePrefix("multi-thread-");
executor.setWaitForTasksToCompleteOnShutdown(Boolean.TRUE); // (2)
executor.initialize();
return executor;
}
@Bean(name = JOB_NAME)
public Job job() {
return jobBuilderFactory.get(JOB_NAME)
.start(step())
.preventRestart() //실패한 Job인 경우 재실행 가능 막기
.build();
}
@Bean(name = JOB_NAME +"_step")
@JobScope
public Step step() {
return stepBuilderFactory.get(JOB_NAME +"_step")
.<Product, ProductBackup>chunk(chunkSize)
.reader(reader(null))
.processor(processor())
.writer(writer())
.taskExecutor(executor()) // (3)
.throttleLimit(poolSize) // (4)
.build();
}
@Bean(name = JOB_NAME +"_reader")
@StepScope
public JpaPagingItemReader<Product> reader(@Value("#{jobParameters[createDate]}") String createDate) {
Map<String, Object> params = new HashMap<>();
params.put("createDate", LocalDate.parse(createDate, DateTimeFormatter.ofPattern("yyyy-MM-dd")));
return new JpaPagingItemReaderBuilder<Product>()
.name(JOB_NAME +"_reader")
.entityManagerFactory(entityManagerFactory)
.pageSize(chunkSize)
.queryString("SELECT p FROM Product p WHERE p.createDate =:createDate")
.parameterValues(params)
.saveState(false) // (5)
.build();
}
private ItemProcessor<Product, ProductBackup> processor() {
return ProductBackup::new;
}
@Bean(name = JOB_NAME +"_writer")
@StepScope
public JpaItemWriter<ProductBackup> writer() {
return new JpaItemWriterBuilder<ProductBackup>()
.entityManagerFactory(entityManagerFactory)
.build();
}- Step에서 Chunk구조를 멀티스레드로 수행하기 위해 별도의 Tasklet을 추가해주기 위해 ThreadPool을 생성해주는 ThreadPoolTaskExecutor생성
- setWaitForTasksToCompleteOnShutdown()은 진행중이던 작업이 완료된 후 Thread 종료 설정
- setAwaitTerminationSeconds() : 작업을 마칠 때까지 기다려주는 시간
- (1)에서 생성한 TaskExecutor를 Step에 세팅한다.
- Step에서 작업을 수행할때 실제 작업에 사용될 스레드 개수 설정
- 10개의 스레드가 만들어져있을때 4개의 throttleLimit으로 설정되어 있다면, 4개의 스레드만 사용한다.
- corePoolSize = maximumPolSize = throttleLimit을 모두 같은 값으로 맞춰줍니다.
- .saveState(false)
- 해당 옵션을 true로 해놓는다면 Reader가 실패지점을 저장하고 재실행시 돌아가 다음 실행시 실패지점부터 다시 읽도록 합니다.
- false로 설정한다면 Reader가 실패한 지점을 저장하지 않습니다.
- 멀티 스레드 환경에서는 병렬적으로 작업을 수행하기 때문에 특정 지점에 문제가 발생했어도 순차적으로 수행되었다는 보장이 없어 재시작 지점이 오염될 수 있습니다.
- 재실행을 막아주는 옵션은 JobBuilder의 preventRestart()옵션이 있습니다.
예시
만약 chunksize=1, poolsize = 2이고 읽어와야할 데이터가 10개라면, 작업을 수행하는데 2개의 스레드가 사용되고 각 스레드는 1개의 데이터씩 읽어오기 때문에 총 5번의 (Read,Proccess,Write) 작업이 수행됩니다.
No Thread Safe ItemReader를 사용할경우
PagingItemReader의 구현체는 모두 Thread-Safe하여 멀티 스레드 작업을 안정적으로 수행해줄수 있습니다. 하지만 Thread-Safe하지 않는 ItemReader를 사용한다면, 중복된 데이터를 읽어오고 원치않은 결과가 발생할 수 있습니다.
(CursorItemReader 등..)
이렇게 Thread-Safe를 지원해주지 않는 ItemReader에서는 SynchronizedItemStreamReader를 통해 ItemReader를 한번 감싸주기만 한다면 Read작업이 synchronized메소드에 감싸져 호출되기 때문에 동기화된 읽기가 가능하게 됩니다.
Pararell Step
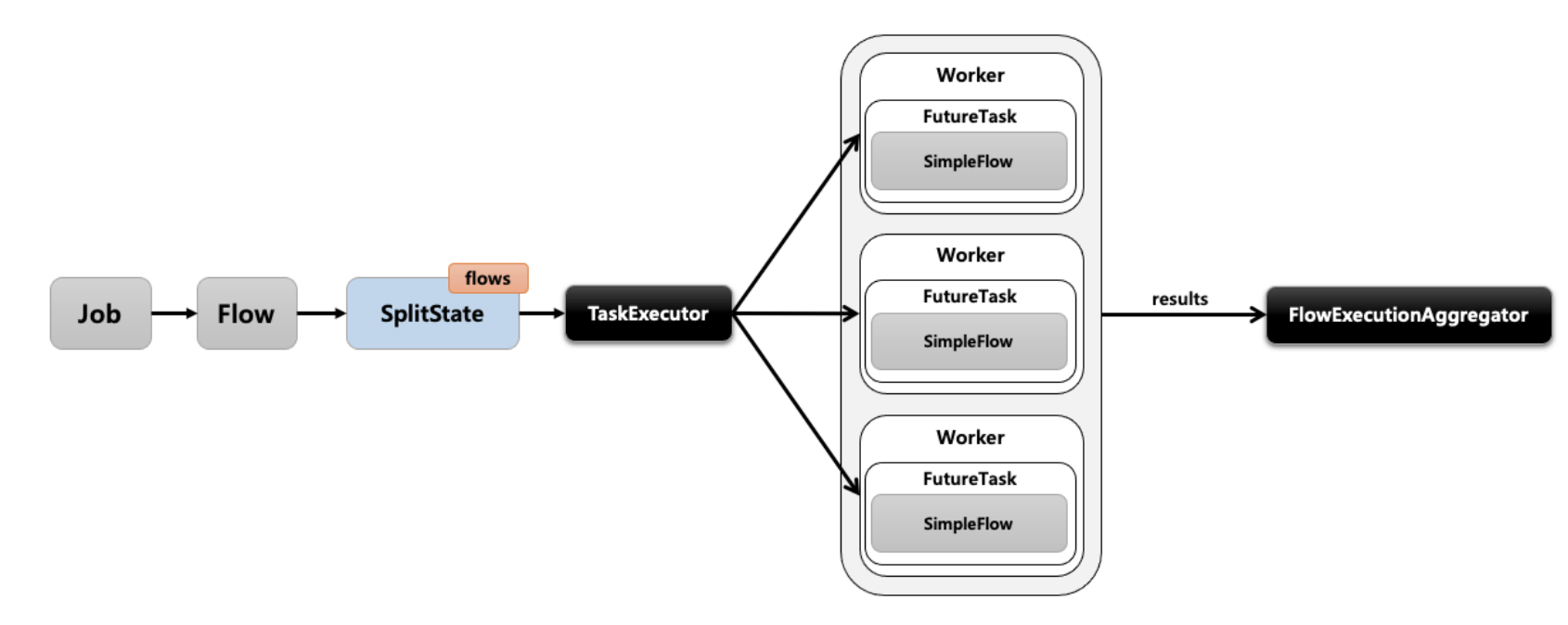
- 여러 Step이 있을때 각 Step에 스레드를 할당하여 병렬적으로 처리해주는 방식
- SplitState를 사용하여 여러 개의 Flow(Step)를 병렬적으로 처리
@Bean
public Job job(){
return jobBuilderFactory.get("job")
.start(splitFlow()) //(1)
.next(step4())
.build() //(4)
.build(); //(5)
}
@Bean
public Flow splitFlow(){
return new FlowBuilder<SimpleFlow>("splitFlow")
.split(taskExecutor()) //(2)
.add(flow1(), flow2()) //(3)
.build();
}
@Bean
public Flow flow1(){
return
}
@Bean
public Flow flow2(){
}
@Bean Step step4(){
}
@Bean
public TaskExecutor taskExecutor(){
return new SimpleAsyncTaskExecutor("spring_batch");
}- Step을 여러개의 Flow로 나누어 설정
- Step을 병렬로 처리해주기 위해 TaskExecutor 추가
- 병렬 작업해줄 Flow(Step)을 추가
- FlowBuilder의 build
- JobBuilderFactory build
Partition
Remote Chunking
Reference
