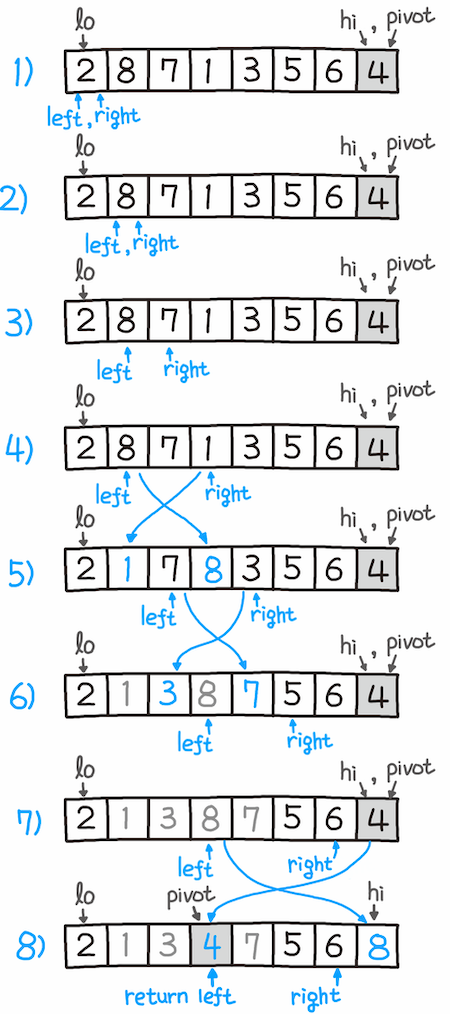
- 리스트에서 피벗(pivot)이 될 원소 하나를 선택한다.
- 피벗의 왼쪽에는 피벗보다 작은 값이, 피벗의 오른쪽에는 피벗보다 큰 값이 오게 한다.
(보통 투 포인터를 이용해 이 작업을 실행한다.)- 피벗을 파티션 삼아 피벗의 왼쪽과 오른쪽 서브 리스트에 대해 과정 1을 다시 수행한다.
특징
1.
다음과 같은 이유들로, 퀵 정렬은 대부분의 경우 다른 O(N log N) 알고리즘보다도 더 빠르게 동작한다.
- 매 사이클마다 적어도 1개의 원소(피벗)가 정렬되므로 이후 정렬할 데이터의 개수가 줄어든다.
(이는 퀵 정렬은 반드시 종료된다는 것을 입증하기도 한다.) - 다루는 데이터들의 지역성이 높아 캐시 히트율이 높다.
- 별도로 값을 복사하는 작업 없이 비교 연산만으로 데이터를 정렬한다.
2.

퀵 정렬의 성능은 파티션 계획법(피벗보다 작은[큰] 값을 왼쪽[오른쪽]으로 분류하는 방법)에 달려 있다.
가장 간단하고 쉬운 방식은 로무토 파티션 계획법으로, 항상 맨오른쪽의 값을 피벗으로 선택하는 것이다.
퀵 정렬은 최악의 경우 O(N^2)이 소요된다.
로무토 파티션 계획법에서 이미 정렬된 데이터가 입력되는 경우가 그에 해당한다. (위 그림의 오른쪽 2번 케이스)
이러한 문제점을 해결하기 위해 파티션 계획법을 개선하려는 노력이 나타났다.
대표적으로 피벗을 랜덤으로 선택하는 방법, 배열의 정가운데로 선택하는 방법, 배열 중 3개나 9개의 원소를 골라 그 중앙값으로 선택하는 방법 등이 있다.
이러한 방법들을 사용하더라도 최악의 경우를 마주할 수 있지만 이는 극히 드물다.
3.
퀵 정렬은 중복된 값의 순서가 유지되지 않는 불안정 정렬에 해당한다.
구현 [Python]
def quick_sort(A, start, end):
if start > end:
return
def partition(left, end):
pivot = A[end]
for right in range(left, end):
if A[right] > pivot:
continue
A[left], A[right] = A[right], A[left]
left += 1
A[left], A[end] = A[end], A[left]
return left
p = partition(start, end)
quick_sort(A, start, p - 1)
quick_sort(A, p + 1, end)
참고 자료 :
https://ko.wikipedia.org/wiki/퀵_정렬
https://namu.wiki/w/정렬%20알고리즘#s-2.2.3
파이썬 알고리즘 인터뷰 (박상길 지음)