8.1 라우팅 개요
- 수없이 많은 호스트와 엄청 많은 라우터가 있는 인터넷에서의 라우팅은 계층적 라우팅만 가능하다
- 다양한 라우팅 알고리즘과 여러 단계의 라우팅이 필요하다
- 인터넷의 라우팅 개념과 알고리즘을 이해하고, 어떻게 인터넷에 적용하는지를 고찰한다.
8.1.1 일반적인 아이디어
- 유니캐스트 라우팅은 소스와 호스트가 각각 하나이다. (멀티캐스트는 목적지가 여러 개인 것)
- 소스에서 목적지로 갈 때는 라우터를 거치게 되는데, 라우터나 호스트에선 라우팅 테이블을 보고 목적지를 파악해서 해당 목적지에 가까운 라우터 쪽으로 전달하게 된다.
- 라우터와 라우터를 거치며 패킷이 전달되는데, 이때 사용하는 단위는 홉이다. (ex. 5개의 라우터를 거친다 = 5개의 홉이다)
- 발신지 호스트는 포워딩 테이블이 필요 없다. 왜냐하면 발신지 호스트는 자신의 패킷을 로컬 네트워크의 기본 라우터에 전달하면 되기 때문이다.
- 호스트가 여러 네트워크에 동시에 연결된 경우에는 라우팅테이블이 필요하다
- 목적지 호스트도 자신이 속한 라우터로부터 패킷을 수신하므로 포워딩 테이블이 불필요하다
- 여러 네트워크에 동시에 연결될 경우에는 응답 데이터를 보낼 때 필요하다
- 인터넷에 연결된 라우터에서 포워딩 테이블이 필요하다.
8.1.2 최소비용 라우팅
-
인터넷을 weighted graph로 표시하면, 출발 라우터로부터 도착 라우터로의 가장 좋은 경로는 둘 사이의 최소 비용 경로인 경우이다
-
즉 출발 라우터는 목적지로 향하는 여러 가능 경로 중에서 총 비용이 최소가 되는 경로를 선택하는 것이다.
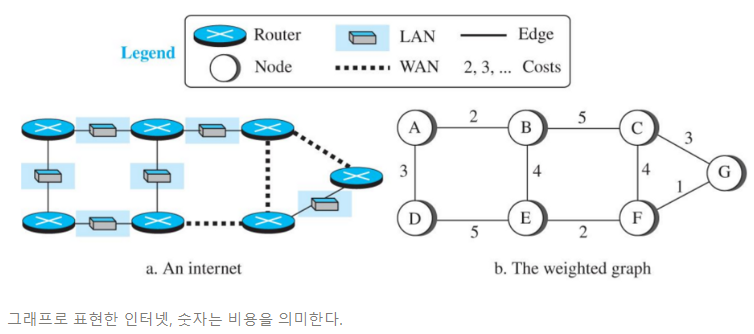
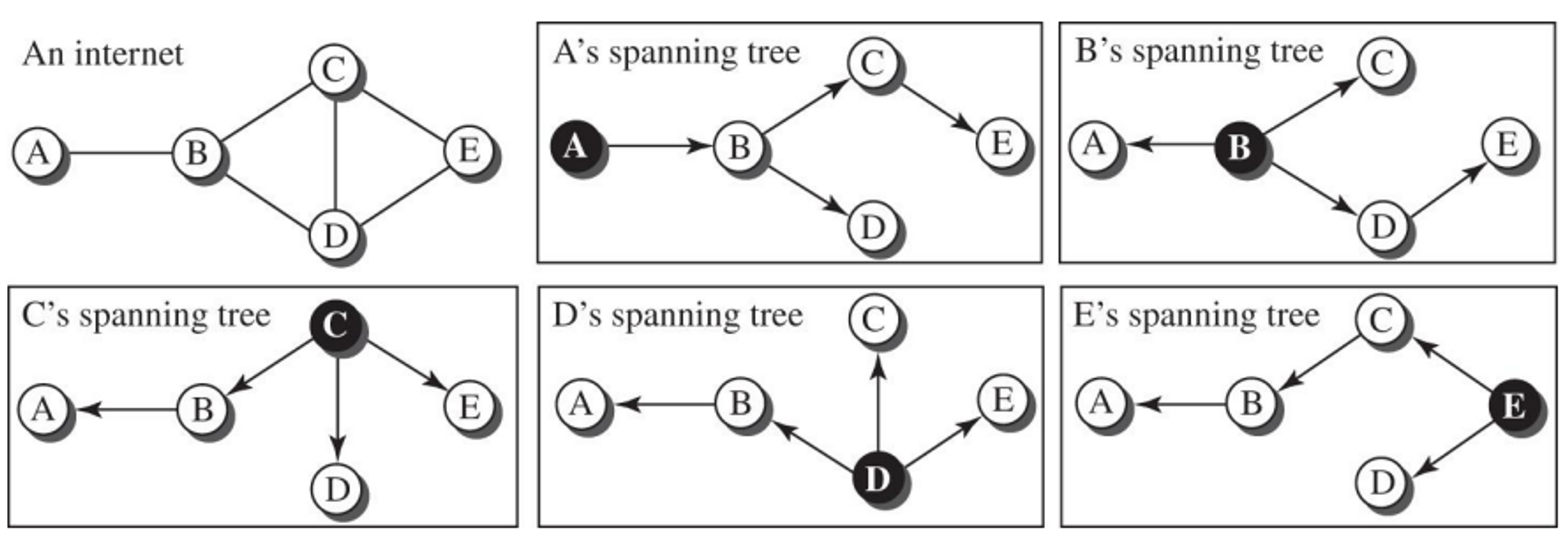
그래프로 표현한 인터넷, 숫자는 비용을 의미한다.
- 라우터끼리 잇는 데에는 LAN과 WAN 링크가 있지만 weighted graph에선 이 둘을 종합적으로, 비용으로 계산한 것이다
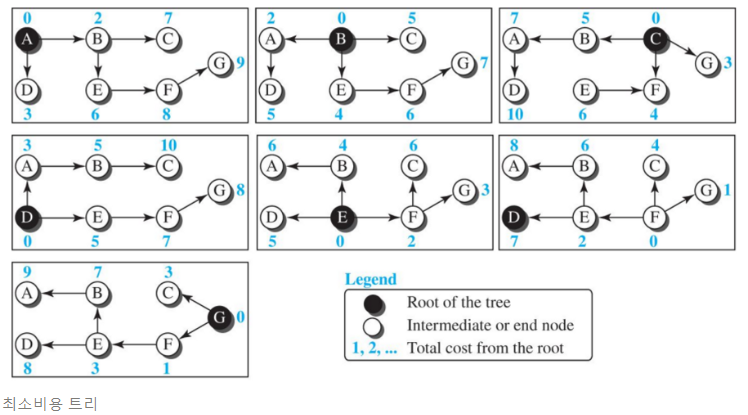
- 루트노드는 라우터 자기 자신이다.
- 모든 노드에서 최소비용을 갖는 트리를 그려서 목적지까지 최소비용을 갖는 트리를 계산한다.
- 트리에선 루프가 생기면 안된다.
- 각각의 노드마다 자신 자신을 루트로하는 트리를 만들어서 목적지까지 간다.
8.2 라우팅 알고리즘
- 과거 여러 알고리즘이 고안되었다
- 라우팅 알고리즘의 차이점
- 최소비용의 해석
- 최소비용 트리를 만드는 법
8.2.1 거리-벡터 라우팅
- 거리-벡터
- 방향과 거리 값을 가진다.
- 벨만 포드 공식
- 소스와 목적지 사이의 최소비용경로를 찾는 식이다.
- 소스 x, 목적지 y 사이의 최소 비용을 구하는 것인데, 중간노드 a, b, c가 있다고 한다면

- 만일 새로운 경로의 중간노드 Z가 업데이트 되었다면, 아래와같이 표현할 수 있다.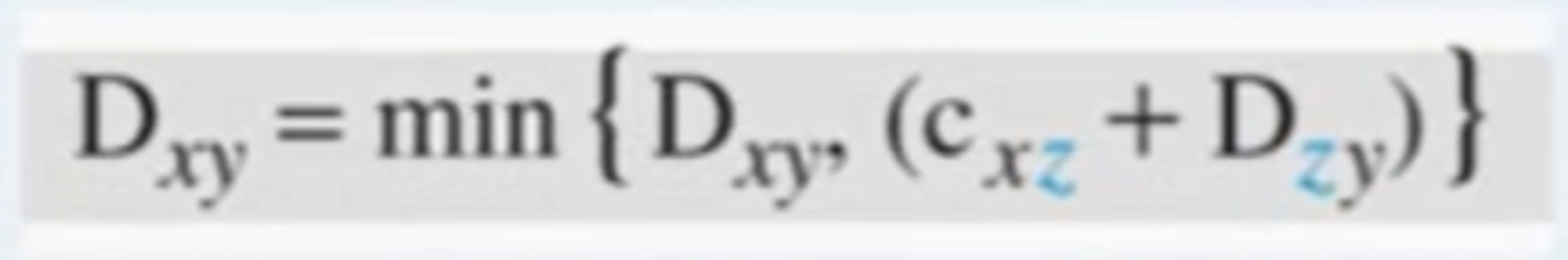
- 벨만-포드 공식의 그래프적 개념
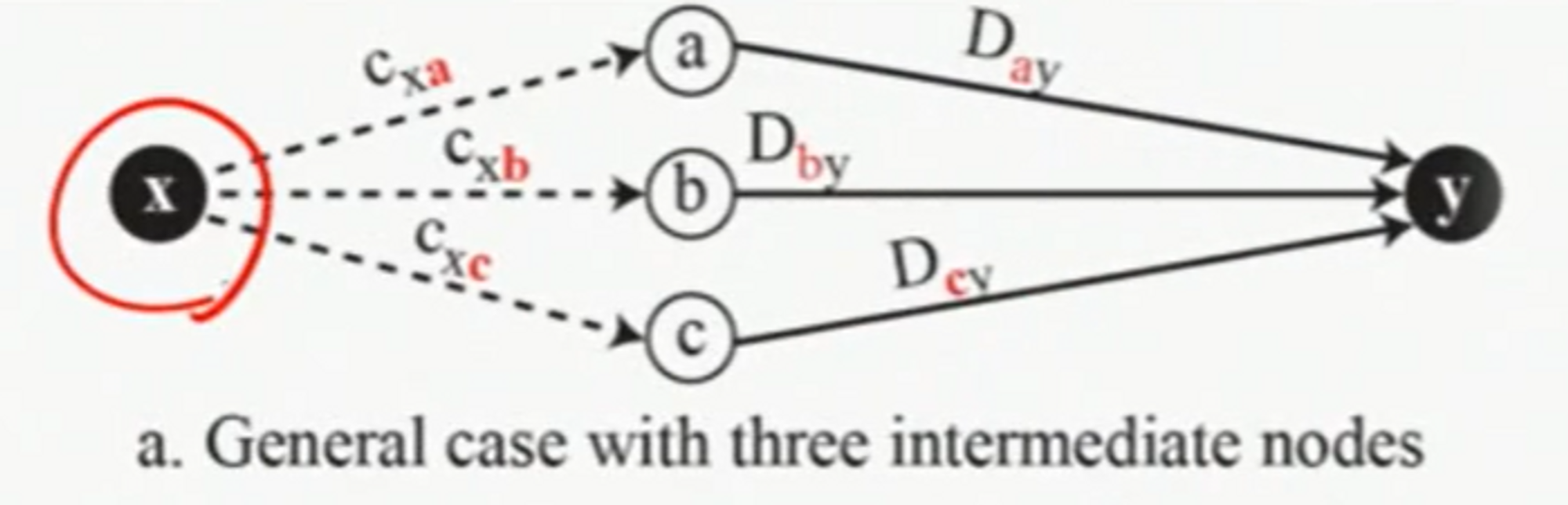
여기서 소스노드 : x, destination : y이다.

만일 기존의 경로 보다 더 최적의 경로를 알게된다면 업데이트 한다.
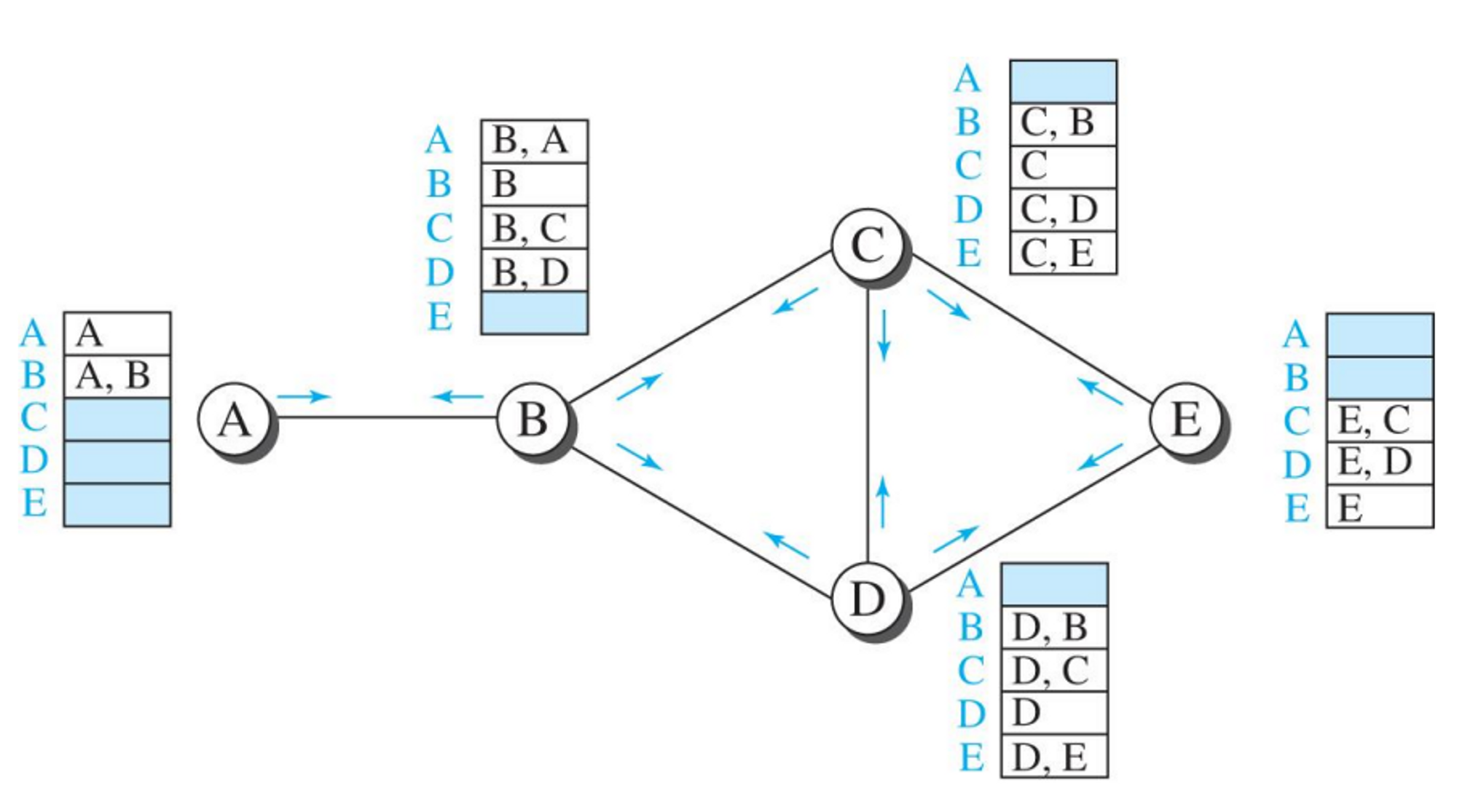
- 트리의 거리-벡터 값
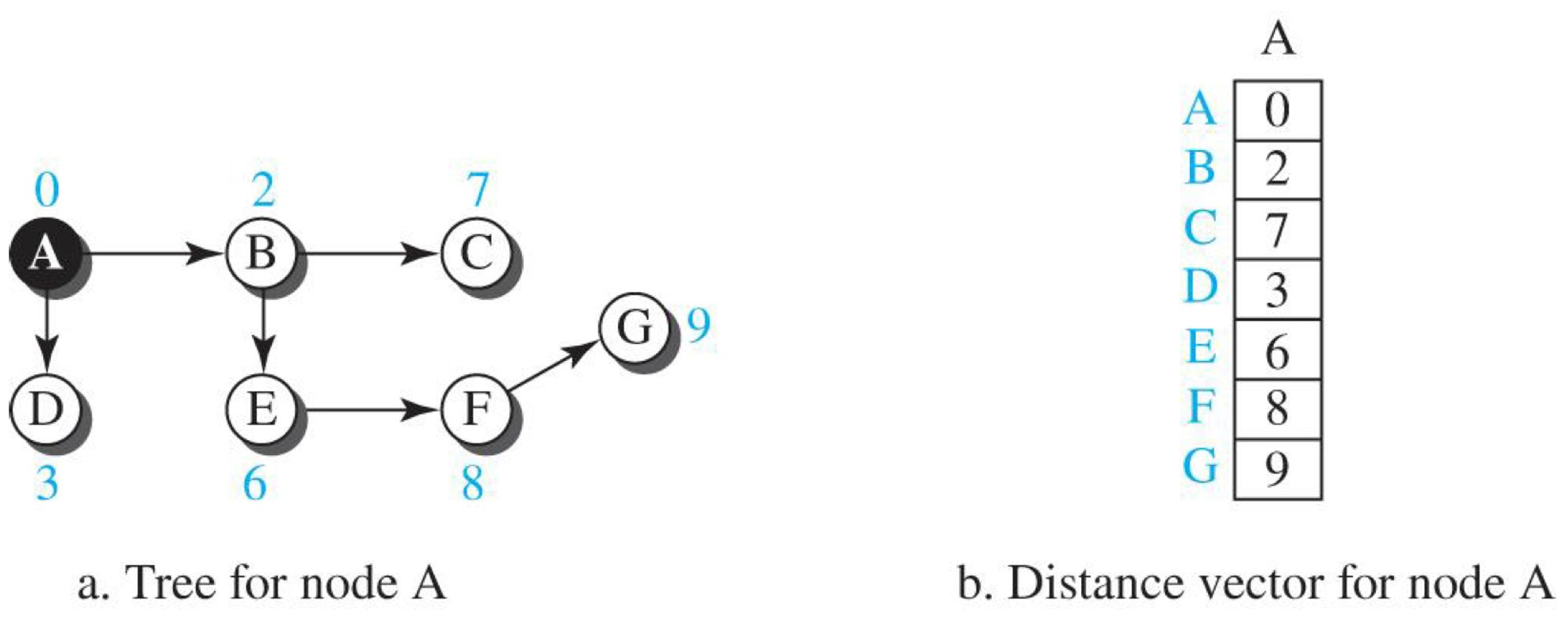
각각의 노드는 neighbor 노드로부터 정보를 받는다 A노드는 B, D로부터 정보를 받고 B 노드는 C, E로부터정보를 받고.. 쭉쭉 하다보면 결국 A 노드는 전체 노드의 정보를 받아 최소 비용 트리를 얻을 수 있다.
- 네트워크의 첫번째 거리-벡터 값
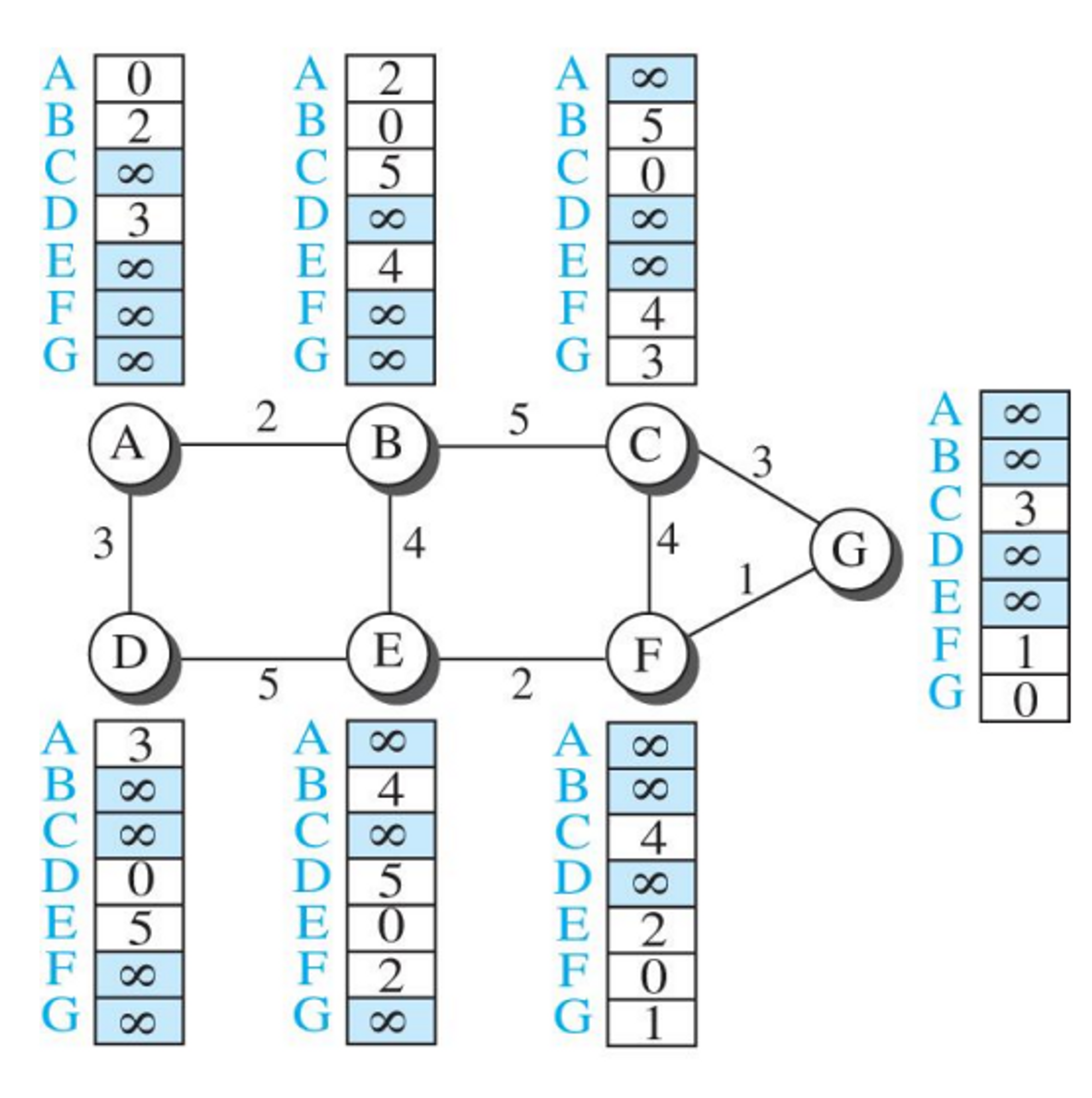
- 본인 노드로부터 거리를 계산을 하고, 그걸 서로서로 공유하면서 트리를 만들 수 있다.
- 예시
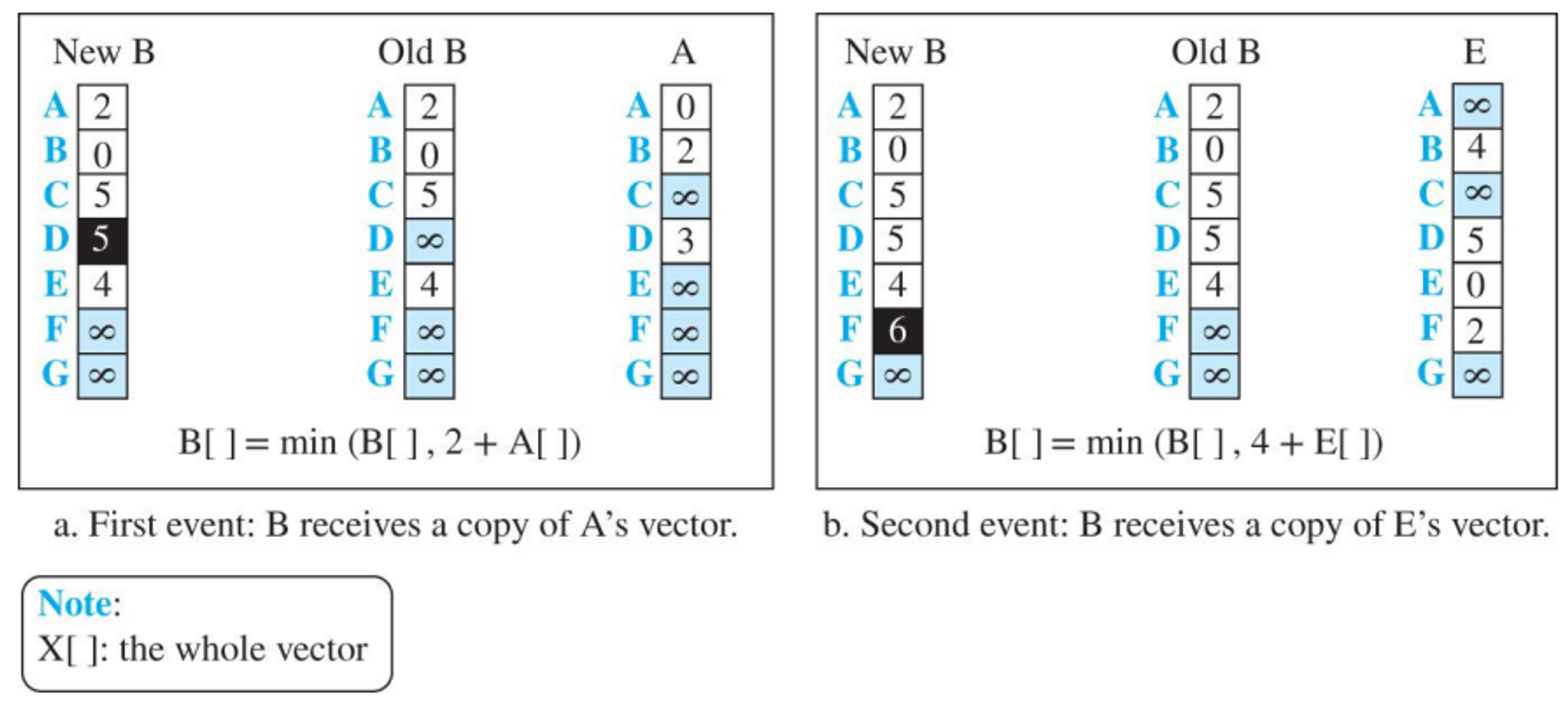
- 원래 B 노드는 주변 노드가 A, C, E 노드밖에 없었다.
- 그러다 주변 노드의 정보를 수집해서 업데이트한다.
- A → D 까지 가는 비용이 3이라는 것을 알게되었다, 그럼 B →(2)→ A →(3)→ D 이 되므로 결과적으로 B → D는 5의 비용이 들게 된다.
- 위와같은 방식을 이용해 모든 테이블을 채우게 된다.
- 만일 내가 원래 알고있던 비용이 있고, 새로운 경로로 갔을 때의 비용 중 새로운 경로가 더 적은 비용을 갖게 된다면 이 또한 업데이트를 하게 된다.
```c
Distance_Vector_Routing ( )
{
// Initialize (create initial vectors for the node)
D[myself ] = 0
for (y = 1 to N)
{
if (y is a neighbor)
D[y] = c[myself][y]
Else
D[y] = ∞
}
send vector {D[1], D[2], …, D[N]} to all neighbors
// Update (improve the vector with the vector received from a neighbor)
repeat (forever)
{
wait (for a vector Dw
from a neighbor w or any change in the link)
for (y = 1 to N)
{
D[y] = min [D[y], (c[myself ][w] + Dw
[y])] // Bellman-Ford equation
}
if (any change in the vector)
send vector {D[1], D[2], …, D[N]} to all neighbors
}
}
```
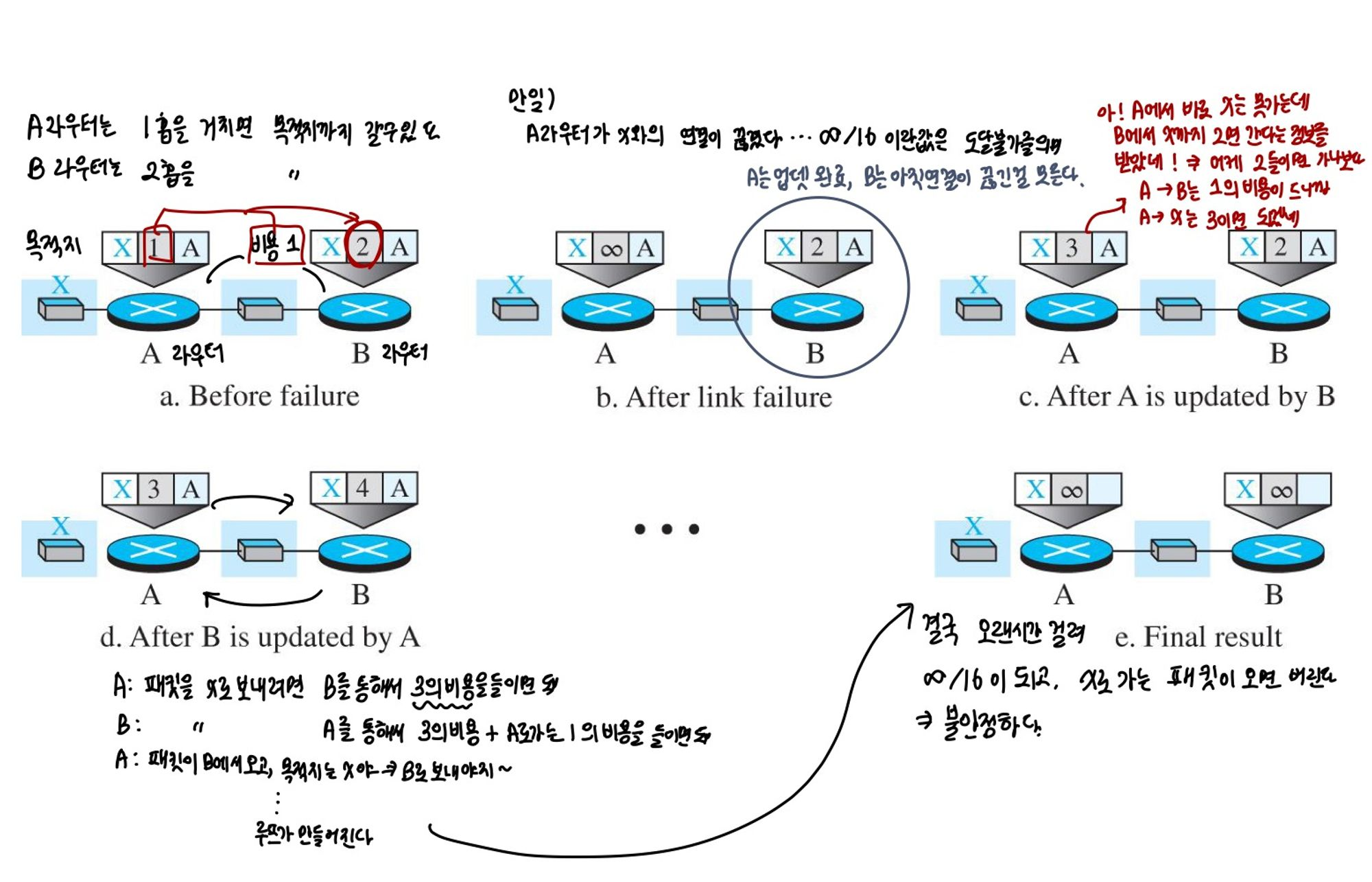
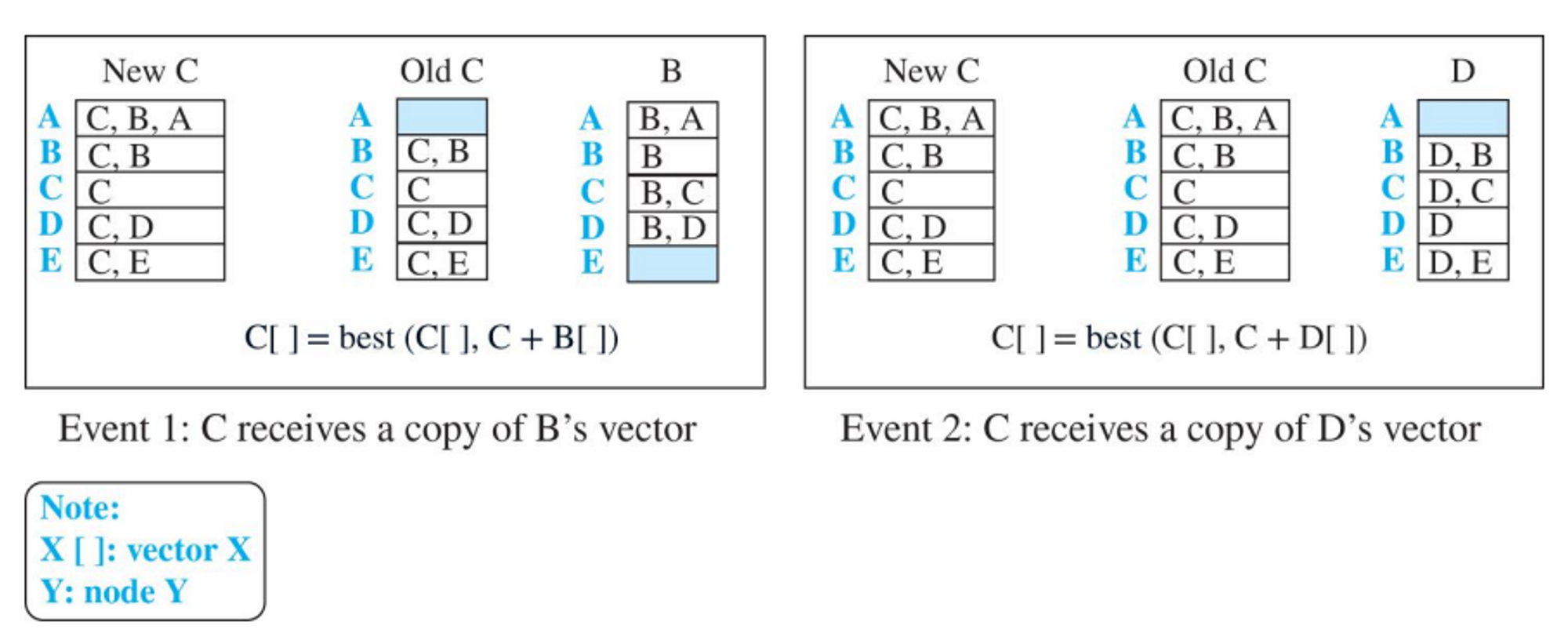
- 두 노드의 불안정성
- 거리-벡터 알고리즘의 가장 치명적인 단점은, 비용감소와 같은 좋은 소식은 빨리 퍼지지만 비용 증가와 같은 나쁜 소식은 천천히 퍼진다는 것이다.
8.2.2 링크-상태 라우팅
-
Link-state
Link란 엣지 또는 라우터끼리를 연결해주는 역할을 한다.
상태는 이 링크의 비용이 얼마냐, 안정적이냐, 밴드 폭이 얼마냐 등을 나타낸다.
-
Link의 비용은 실제 비용, 밴드폭 등의 상태를 따지게 되는데, 이 링크 비용을 모든 라우터에 전달해서 최종적으로 최소비용트리를 구하게 된다.
- 만일 무한대의 링크 비용을 갖는다하면, 링크가 없거나 고장난 상태라는 뜻이다.
-
Link-state database(LSDB)
- 모든 라우터들은 모든 링크의 상태를 알아야하기 때문에 네트워크의 완전한 맵이 필요하다.
- 모든 링크의 상태집합을 링크-상태 데이터베이스(Link-State DataBase)라고 부른다.
- 전체 인터넷에 하나의 LSDB만이 존재한다.
- 각 노드는 플러딩을 통해 LSDB를 만든다.
- 그리고 각 노드는 최소비용트리를 만들기 위해 각각의 LSDB 복사본을 가지고 있다.
- 각 노드는 이웃 노드들에게 노드 정보와 링크의 비용 정보를 알기 위해 LSP(Link State packet) 을 전송한다. 만일 새로 받은 LSP가 순서 번호를 검색하여 기존의 것보다 오래되었다면 폐기하고, 더 새로운 것이라면 기존에 가지고 있던 LSP를 폐기한다.
-
거리-벡터 라우팅과의 차이점
- 거리-벡터 라우팅은 주변 라우터로부터 정보를 받아서 업데이트한다.
- 그러나 주변 라우터로부터 받는 정보는 네트워크의 완벽한 라우팅 정보이다.
- 링크-상태 라우팅의 경우, 하나의 라우터가 수집하는 정보는 모든 라우터로부터 해당 라우터의 링크 상태만 수집한다. 그래서 자기가 수집된 모든 링크 상태를 통해 라우팅 정보를 구한다.
-
예
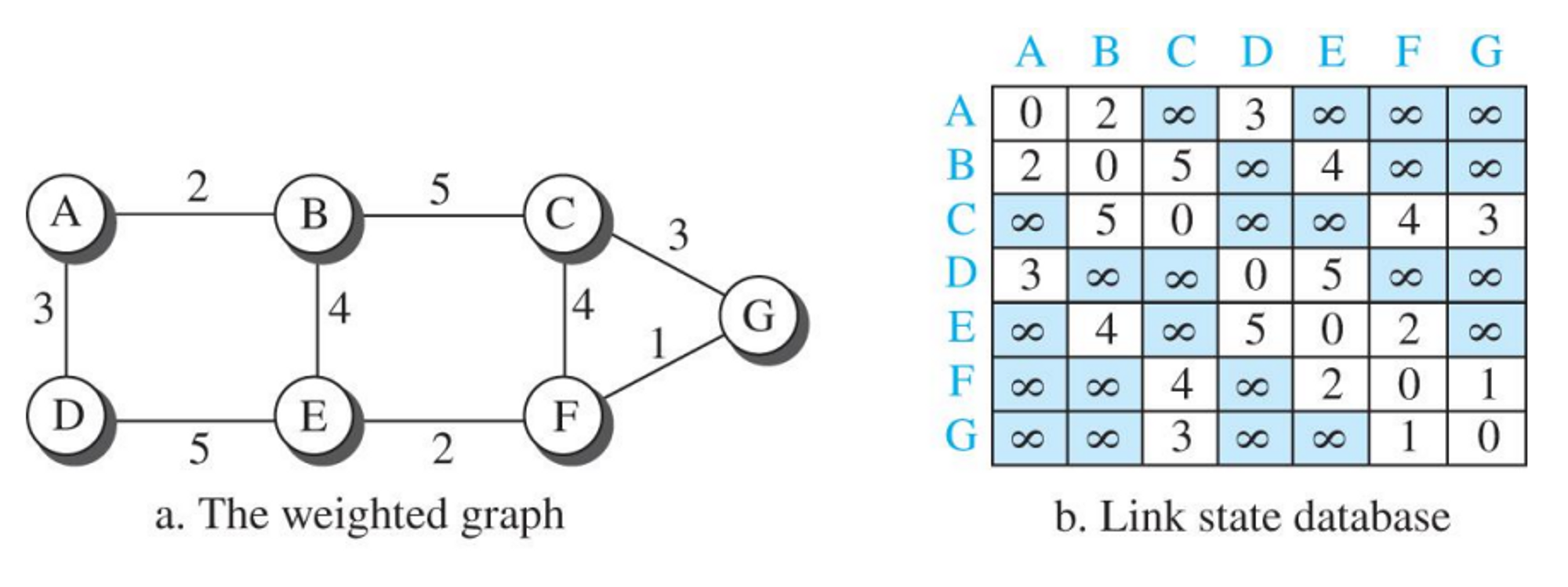
- A는 링크가 2개있다
- F는 링크가 3개 있다 등등.. 이런 정보를 통해서 b.Link state database를 만들게 된다.
- Link state database를 만들게 되면 각 노드들은 모두 동일한 정보 (LSDB)를 갖게된다.
- 동일한 정보로부터 자기자신을 루트로 하는 라우팅 정보를 만들어가는 것이다.
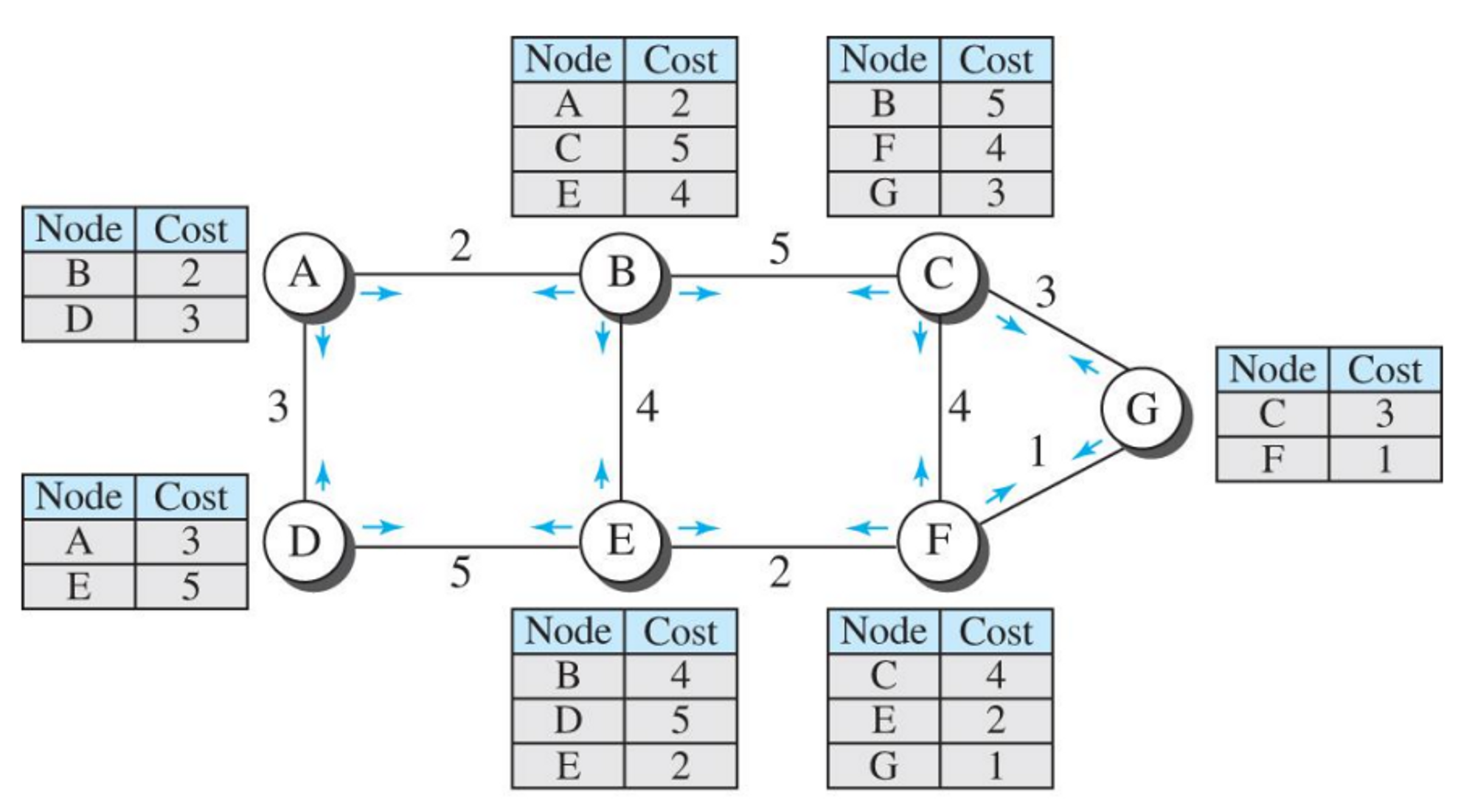
- LSDB를 만들기 위해 각각의 노드에 의해 만들어지고 보내지는 LSP들
- 다익스트라 알고리즘을 이용하여 LSDB로부터 최소비용트리를 생성한다
-
루트노드선정 (라우터 자기자신). 루트노드만 있는 트리로 시작한다.
-
아직 트리에 없고 연결된 노드를 선택하여 트리에 추가하고, 트리내의 모든 노드까지의 비용을 업데이트한다.
-
모든 노드가 트리에 추가될 때까지 2단계를 반복한다.
Distance_Vector_Routing() { // Initialization Tree = { root } // Tree is made only of the root for (y = 1 to N) // N is the number of nodes { if (y is the root) D[y] = 0 // D [y] is shortest distance from root to node y else if (y is a neighbor) D[y] = c[root][y] // c [x] [y] is cost between nodes x and y in LSDB else D[y] = ∞ } // Calculation repeat { find a node w, with D[w] minimum among all nodes not in the Tree Tree = Tree ∪ {w} // Add w to tree // Update distances for all neighbor of w for (every node x, which is neighbor of w and not in the Tree) { D[x] = min{D[x], (D[w] + c[w][x])} } } until(all nodes included in the Tree) }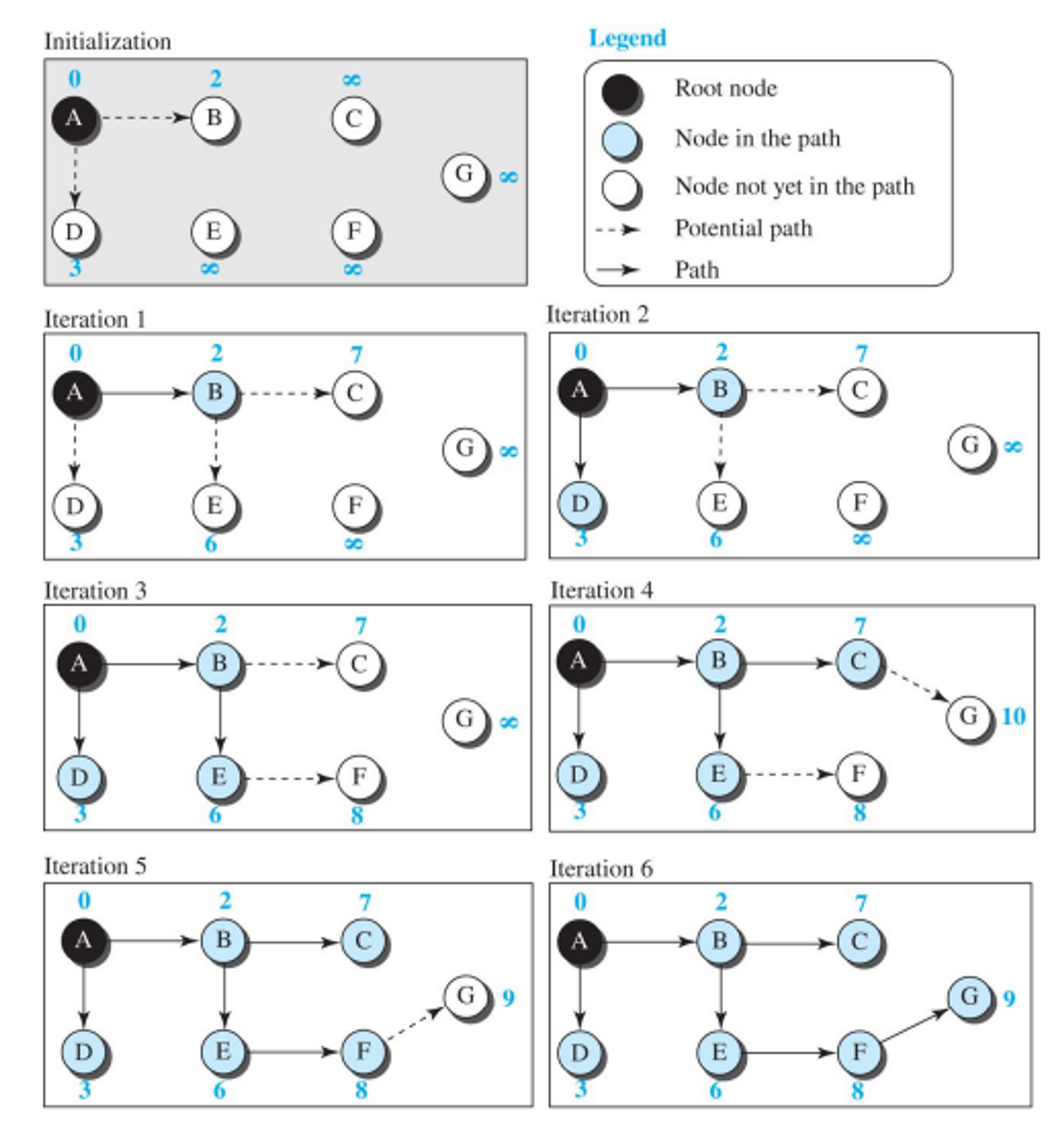
-
8.2.3 경로-벡터 라우팅
- 최소비용이 아닌 다른 정책을 적용하는 라우팅
- 여기서 말하는 정책이란, 특정 노드 제외 경로 혹은 특정 노드를 선택하는 경로를 말한다.
- Best Spanning Tree를 선정한다 (policy 적용)
- ISP 간의(큰 네트워크 예. SKT, KT 등) 패킷 경로를 위해 고안되었다.
- Distance-vector의 Bellman-ford 알고리즘과 비슷하지만 최소비용이 아닌 정책을 반영한다.
- 라우팅 테이블 내용
- 경로벡터 [x, a, b, c, d, y] 중 x → y까지 가는 데 얼마의 비용이 드는 지 찾는 것이 아니다.
- 경로벡터 [x, a, b, c, d, y] 중 어느 ISP를 거쳐서 가는 지를 찾는다.
- 이는 이웃 노드와 교환하는 방식으로 라우팅 테이블을 채운다.
- 자기가 연결된 노드로부터의 정보만 가지고 있는다
- 그러고 교환된 정보를 업데이트 한다.
- 어디를 거치는지에 대한 정보만을 저장한다.
8.3 라우팅 프로토콜
- Routing Information Protocol (RIP)
- 거리 벡터 알고리즘을 기반으로 한다
- Open Shortst Path First (OSPF)
- 링크 상태 알고리즘을 기반으로 한다
- Border Gateway Protocol (BGP)
- 경로 벡터 알고리즘을 기반으로 한다.
8.3.1 인터넷 구조
- 인터넷은 하나의 백본을 가진 트리구조에서 서로 다른 사설회사의 다중 백본 구조로 변경되고있다.
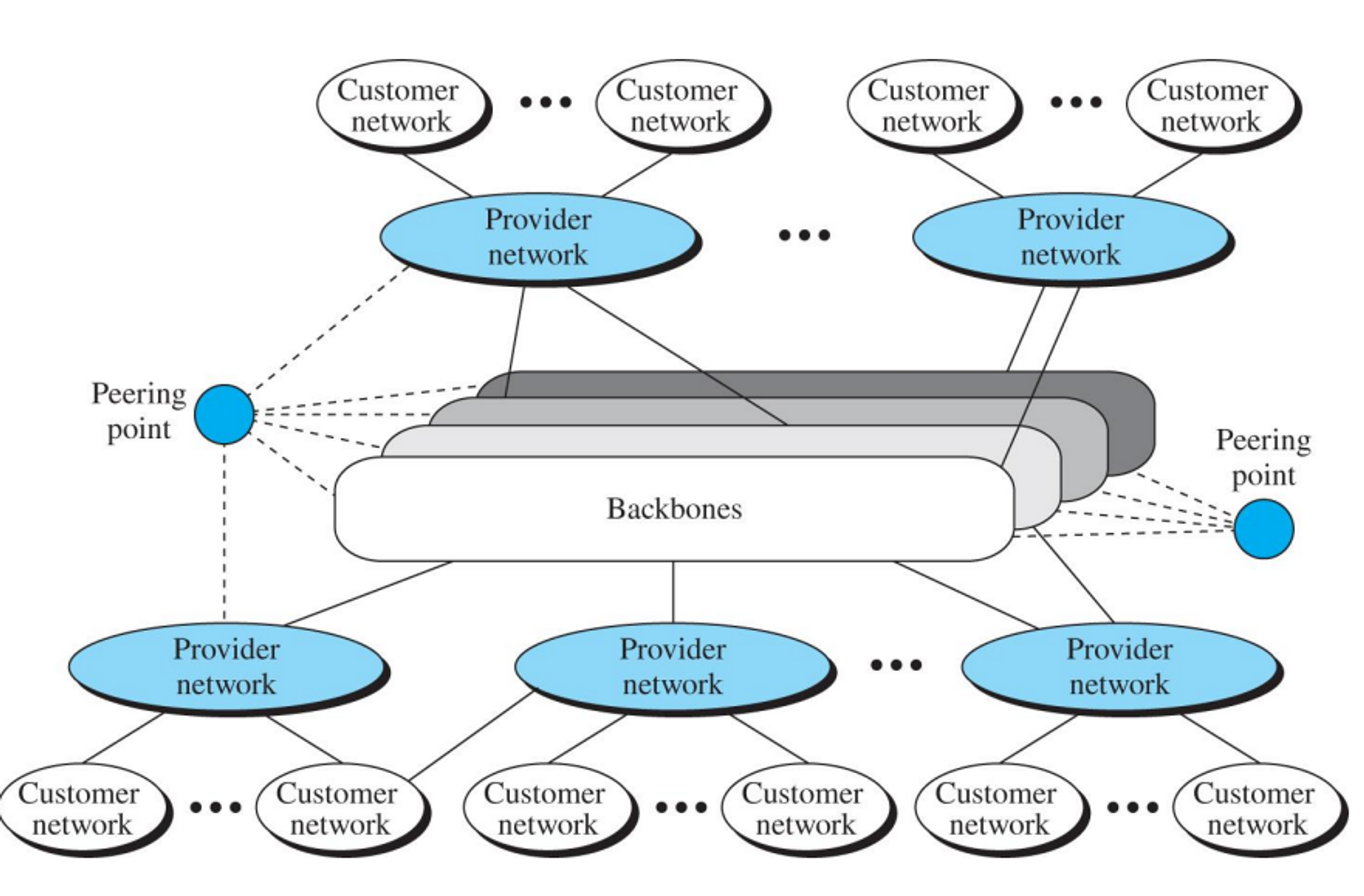
- 과거에는 하나의 백본만을 가졌지만, 최근에는 여러 개의 백본을 가지고 있다.
- 이런 복잡한 구조에선 여러 개의 라우터를 가지게 되고, 여러 개의 라우팅 알고리즘을 사용하게 된다.
자율시스템(AS)
- ISP가 네트워크와 라우터들을 관리할 때 각 ISP는 AS로 동작한다.
- AS는 ICANN으로부터 ASN을 할당받는다.
- AS들은 자신이 접속한 다른 AS에 따라서 구별된다
- 스터브 AS : 스터브 AS는 오직 하나의 다른 AS와 연결 가능하다. 데이터 트래픽은 스터브 AS에서 파괴되거나 초기화 된다.
- 다중홈 AS : 다른 AS들과 하나 이상의 연결 상태를 가질 수 있다. 데이터 트래픽은 다중홈 AS를 지나갈 수 없다.
- 임시 AS : 하나 이상의 AS와 연결되어있고, 데이터 트래픽이 통과 가능하다.
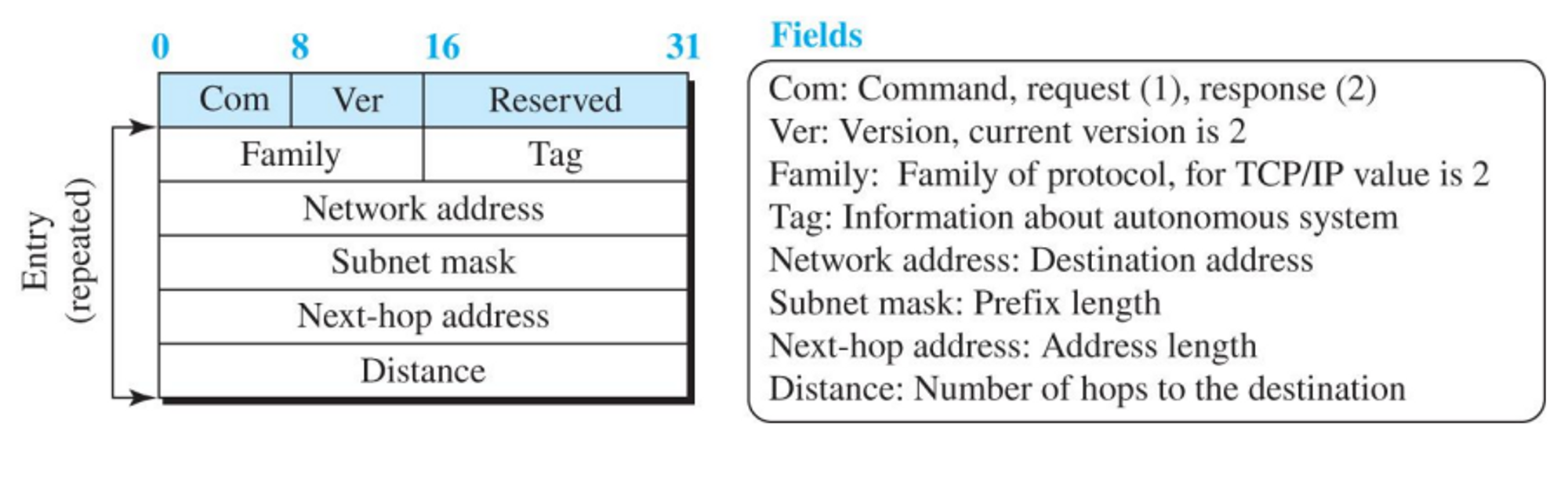
8.3.2 RIP (Routing Information Protocol)
- 가장 널리 사용되는 거리벡터 라우팅 알고리즘 기반의 도메인 내(intro domain) 라우팅 프로토콜이다.
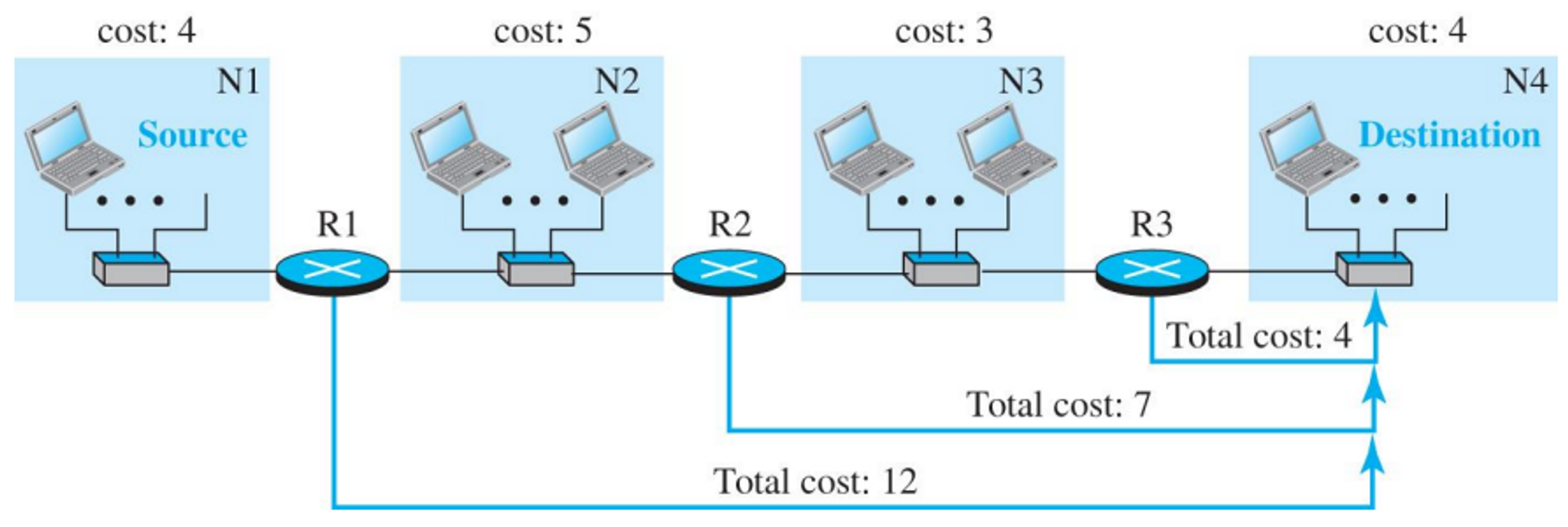
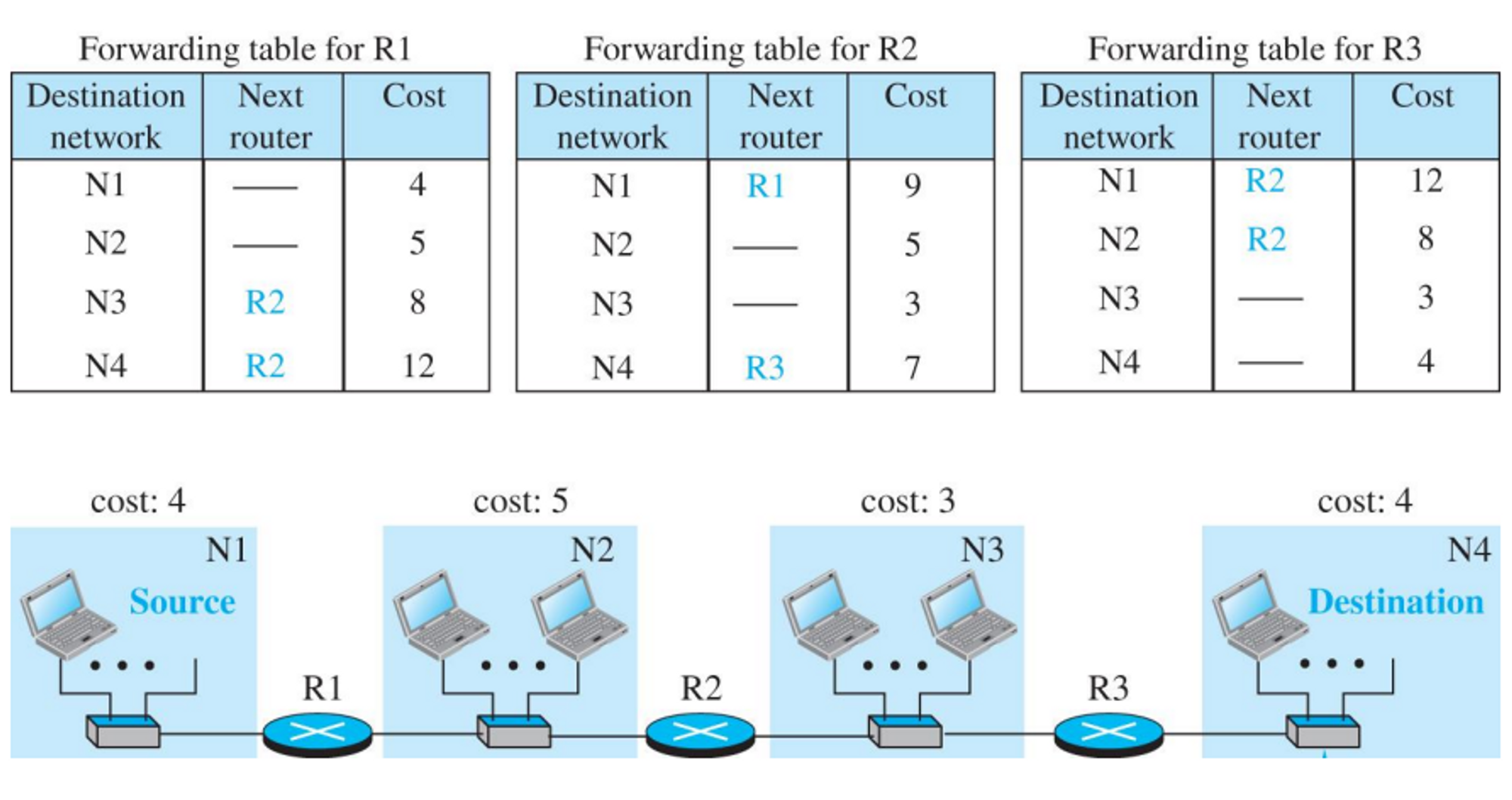
- RIP에서 경로의 최대비용은 15이다. 16은 무한대를 의미한다.
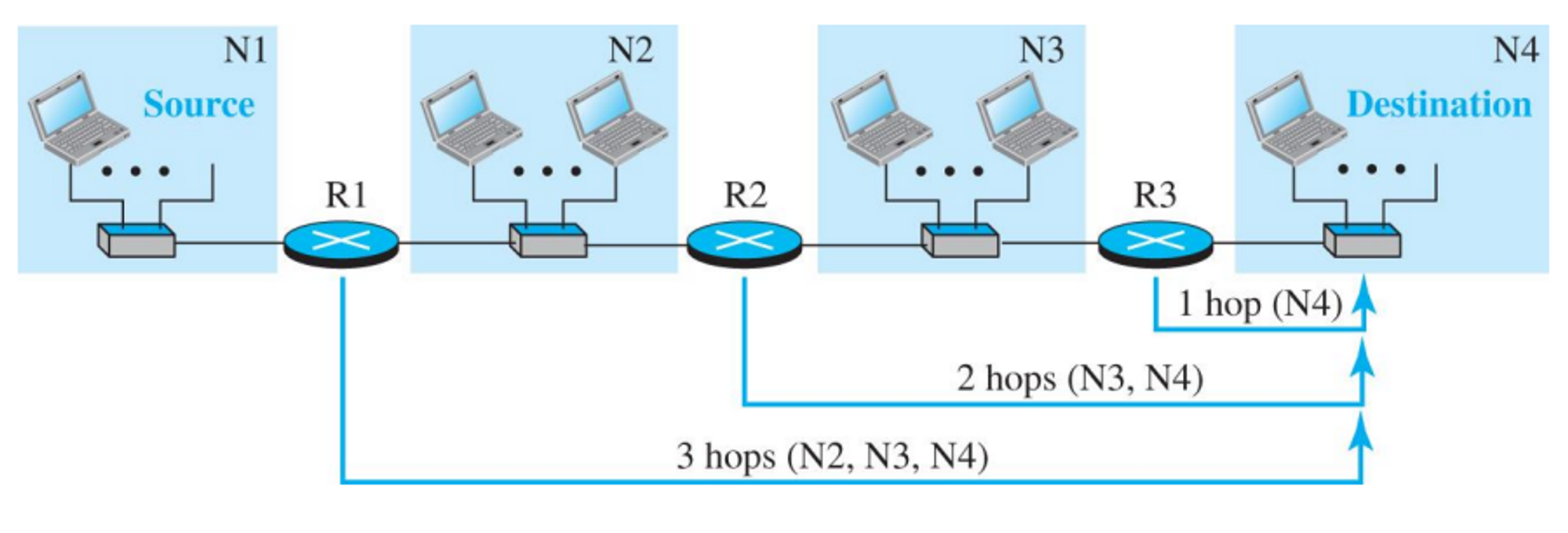
- 라우터 간의 비용은 홉 단위로 계산한다.
- 홉에 근거한 라우팅테이블을 만든다.
- 바로 연결된 것은 비용이 1이다 (1홉)
- N3를 갈때는 R2를 거쳐서 비용이 2홉이다. 등등으로 표현이 된다.
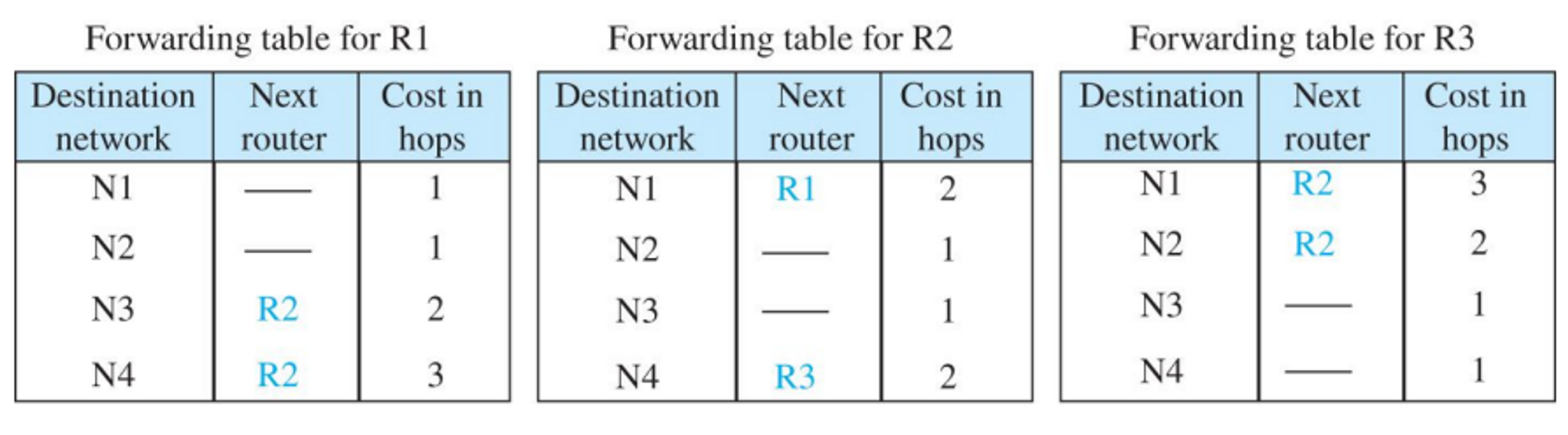
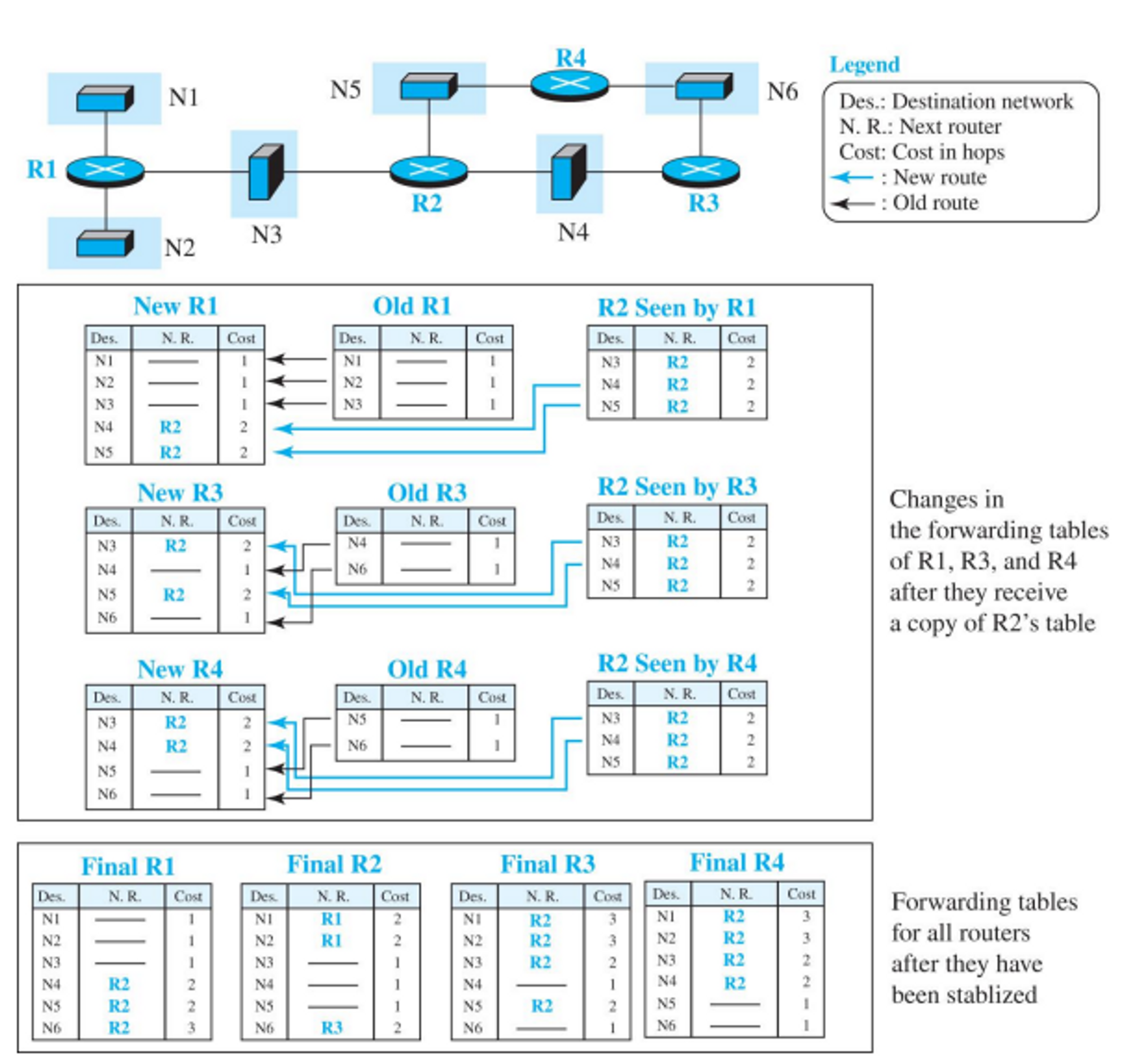
예)
- 초기상태
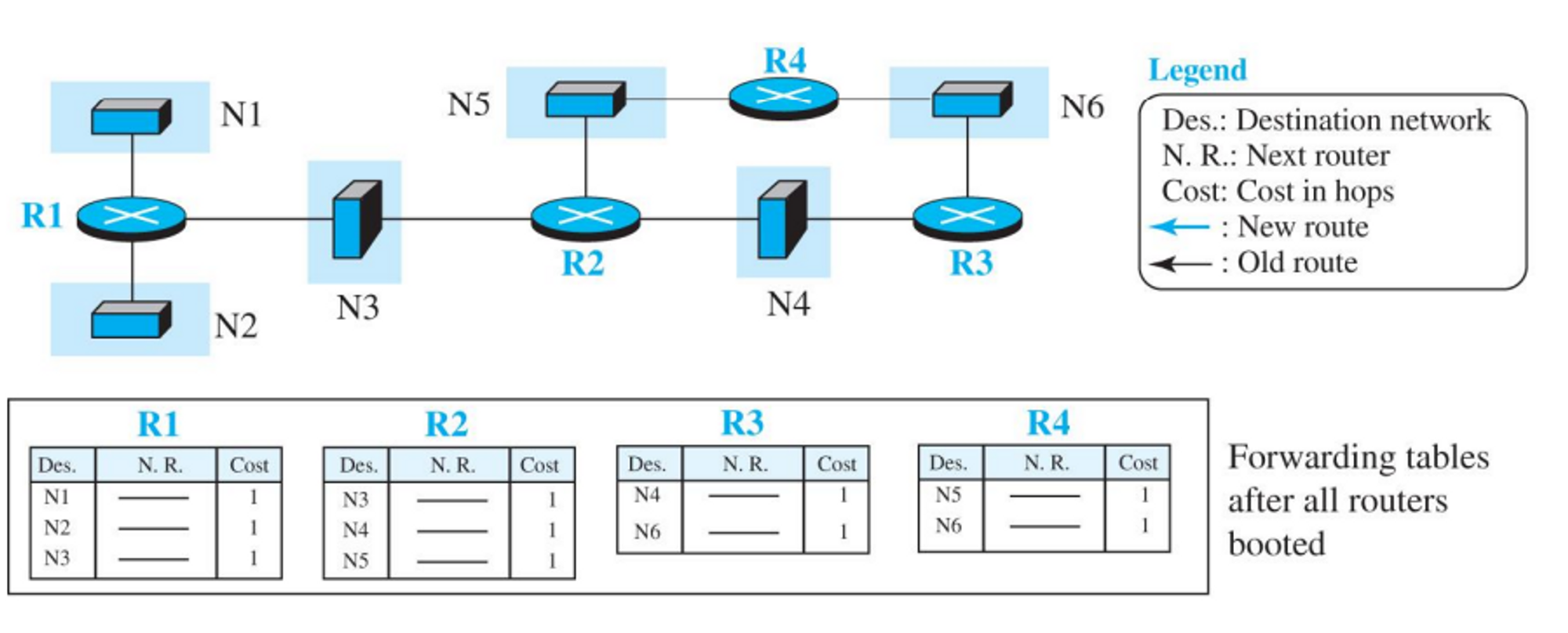
- 정보 업데이트
8.3.3 개방 최단경로우선 (OSPF)
- 도메인 내 라우팅 프로토콜이다.
- 링크 스테이트 라우팅 프로토콜 기반이다
- OSPF는 개방형 프로토콜로 규격이 공개되어있다.
- 홉이 아닌 메트릭을 통해서 비용을 계산하게 된다.
- OSPF 환경에서 AS내의 지역
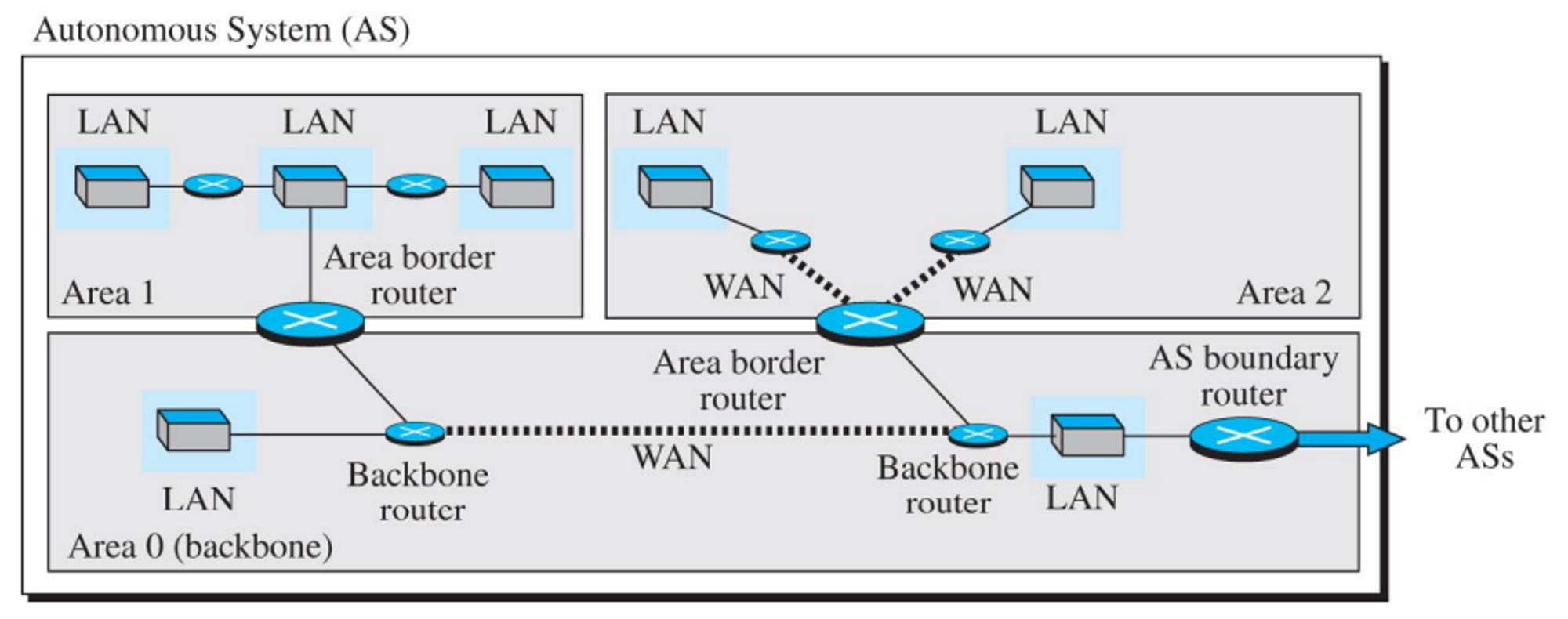
- 몇 개의 지역으로 나눈다. Area 0은 백본이다.
- 계층적인 관계를 갖기 때문에 보다 더 큰 네트워크에 적용 가능하다
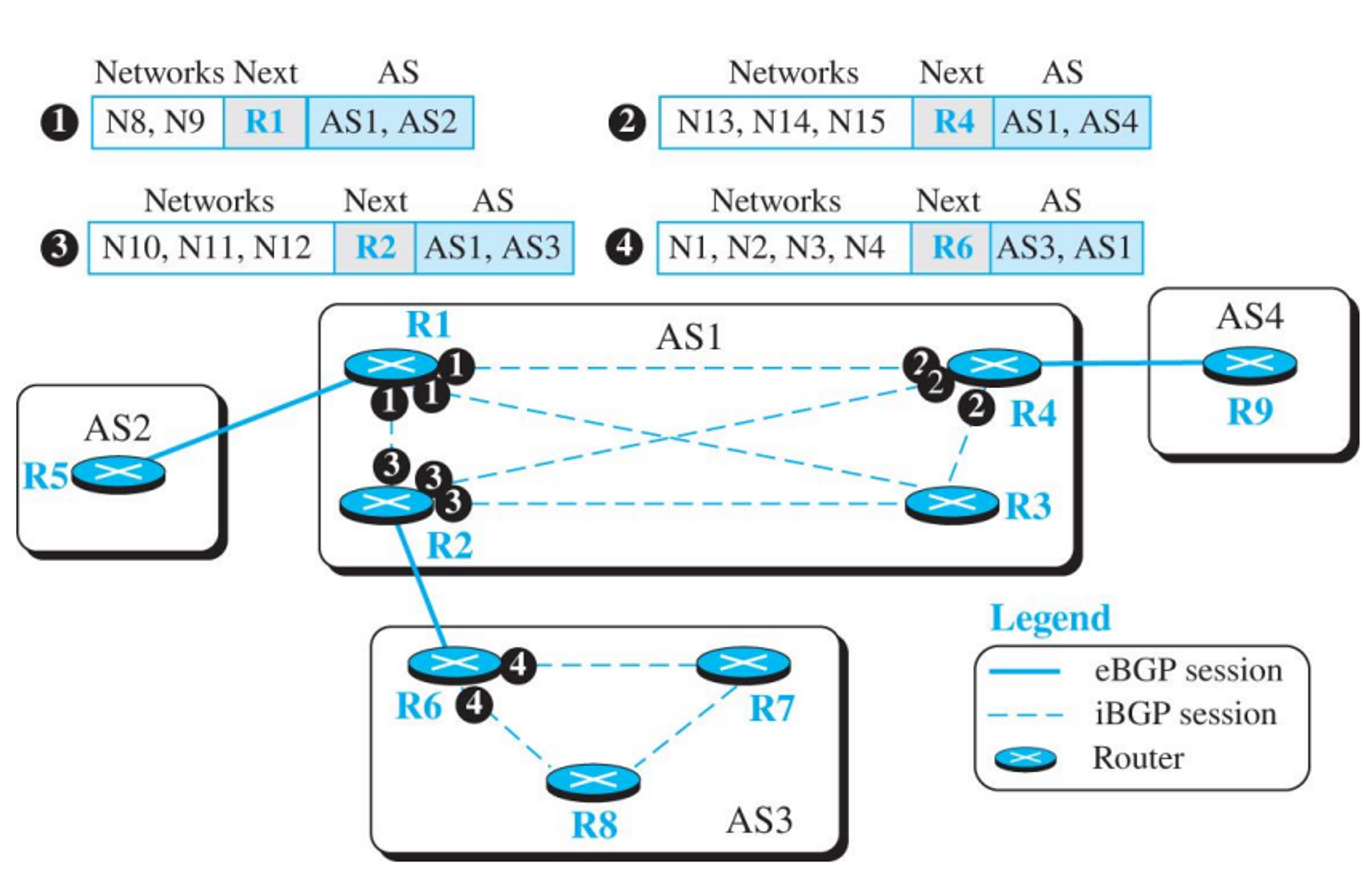
8.3.4 BGP
- 인터넷에서 사용되고있는 도메인간 라우팅 프로토콜이다.
- BGP4는 path-vector 알고리즘 기반이다
- 네트워크 도달가능성 정보 제공에 맞춰진다.
- eBGP(external BGP)
- AS의 경계 라우터에서 작동한다
- 다른 AS와 정보 교환한다
- iBGP
- 모든 라우터에서 작동한다.
- AS내 모든 라우터와 정보교환 한다.
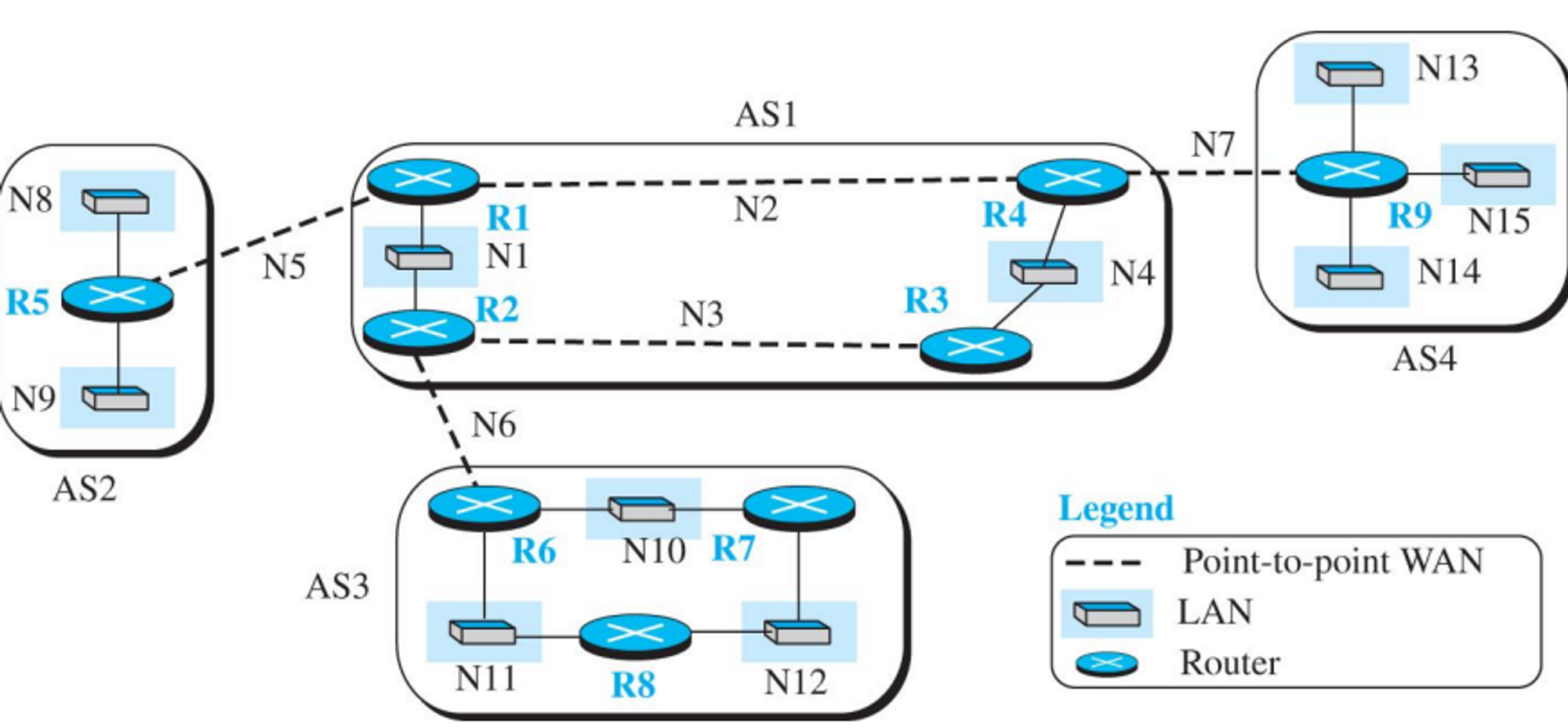
- 만일 다른 AS로 정보를 보내고자한다면, AS 경계에 있는 라우터들끼리 먼저 정보교환을 한 후 그 정보를 다시 내부 라우터에 뿌려준다.
- eBGP 동작
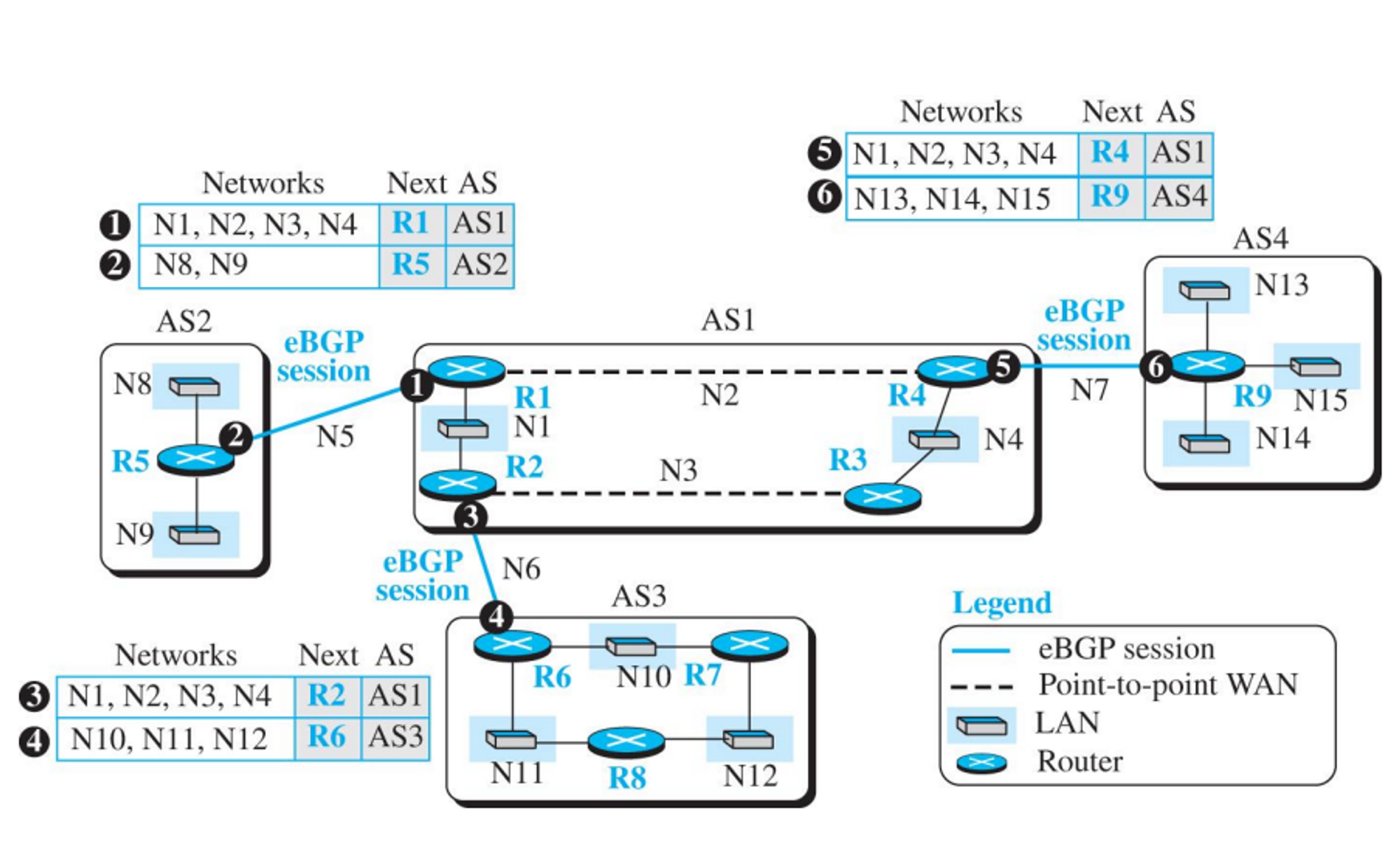
- iBGP + eBGP 동작