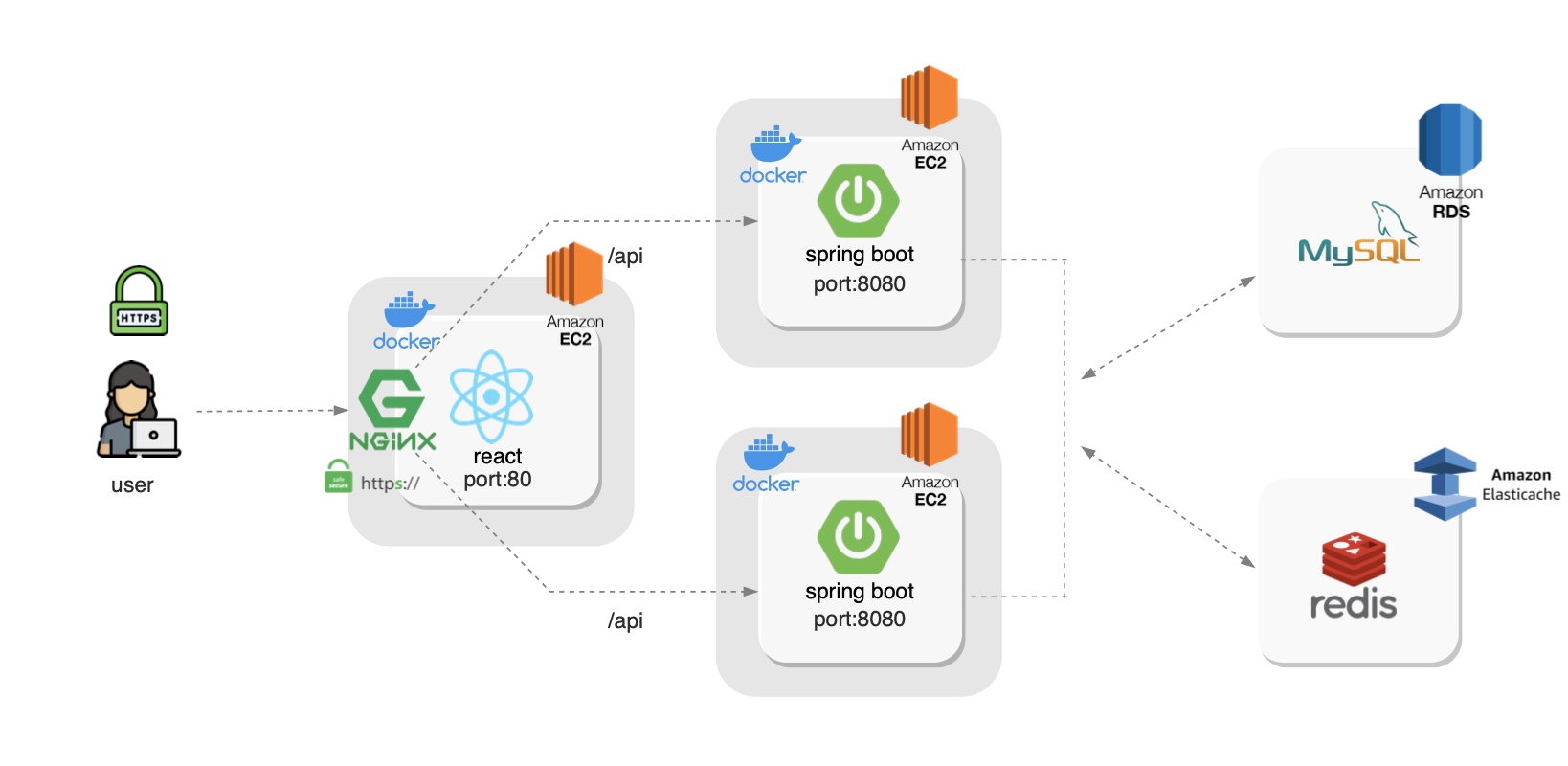
아키텍처
시장 조회 API에 대해 테스트를 진행했습니다. 레디스 캐싱 상태로 진행하겠습니다.
Local Mac M1 Pro (CPU : 8코어 / RAM : 16GB)
100명
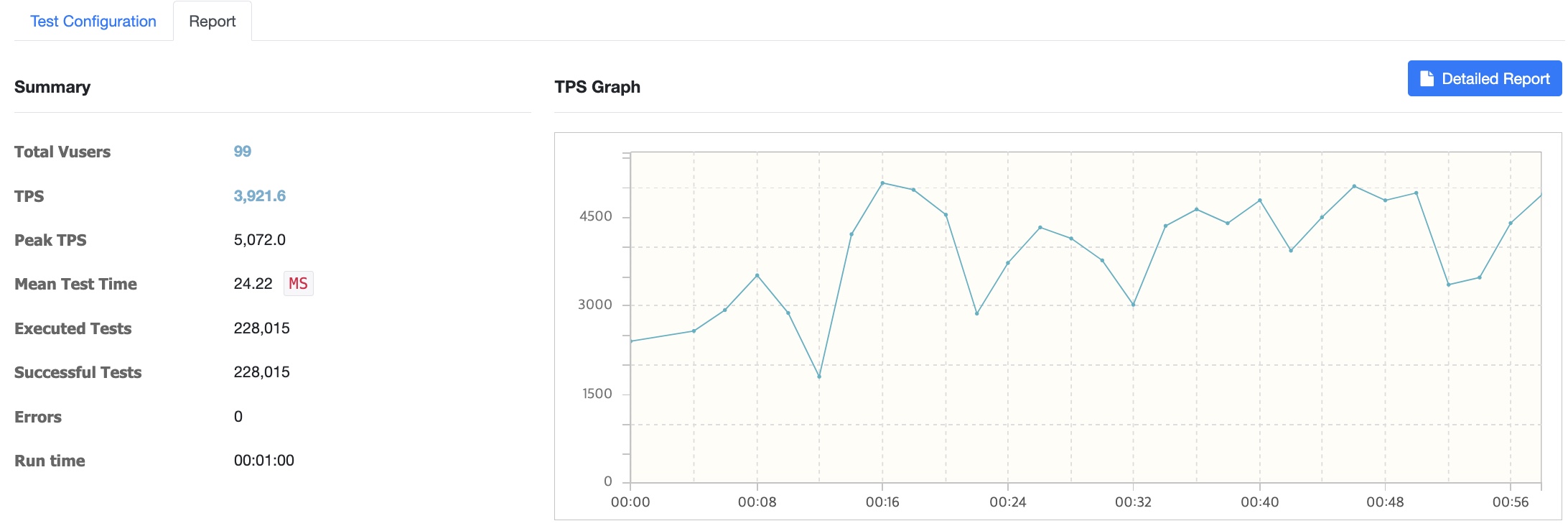
Vuser 증가
500명 -> 에러 발생
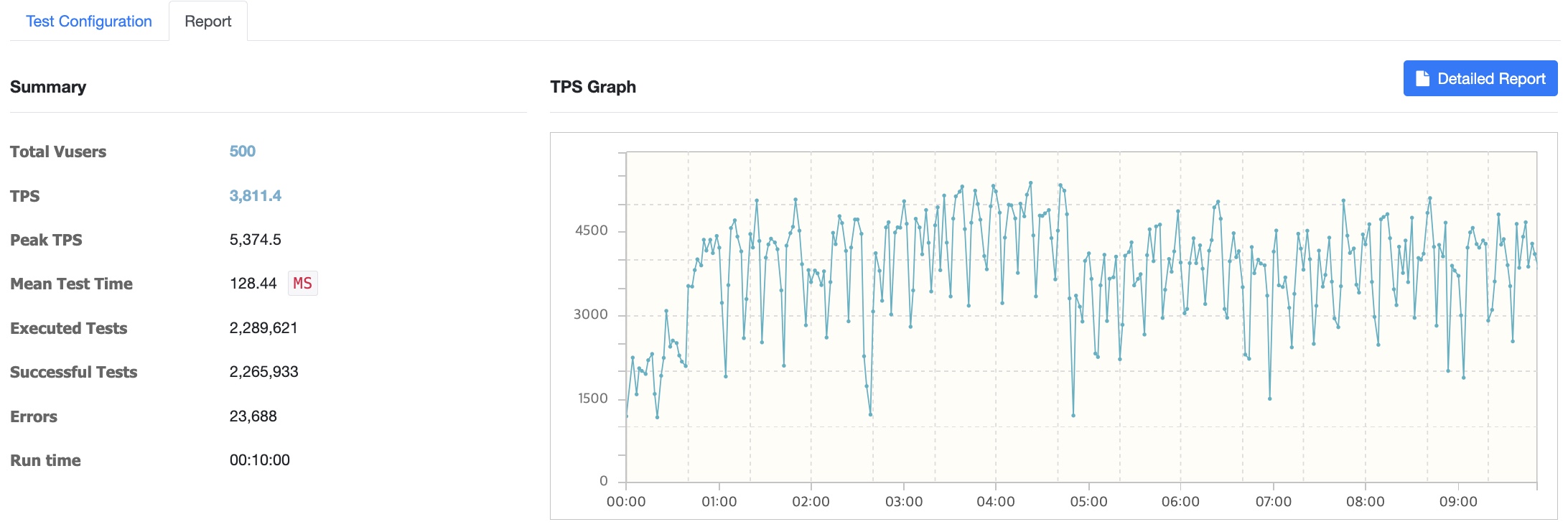
500명 이상으로 사용자를 늘릴수록 에러가 급증하고 서버에서 Read Time Out이 나는 등 트래픽을 견뎌낼 수 없었습니다.
1000명 -> 에러 발생
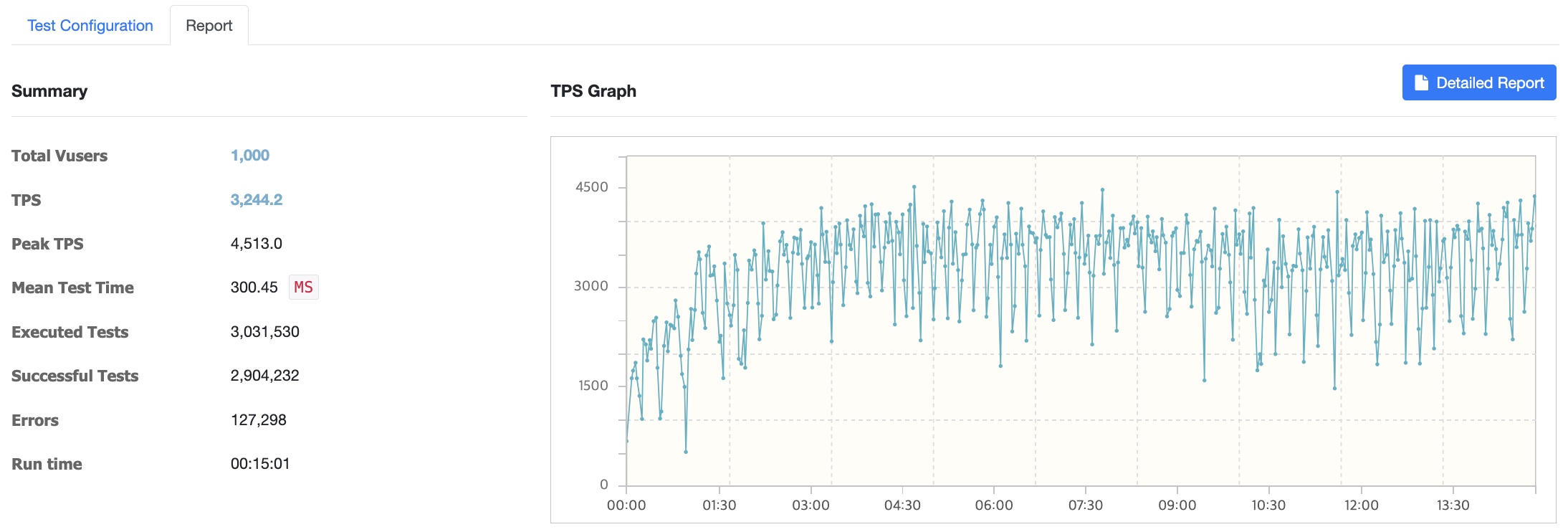
AWS t3.micro 서버 (2vCPU / RAM : 1GB)
100명
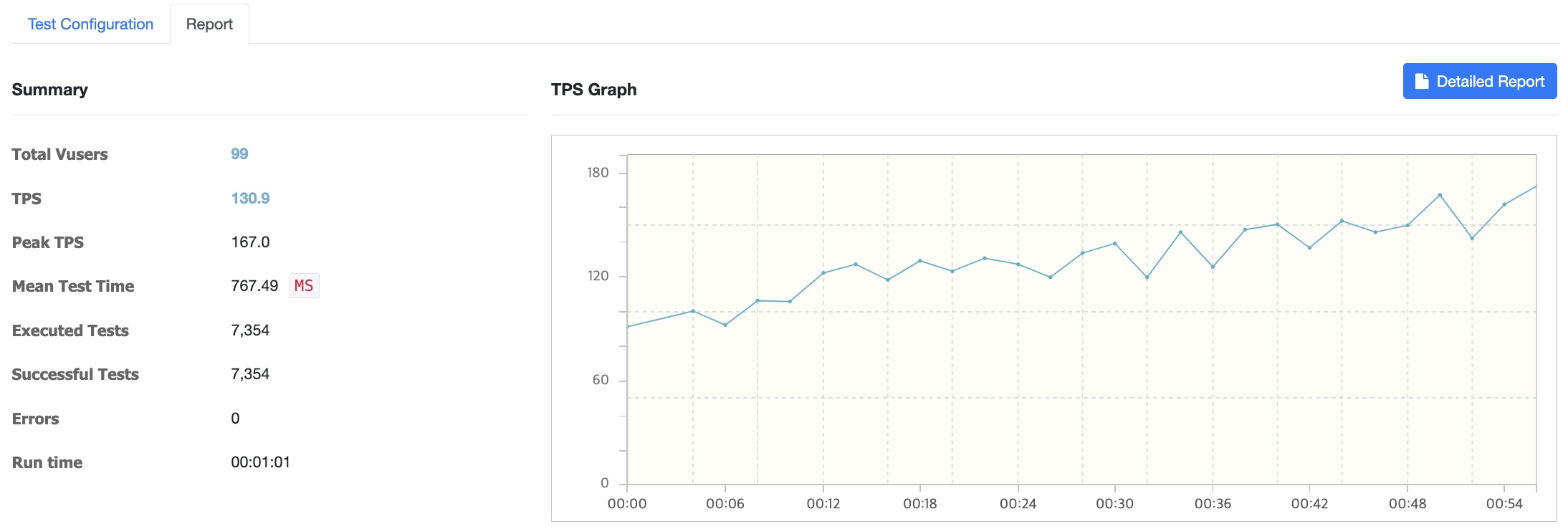
Vuser 증가
500명 -> 에러 발생
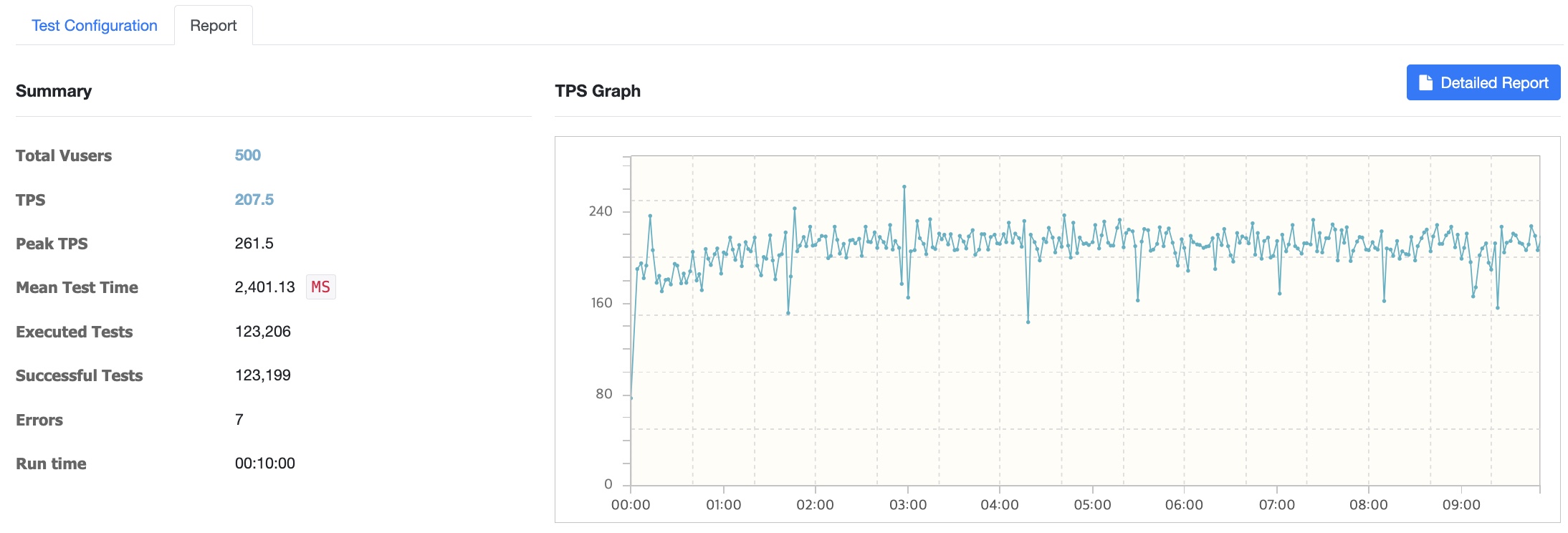
1000명 -> 에러 발생
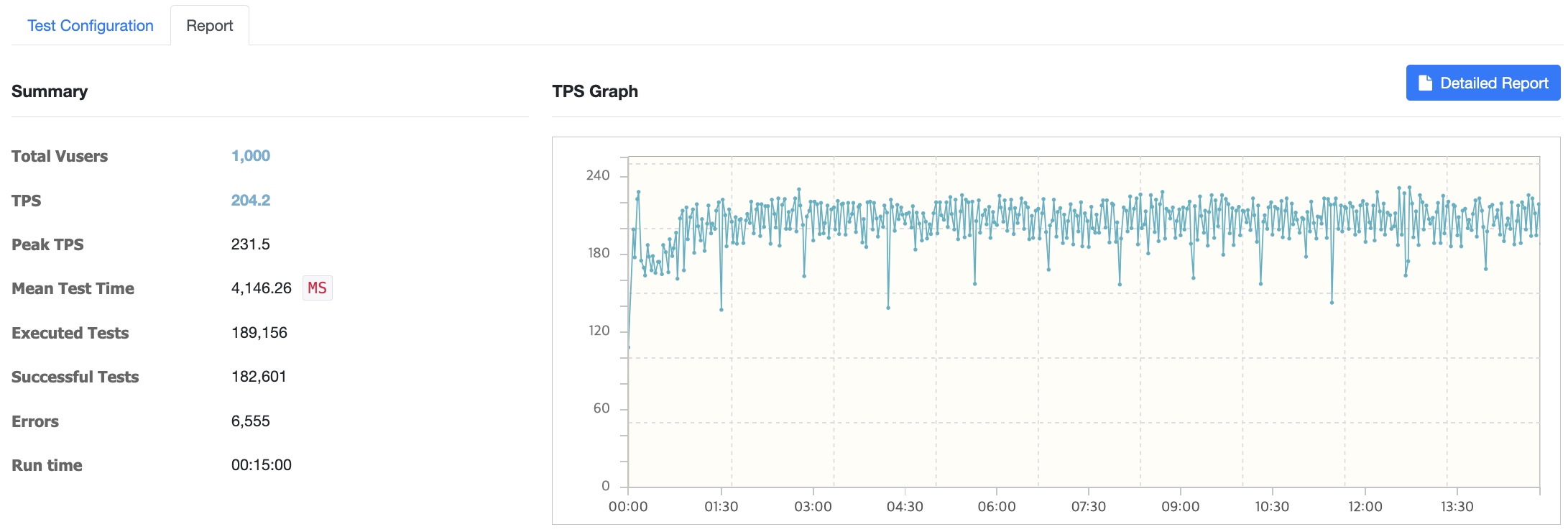
1000명 이상으로 사용자를 늘릴수록 에러가 급증하고 서버에서 Read Time Out이 나는 등 트래픽을 견뎌낼 수 없었습니다. 프로젝트 초기에 서버 설계를 할 때사용자가 늘어날 것을 대비해 서버의 대수를 늘리는 Scale Out방식을 적용하기로 결정했습니다. 또한 micro 로는 테스트가 역부족일거라 생각하여 인스턴스 유형을 t3a.large로 Scale Up하였습니다. 따라서 Nginx 웹서버 한대 띄워 이 웹서버를 거쳐 2vCPU 8GB RAM 서버 두대에 로드밸런싱을 하는 방식으로 서버 구조를 변경하고 성능테스트를 진행했습니다.
Nginx로 로드밸런싱
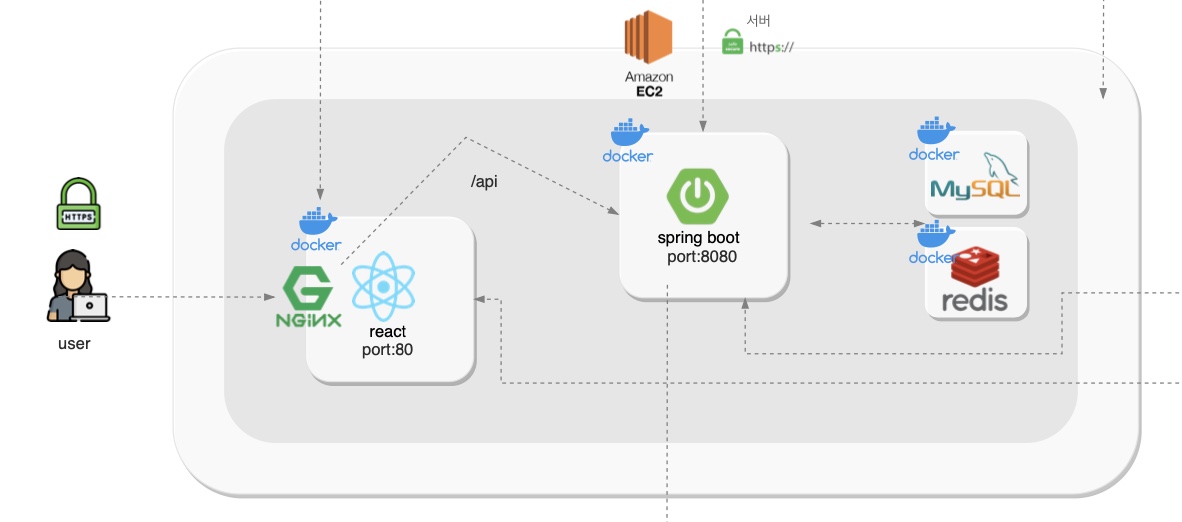
Architecture
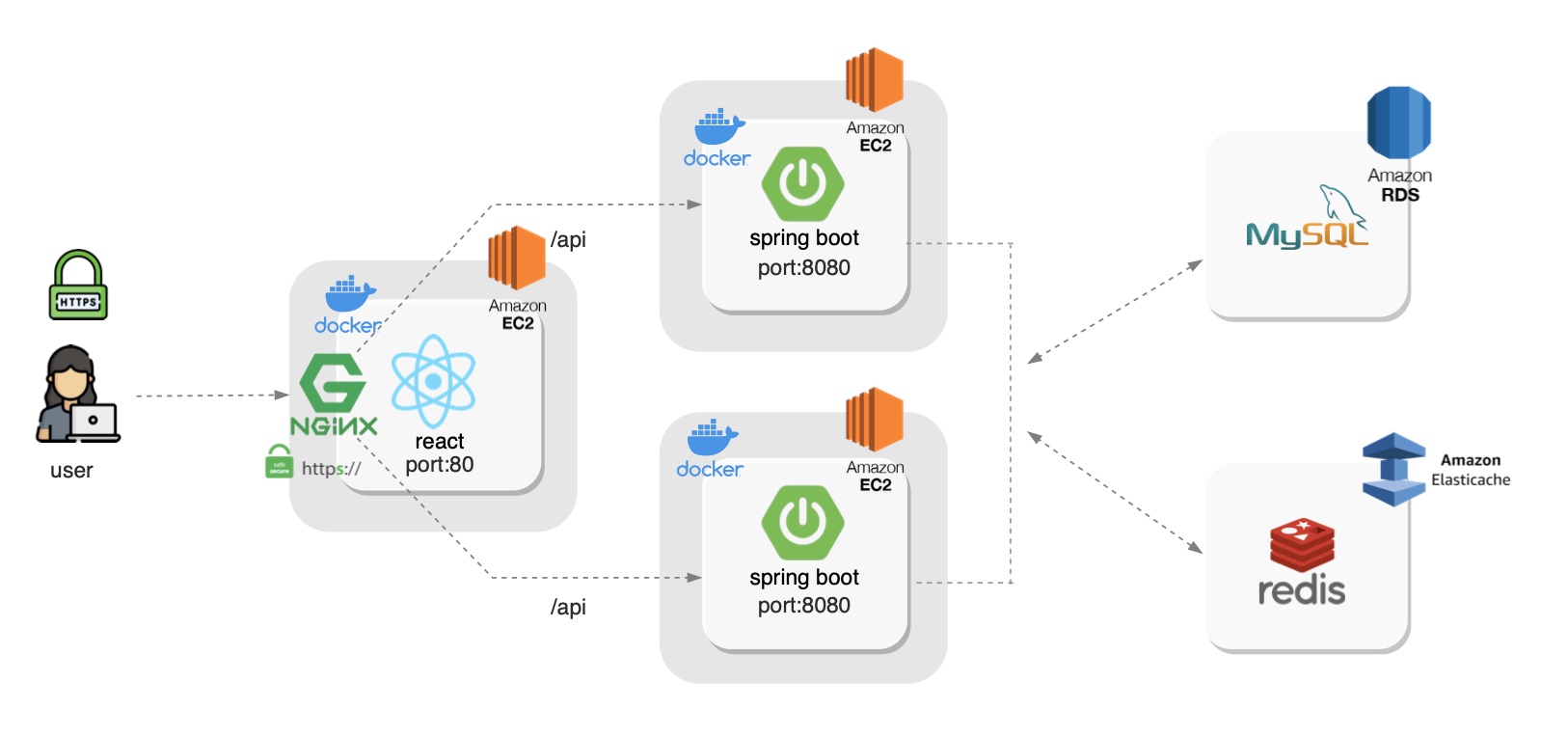
Controller(테스트 관리 및 모니터링)
- 전반적인 작업이 Controller를 통해 수행된다.
- 스트레스 테스트를 위한 웹 인터페이스를 제공한다.
- 테스트 프로세스를 체계화하며, 테스트 결과를 수집해 통계를 보여준다.
- Controller를 통해 사용자는 테스트 수행을 위한 스크립트를 생성 및 수정할 수 있다.
- 서버 사양 :
t3a.large/ 2vCPU, 8GB 메모리
Agent(실제 부하 생성)
- Controller의 명령을 받아 작업을 수행한다.
- Agent 모드시 프로세스 및 스레드를 실행시켜 Target 머신에 부하를 발생시킨다.
- Monitor 모드시 대상 시스템의 CPU 및 Memory 등을 모니터링한다.
- 서버 사양 :
t3a.large/ 2vCPU, 8GB 메모리
Target
- 테스트 대상이 되는 머신이다.
- 서버 사양 :
t3a.large/ 2vCPU, 8GB 메모리
RDS : t3.large / 2vCPUs, 8GB 메모리
ElastiCache : r6g.large 2vCPUs, 13GB 메모리
default.conf 수정
서버 1대 추가
upstream spring-app {
least_conn; # 최소 연결 수 기반 로드 밸런싱
server 172.31.11.227:8080;
server 172.31.34.63:8080;
keepalive 32; # Maximum keepalive connections per server
}
server {
listen 80;
listen [::]:80;
server_name tmarket.store;
# 모든 HTTP 요청을 HTTPS로 리디렉션
return 301 https://$host$request_uri;
}
server {
listen 443 ssl;
server_name tmarket.store;
root /usr/share/nginx/html;
include /etc/nginx/default.d/*.conf;
ssl_certificate /home/ubuntu/certificate.crt;
ssl_certificate_key /home/ubuntu/private.key;
...
location /api/ {
proxy_pass http://spring-app;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
...
}
...
}AWS t3.large 서버 (2vCPU / RAM : 8GB)
JMeter 테스트 상황
1초 동안 50명의 사용자가 거의 동시에 시스템에 액세스하고 각 사용자가 동일한 작업 세트를 100회 수행
서버 1개 (ElastiCache)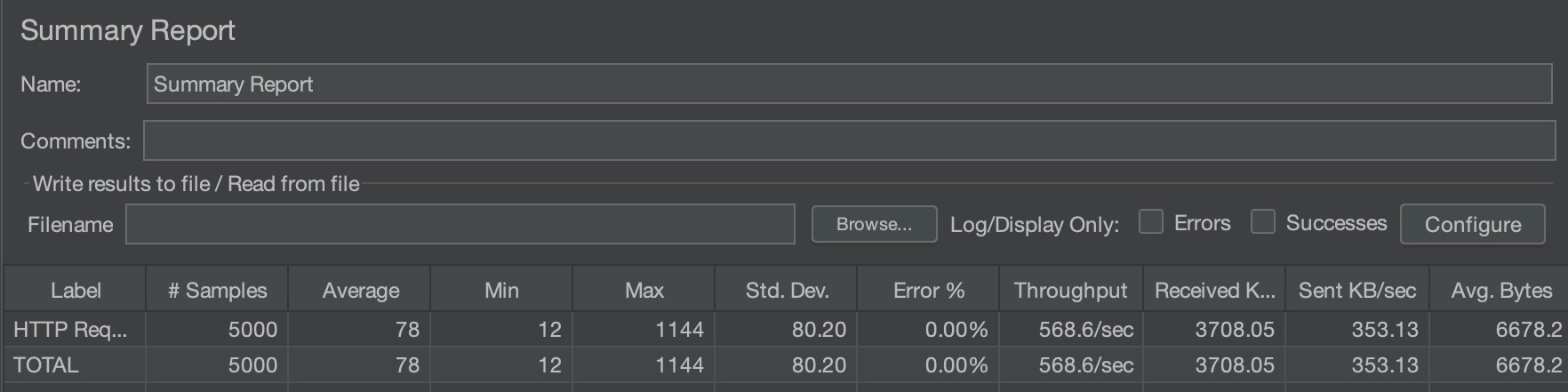
단일 서버 환경
총 5000개의 요청 처리
평균 응답시간: 78ms
최소/최대 응답시간: 12ms / 1144ms
처리량: 568.6 요청/초
표준편차: 80.20 (응답시간의 변동이 큼)
수신 데이터: 3708.05 KB/sec
서버 2개 (ElastiCache)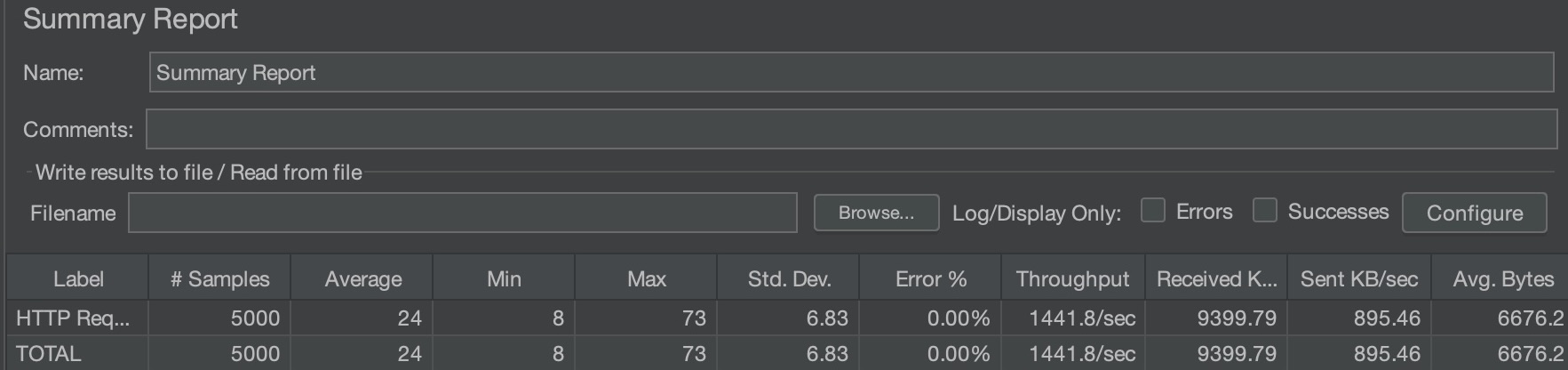
Nginx 로드밸런싱 환경
동일하게 5000개의 요청 처리
평균 응답시간: 24ms (약 3배 개선)
최소/최대 응답시간: 8ms / 73ms
처리량: 1441.8 요청/초 (약 2.5배 향상)
표준편차: 6.83 (응답시간이 매우 안정적)
수신 데이터: 9399.79 KB/sec
Vuser 증가 : 1000~4000명 테스트에서 에러율 0% 달성
서버 2대 1000명
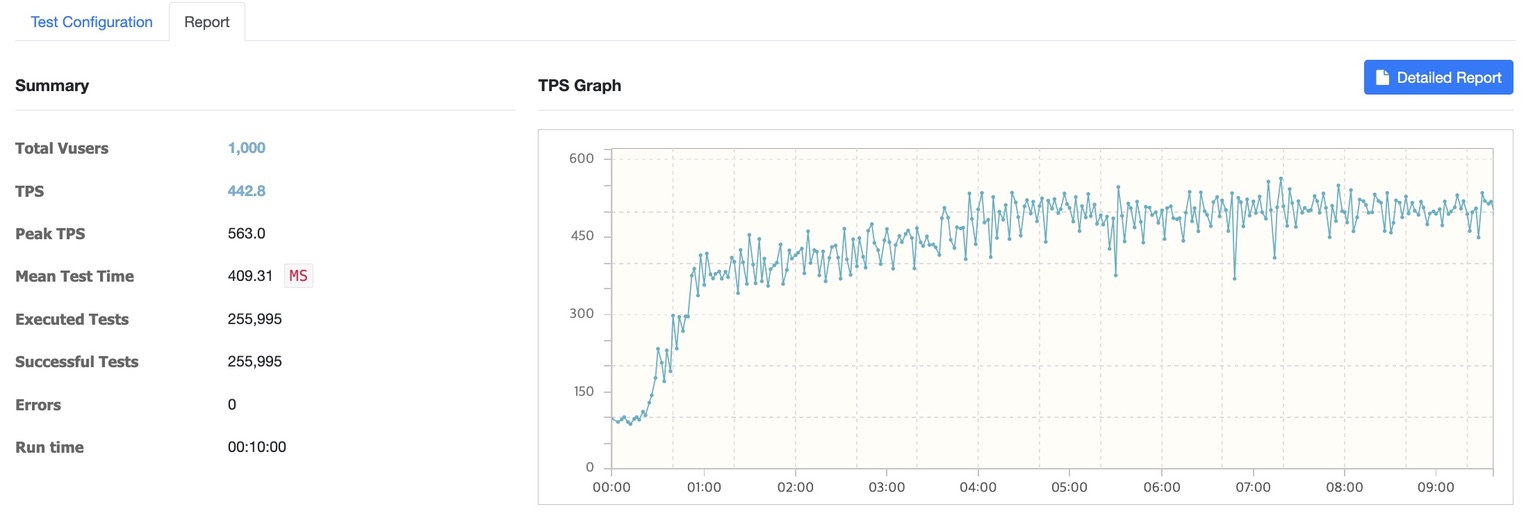
서버 2대 2000명
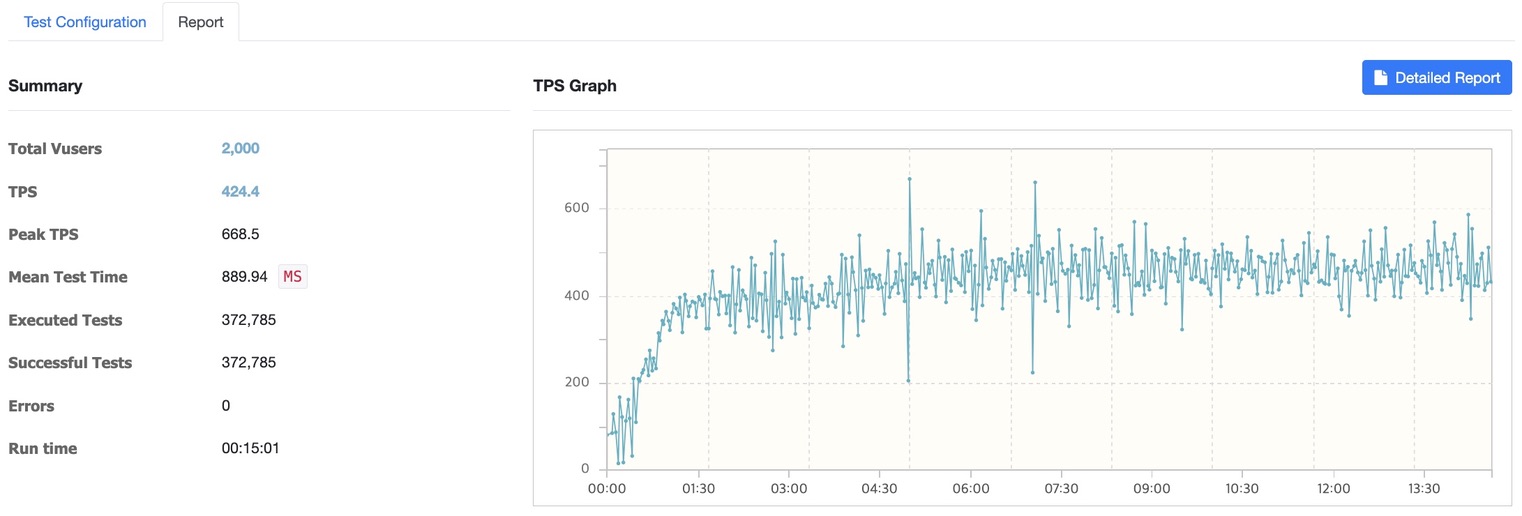
서버 2대 3000명
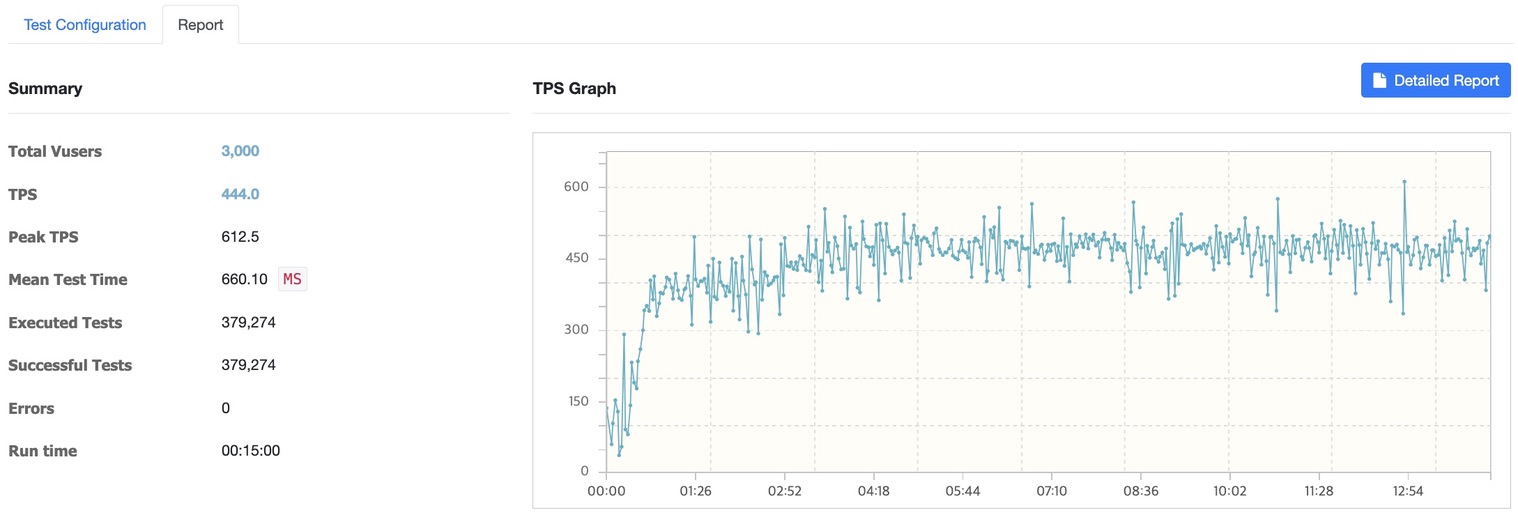
서버 2대 4000명
안정성 개선
에러율
- t3.micro 1대, M1 Pro 1대: 1000명 테스트에서 에러 발생
- t3a.large 2대: 1000~4000명 테스트에서 에러율 0% 달성
응답시간 안정성
- 1000명 테스트: 평균 응답시간 409.31ms
- 2000명 테스트: 평균 응답시간 889.94ms
- 3000명 테스트: 평균 응답시간 660.10ms
- 4000명 테스트: 평균 응답시간 661.38ms
성능 개선
TPS(처리량) 안정성
- 1000명: 442.8 TPS (Peak 563.0)
- 2000명: 424.4 TPS (Peak 668.5)
- 3000명: 444.0 TPS (Peak 612.5)
- 4000명: 443.4 TPS (Peak 651.0)
이는 부하가 증가해도 일정한 TPS를 유지함을 보여줍니다.
성능 개선의 주요 요인은 크게 세 가지 측면에서 분석할 수 있습니다.
먼저, 하드웨어 스펙 향상이 가장 큰 영향을 미쳤습니다. t3.micro에 비해 t3a.large는 동일한 2vCPU를 가지고 있지만 RAM이 1GB에서 8GB로 크게 증가하여 동시 접속자 처리 능력이 대폭 향상되었습니다.
두 번째로 Nginx를 통한 로드밸런싱 효과가 큰 역할을 했습니다. 두 대의 서버로 부하가 효과적으로 분산되면서 각 서버의 부하가 감소했고 네트워크 대역폭도 분산되어 더욱 안정적인 서비스가 가능해졌습니다. 테스트 결과를 보면 처리량이 568.6/sec에서 1441.8/sec로 크게 향상된 것을 확인할 수 있습니다.
마지막으로 t3a.large 인스턴스의 안정적인 CPU 성능이 중요한 요인이 되었습니다. 기본 CPU 성능이 20%로 보장되며 필요할 때 버스트 크레딧을 사용하여 피크 타임에 대응할 수 있습니다. 또한 EBS 최적화 인스턴스로서 디스크 I/O 성능도 향상되어 전반적인 시스템 안정성이 크게 개선되었습니다. 이는 평균 응답시간이 78ms에서 24ms로 감소하고, 표준편차가 80.20에서 6.83으로 크게 줄어든 결과로 확인할 수 있습니다.
서버 비용 문제로 테스트를 중단했지만, 현재 t3a.large 인스턴스 2대로 구성된 시스템에서 더 높은 TPS를 달성하기 위해 t3a.xlarge, t3a.2xlarge로의 인스턴스 업그레이드를 통해 시스템 처리 능력을 향상시키려고 합니다.
