💥 문제상황

일반 사용자가 문의사항 생성 시 관리자에게 알람을 보내는 경우, sse(알람)에서 오류가 발생할 시 문의사항 작성이 끝까지 완료되지 않아 본래 하고자했던 api까지 실행이 되지 않는 심각한 오류가 발생한다.(의존성⬆️)
-> 문의사항 생성 로직과 sse 알람 프로세스를 분리하자!!
SSE의 현재 문제
- 사용자가 문의사항을 생성한다.
- SSE를 통해 관리자에게 실시간 알림을 보낸다.
- SSE 프로세스에 오류가 있는 경우(예: 네트워크 문제, SSE 연결 문제, 서버 측 문제)문의사항 생성 전체가 실패한다.
- 문의사항 생성과 SSE 알림의 긴밀한 결합은 사용자의 작업이 2차 알림 프로세스의 성공에 달려 있음을 의미하며 이는 이상적이지 않다.
💡 해결방안 : 문의 및 알림을 분리하는 Kafka
-> kafka를 사용하여 문의사항 생성 시 알람을 비동기적으로 처리
Kafka를 사용한 workflow
- 사용자가 문의사항 생성(주요 작업) : 사용자가 문의사항을 생성하면 SSE 알림에 대한 종속성 없이 문의를 데이터베이스에 저장하거나 처리하는 핵심 기능이 즉시 완료된다. 이는 SSE 알림에 어떤 일이 발생하는지에 관계없이 성공해야 하는 기본 작업이다.
- Kafka에 이벤트 생성(중간 단계) :
- 문의사항 생성이 성공적으로 처리되면 SSE 알림을 직접 보내는 대신 Kafka topic에 이벤트(예: 'NewInquiryEvent')를 게시한다. 이 단계는 생성 로직과 SSE 프로세스 모두에서 분리된다.
- 이렇게 하면 생성 프로세스가 알림 메커니즘에서 분리되고, Kafka에 문제가 있어도 문의사항 생성 자체에는 영향을 미치지 않는다. Kafka는 일반적으로 메시지 지속성을 통해 내결함성을 갖도록 설계되었기 때문이다.
- Kafka 소비자가 SSE 알림을 처리한다 : Kafka 소비자는 주제를 듣고 이벤트를 읽고 관리자에게 SSE 알림을 트리거한다.
- 별도의 Kafka 소비자(백그라운드 서비스 또는 마이크로서비스로 실행)는 inquiry-notifications 주제를 구독할 수 있다. 이 소비자는 Kafka의 이벤트를 처리하고 관리자에게 실제 SSE 알림을 트리거하는 일을 담당한다.
- SSE 알림은 소비자에 의해 비동기식으로 처리되므로 생성 프로세스에 성능 병목 현상이 발생하지 않는다.
- 재시도 논리 및 오류 처리 :
- SSE가 실패하는 경우(예: 연결 오류, 관리자 오프라인 또는 기타 문제로 인해) 문의사항 생성이 아닌 알림 프로세스에만 영향을 미친다.
- SSE 오류가 발생하는 경우(예: 관리자의 SSE 연결이 끊어진 경우) 이벤트는 여전히 Kafka에 남아 있으며 관리자가 다시 연결하거나 서비스가 복구되면 처리된다.
- SSE 알림이 실패하면 소비자는 재시도 로직을 구현하여 나중에 알림 전송을 다시 시도할 수 있다.
- 또는 Kafka에서 Dead Letter Queue(DLQ)(소비되지 못한 메시지가 이동할 수 있는 Queue 또는 Topic) 을 구성할 수 있다. 여기서 핵심 비즈니스 논리를 방해하지 않고 향후 분석 또는 재시도를 위해 실패한 알림이 저장된다.
- Kafka는 내결함성 분산 메시징을 위해 설계되었다. Kafka 소비자 또는 SSE 서비스가 일시적으로 중단되더라도 메시지(조회 이벤트)가 저장되고 손실되지 않도록 보장한다.
Kafka 핵심 개념
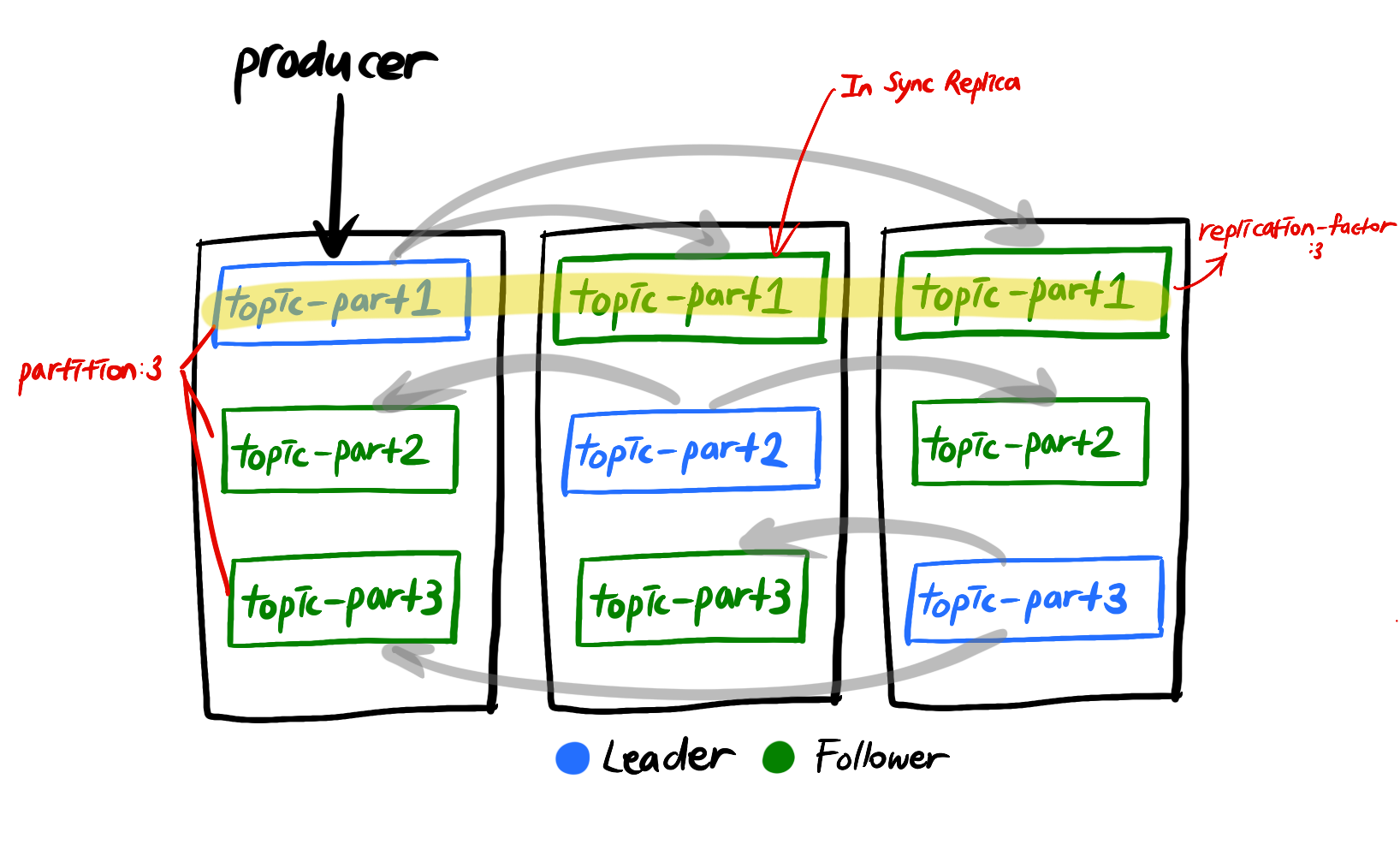
Broker, Replication, In Sync Replica(ISR) for High Availability
Broker
kafka 서버를 말한다.
- 가용성을 위해서 broker를 3이상 유지하는 것이 권장된다.
Replication(Partition의 복제)
- 가용성을 위해 topic의 partition을 서로 다른 여러 broker에 복제하여 저장하는 것을 말한다.
- DB Replication등과 다르게 Replica partition에서 Read역할 만해준다거나 하는 부하 분산의 역할은 하지 못하고 단순히 leader partition의 fail-over시 복구 하기 위한 용도로서 replication을 수행한다.
- 특정 브로커가 leader, follwer로 구분되어있는 것이 아니라 partition 마다 모두 다르다.
- 일반적인 database에서의 replication과는 다르게 leader에는 아예 요청이 가지 않는다. 단순히 레코드 저장을 보장해주는 역할만 수행한다.
- 카프카는 하나의 토픽에 여러 개의 파티션이 존재할 수 있고, 각 파티션에는 여러 개의 복제본(Replicas) 으로 나누어져 있다. 그리고 카프카 그 자체라고 부를 수 있는 Broker는 특정 파티션에 대한 읽기와 쓰기 작업을 처리하는 역할을 한다. 이 때 각 파티션에는 Leader와 Follower라는 역할로 나누어져 있다.
- 만약 replication이 1이라면 partition은 한 개만 존재한다.
- replication이 2라면 partition은 원본 한 개와 복제본 한 개로 총 두 개가 존재한다.
- replication이 3이라면 partition은 원본 한 개와 복제본 두 개로 총 세 개가 존재한다.
- broker 갯수에 따라서 replication 갯수가 달라진다.
- broker 갯수가 3이면 replication 갯수는 4가 될 수 없다.
- 원본 partition은
leader partition, 나머지 복제본 partition은follwer partition이라고 부른다.
3개 이상의 broker를 사용할 때 replication은 3으로 설정하는 것을 추천한다.
In Sync Replica(leader partition + follwer partition)
- leader 파티션과 다른 broker들에 저장된 replica를 묶어
ISR이라고 한다.
- 만약 Replication이 2이면 broker 1개가 죽더라도 복제본, 즉
follwer partition이 존재하므로 복구가 가능하다. - Replication 개수를 지정하여 ISR에 묶일 partition의 개수를 지정할 수 있다(적어도 2개이상 으로 하는 것이 바람직하다).
leader partition+follwer partition의 역할은?
leader partition: producer가 topic의 parition에 데이터를 전달할 때 전달받는 주체
Spring 구현
application.yml
kafka:
bootstrap-servers: 43.203.173.204:9092,3.36.131.169:9092,3.39.0.214:9092
consumer:
group-id: notification
auto-offset-reset: latest
key-deserializer: org.apache.kafka.common.serialization.LongDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
properties:
spring:
json:
trusted.packages: "com.market.domain.notification.entity"
producer:
key-serializer: org.apache.kafka.common.serialization.LongSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
retries: 3
acks: all
listener:
ack-mode: MANUAL
topic:
notification: inquiry-notification
consumer.auto-offset-reset: latest
- 이전 오프셋 정보가 없을 때 소비자가 최신 오프셋부터 읽기 시작하도록 하려는 경우에 적합하다.
producer.retries: 3
- 메시지 전달이 실패하면 최대 3번까지 재시도한다.
producer.acks(acknowledgements): all
- 생산자가 Kafka 브로커에 메시지를 전달하는 데 대한 내구성과 신뢰성 수준을 결정하는 구성
- 가장 높은 수준의 승인을 의미하며 가장 강력한 전달 보장을 보장한다.
listener.ack-mode: MANUAL
- 이는 Kafka가 자동으로 처리하는 대신 각 메시지를 처리한 후 수동으로 메시지 확인을 제어하려는 경우에 중요하다.
- 명시적 승인: 소비자는 메시지를 확인하기 위해 명시적으로 메서드(사용되는 프레임워크에 따라 ack.acknowledge())를 호출해야 한다.
public class NotificationConsumer { private final NotificationService alarmService; @KafkaListener( topics = "${spring.kafka.topic.notification}", groupId = "notification", containerFactory = "kafkaListenerContainerFactory") public void consumeNotification(NotificationEvent event, Acknowledgment ack) { log.info("Consume the event {}", event); alarmService.send(event.getType(), event.getArgs(), event.getReceiverNo()); ack.acknowledge(); log.info("Acknowledged the event {}", event); } }- 데이터베이스 작업이 성공적으로 완료된 후에만 메시지가 승인되도록 할 수 있다. 어떤 이유로 데이터베이스 쓰기가 실패하면 메시지가 승인되지 않고 Kafka는 이를 소비자에게 다시 전달한다.
topic.min.insync.replicas: 2
- Kafka가 쓰기 성공으로 간주하기 위해 사용 가능하고 최신 상태여야 하는 동기화 복제본(ISR)의 최소 수를 정의한다.
- 브로커의 개수가 min.insync.replicas 옵션 값보다 같거나 많아야 한다.
- 이는 데이터 내구성과 쓰기 가용성의 균형을 맞추기 위해 생산자의
acks설정과 함께 사용된다.acks:all설정 시 min.insync.replicas도 2 이상으로 변경해 주어야 한다.- topic에는 각 파티션의 3개 사본이 있다(리더 1개 및 팔로워 2개). Kafka는 3개의 복제본 중 최소 2개(리더 + 최소 1명의 팔로워)가 동기화된 경우에만 쓰기를 승인하고 쓰기를 확인한다.
- 1개의 복제본이 뒤처지거나 실패함: 하나의 팔로어 복제본을 사용할 수 없는 경우(예: 네트워크 지연 또는 브로커 장애로 인해) 2개의 복제본만 동기화된다. min.insync.replicas=2이기 때문에 Kafka는 계속해서 쓰기를 허용한다. 리더와 한 명의 팔로어는 여전히 쓰기를 승인할 수 있기 때문이다.
- 2개의 복제본이 뒤처지거나 실패: 리더가 동기화된 유일한 복제본인 경우 Kafka는 쓰기 요청을 거부한다.
이렇게 하면 데이터가 여러 위치에 저장된 경우에만 쓰기가 성공하도록 보장하여 잠재적인 데이터 손실을 방지한다.topic.partitions: 3
- 하나의 리더와 두 개의 복제본(팔로워)
- Kafka 에서는 가용성을 위해 replication 을 제공한다. 이 때 kafka 에서 replication은 각 Topic 의 partition 들을 다른 브로커들로 복제하는 것을 말한다.
- 리더가 무너지면 추종자 중 한 명이 그 자리를 대신할 수 있다.
topic.replication-factor: 3
- 토픽의 파티션 복제본 개수
- 각 파티션이 Kafka 브로커 전체에 3개의 복사본을 갖게 되며 그 중 하나는 리더이고 다른 하나는 팔로워(복제본)
acks = all 일 때 min.in-sync.replicas = 2로 설정해야 하는 이유는 무엇일까?
acks = all: 리더는 ISR의 팔로워로부터 데이터에 대한 ack를 기다리고, 하나의 팔로워가 있는 한 데이터는 손실되지 않으며 데이터 무손실에 대해 가장 강력하게 보장ISR:In Sync Replica의 약어로 (leader partition+follwer partition) 현재 리플리케이션이 되고 있는 리플리케이션 그룹(replication group) 을 의미, Leader와 동기화된 상태를 유지하고 있는 복제본(replicas)의 집합, 최소 복제본 수, ISR의 크기(최소 복제본 수)는 Broker의 옵션 중 하나인 min.insync.replicas 속성을 통해서 설정할 수 있다min.insync.replicas: 최소 리플리케이션 팩터를 지정하는 옵션, 프로듀서가 acks=all로 설정하여 메시지를 보낼 때 필요한 최소 복제본의 수Replication Factor는 토픽의 파티션의 복제본을 몇 개를 생성할지에 대한 설정
KafkaTopicConfig
@Configuration
public class KafkaTopicConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Value("${kafka.topic.notification}")
private String topicName;
@Value("${kafka.topic.min.insync.replicas}")
private String minInSyncReplicas;
@Value("${kafka.topic.partitions}")
private int partitions;
@Value("${kafka.topic.replication-factor}")
private short replicationFactor;
@Bean
public AdminClient adminClient() {
Map<String, Object> config = new HashMap<>();
config.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
return AdminClient.create(config);
}
@Bean
public NewTopic createTopic() throws ExecutionException, InterruptedException {
Map<String, String> topicConfigs = new HashMap<>();
topicConfigs.put(TopicConfig.MIN_IN_SYNC_REPLICAS_CONFIG, minInSyncReplicas);
NewTopic newTopic = new NewTopic(topicName, partitions, replicationFactor).configs(topicConfigs);
adminClient().createTopics(Collections.singletonList(newTopic)).all().get(); // 주제 생성이 완료되었는지 확인
return newTopic;
}
}
- AdminClient는 Kafka 클러스터를 프로그래밍 방식으로 관리하고 상호 작용할 수 있게 해주는 Apache Kafka API의 일부이다. 주제 생성, 삭제, 나열 및 수정, 브로커, 파티션 및 구성 관리, 클러스터 메타데이터 수집을 위한 관리 기능을 제공한다.
- 주제 및 브로커와 같은 Kafka 개체를 관리하고 검사하기 위한 Kafka API
InquiryServiceImpl (문의사항 생성 시 관리자에게 알람)
public class InquiryServiceImpl implements InquiryService {
@Override
@Transactional
public InquiryResponseDto createInquiry(InquiryRequestDto inquiryRequestDto, Member member,
List<MultipartFile> files) throws IOException {
private final NotificationService notificationService;
private final NotificationProducer notificationProducer; // kafka
...
/*관리자에게 알람*/
List<Member> adminList = memberRepository.findAllByRole(Role.ADMIN);
// 관리자 리스트가 비어있지 않은지 확인
if (adminList.isEmpty()) {
throw new BusinessException(ErrorCode.NOT_EXISTS_ADMIN);
}
NotificationArgs notificationArgs = NotificationArgs.of(member.getMemberNo(),
inquiry.getInquiryNo());
// 모든 관리자에게 알림 전송
for (Member admin : adminList) {
/* notificationService.send(
NotificationType.NEW_INQUIRY, notificationArgs, admin.getMemberNo());*/
// kafka
notificationProducer.send(
new NotificationEvent(NotificationType.NEW_INQUIRY, notificationArgs,
admin.getMemberNo()));
}
return InquiryResponseDto.of(inquiry);수정 사항은 Kafka 이벤트를 사용하여 문의사항 답변 생성 시 알림을 비동기적으로 처리하는 것이다. 원래 코드는 직접적으로
notificationService.send()메서드를 호출하여 알림을 전송하고 있지만 Kafka 이벤트를 사용하여NotificationConsumer가 해당 알림을 처리하도록 변경했다.
KafkaProducerConfig
@Configuration
public class KafkaProducerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
/**
* In-Sync-Replica 에 모두 event 가 저장되었음이 확인 되어야 ack 신호를 보냄.
* 가장 성능은 떨어지지만 event produce 를 보장할 수 있음.
*/
@Value("${spring.kafka.producer.acks}")
private String acksConfig;
@Bean
public ProducerFactory<Long, NotificationEvent> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
configProps.put(ProducerConfig.ACKS_CONFIG, acksConfig);
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, LongSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<Long, NotificationEvent> alarmEventKafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}NotificationProducer
@Slf4j
@Component
@RequiredArgsConstructor
public class NotificationProducer {
private final KafkaTemplate<Long, NotificationEvent> alarmEventKafkaTemplate;
@Value("${spring.kafka.topic.notification}")
private String topic;
public void send(NotificationEvent event) {
log.info("send start");
alarmEventKafkaTemplate.send(topic, event.getReceiverNo(), event);
log.info("send fin");
}
}이벤트 생성 (Producer)
notificationProducer.send메서드가 호출되면 Kafka를 사용해 NotificationEvent 객체를 Kafka topic에 비동기적으로 알림 이벤트가 전송된다. 이 과정에서 프로듀서에서 이벤트를 Kafka 브로커로 보낸 후, 소비자가 해당 이벤트를 소비하여 처리한다.
이를 위해 문의사항 답변 생성 코드에서 알림을 직접 보내는 대신 NotificationEvent를 생성하고 Kafka로 해당 이벤트를 전송하도록 수정해야 한다. 그리고 NotificationConsumer는 Kafka를 통해 수신된 NotificationEvent를 처리하여 알림을 전송한다.
alarmEventKafkaTemplate.send(topic, key, value):
- topic : 이벤트가 전송될 Kafka 주제 이름이다. 여기서는 spring.kafka.topic.notification에 정의된 주제이다.
- key : 이 경우 이벤트 수신자의 ID로, event.getMemberNo() 값을 사용한다.
- Kafka 파티셔닝에서 이 키를 기준으로 이벤트가 특정 파티션으로 전송될 수 있다.
- Kafka는 이 키를 해시하여 메시지를 보낼 파티션을 결정한다.
- 동일한 키를 가진 모든 메시지는 순서를 유지하면서 동일한 파티션으로 이동한다.
- value: NotificationEvent 객체이다. 알림의 타입, 알림 정보 및 수신자 정보를 포함한다.
비동기 전송: 이 호출은 비동기로 수행되므로 send 메서드는 Kafka에 이벤트를 전송한 즉시 종료된다.public CompletableFuture<SendResult<K, V>> send(String topic, K key, @Nullable V data) { ProducerRecord<K, V> producerRecord = new ProducerRecord(topic, key, data); return this.observeSend(producerRecord); }카프카 브로커로 데이터를 보내기 위해 ProducerRecord를 생성한다. ProducerRecord를 전송하기 위해 record를 파라미터로 가지는
observeSend()메서드를 호출했다.private CompletableFuture<SendResult<K, V>> observeSend(final ProducerRecord<K, V> producerRecord) { Observation observation = KafkaTemplateObservation.TEMPLATE_OBSERVATION.observation(this.observationConvention, DefaultKafkaTemplateObservationConvention.INSTANCE, () -> { return new KafkaRecordSenderContext(producerRecord, this.beanName, this::clusterId); }, this.observationRegistry); try { observation.start(); // 관찰 시작 return this.doSend(producerRecord, observation); // 실제 메시지 전송 } catch (RuntimeException var4) { if (observation.getContext().getError() == null) { observation.error(var4); // 오류 기록 observation.stop(); // 관찰 중지 } throw var4; // 예외 재발생 } }observeSend()메서드는 Kafka 메시지 전송 시 관찰(Observation) 기능을 추가한 메서드이다.
메서드 목적은 Kafka 메시지 전송 과정을 관찰(모니터링)과 메시지 전송 시 성능 추적 및 오류 관리이다.
메시지 전송에 대한 관찰(Observation) 객체 생성하고 메시지, 빈 이름, 클러스터 ID 등의 컨텍스트 정보 포함한다.메시지 전송 시도하고 예외 발생 시 오류 기록 및 관찰 중지한다.
비동기 메시지 전송 (CompletableFuture 반환)
KafkaConsumerConfig
@EnableKafka
@Configuration
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Value("${spring.kafka.consumer.auto-offset-reset}")
private String autoOffsetResetConfig;
@Value("${spring.kafka.consumer.group-id}")
private String groupId;
@Bean
public ConsumerFactory<Long, NotificationEvent> consumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetResetConfig);
JsonDeserializer<NotificationEvent> jsonDeserializer = new JsonDeserializer<>(NotificationEvent.class);
jsonDeserializer.addTrustedPackages("*");
return new DefaultKafkaConsumerFactory<>(props, new LongDeserializer(), jsonDeserializer);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<Long, NotificationEvent> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Long, NotificationEvent> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL);
return factory;
}
}
NotificationConsumer
@Slf4j
@Component
@RequiredArgsConstructor
public class NotificationConsumer {
private final NotificationService alarmService;
@KafkaListener(
topics = "${spring.kafka.topic.notification}", // topics 속성을 사용하여 리스너가 메시지를 소비해야 하는 Kafka 주제를 지정할 수 있다. 리스너는 지정된 주제를 자동으로 구독한다.
groupId = "notification", // groupId 속성은 리스너가 속한 소비자 그룹을 지정하는 데 사용된다. 동일한 그룹 ID를 가진 Kafka 소비자는 구독 주제의 메시지 처리 작업을 공유하여 병렬성과 로드 밸런싱을 제공한다.
containerFactory = "kafkaListenerContainerFactory") // containerFactory 속성을 사용하면 기본 Kafka 메시지 리스너 컨테이너를 생성하는 데 사용되는 Bean 의 이름을 지정할 수 있다. 이를 통해 동시성, 승인 모드, 오류 처리 등 컨테이너의 다양한 속성을 유연하게 사용자 지정할 수 있다.
public void consumeNotification(NotificationEvent event, Acknowledgment ack) {
log.info("Consume the event {}", event);
alarmService.send(event.getType(), event.getArgs(), event.getReceiverNo());
ack.acknowledge();
log.info("Acknowledged the event {}", event);
}
}이벤트 소비 (Consumer)
NotificationConsumer 클래스에서 @KafkaListener를 사용하여 notification 주제를 구독하고 있다. Kafka 브로커는 이 소비자에게 NotificationEvent를 전달한다.
이벤트가 브로커에서 소비자에게 전송되면 consumeNotification 메서드가 자동으로 호출된다.
전체 흐름 요약
1. createInquiry 메서드에서 notificationProducer.send가 호출된다.
2. notificationProducer.send는 KafkaTemplate을 사용해 이벤트를 Kafka 브로커에 비동기적으로 전송한다.
3. Kafka 브로커는 topic을 구독 중인 NotificationConsumer에게 이벤트를 전달한다.
4. NotificationConsumer.consumeNotification 메서드가 이벤트를 처리하여 실제 알림을 전송하는 NotificationService.send를 호출한다.
5. ack.acknowledge()로 이벤트가 성공적으로 처리되었음을 Kafka에 알린다.
출력화면

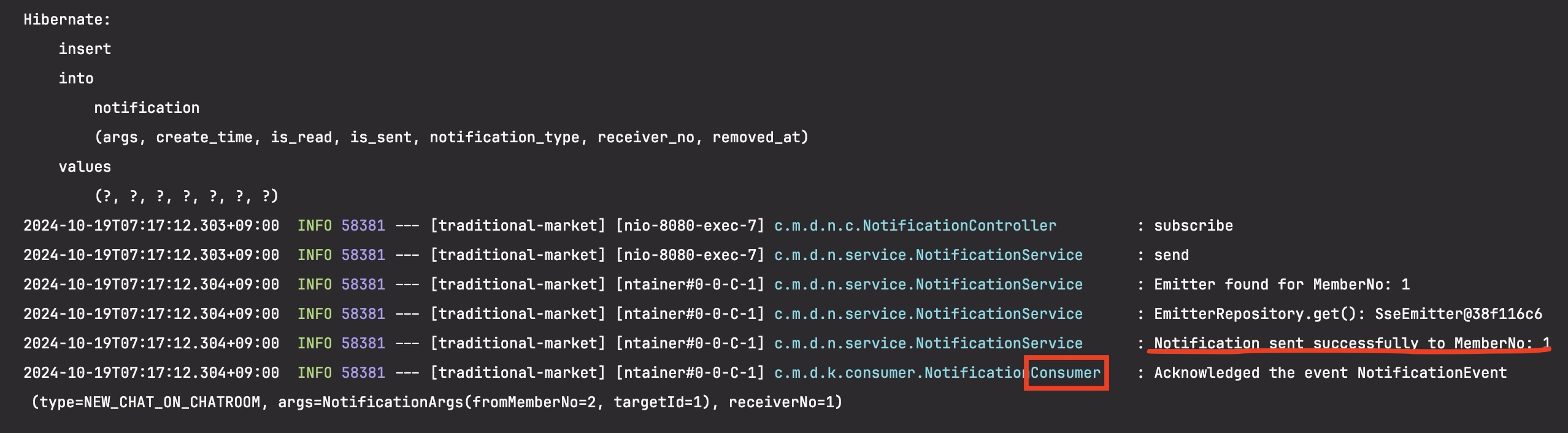
이와 같이 Kafka를 이용해 알림 이벤트가 비동기적으로 처리되므로 생산자와 소비자가 느슨하게 결합되어 확장성 및 유지 보수성을 높일 수 있다.
⭐️AWS에 카프카 클러스터 설치, 실행
카프카 고가용성의 핵심은 3개 이상의 카프카 broker로 이루어진 클러스터에서 진가를 발휘하게 된다.(멀티 브로커로 구축)
- AWS로 EC2 3대 발급
테스트 목적의 머신이므로 Amazon Linux 2 AMI(Amazon Machine Image)를 t2.micro로 발급받는다.
1-1. Mac OS 터미널을 이용한 EC2 접속
AWS의 EC2 인스턴스 페이지에서 1개의 인스턴스 클릭 후 연결 클릭
인스턴스 액세스 방법 3번 아래의 명령어 복사 -> EC2 접속
yes 입력 후 해당 창이 뜨면 접속 성공
root 계정으로 접속
hostname 변경 (ex. test-broker01)
- 방화벽 설정 및 /etc/hosts 설정
zookeeper와 카프카 클러스터가 각각 통신을 하기 위해서는 아래와 같이 inbound규칙을 추가해야 한다.
기본적으로 aws ec2를 발급받은 뒤 security group의 기본설정은 outbound에 대해 anywere로 open되어 있으므로 inbound만 추가해 준다.
추가해야할 port는 아래와 같다. 각 port는 anywhere 기준으로 열도록 한다.
// 만약 test-broker01인 경우
0.0.0.0 test-broker01
14.252.123.4 test-broker02
55.231.124.1 test-broker03기본적으로 SSH 22번 포트만 설정되어 있다.
각자의 /etc/hosts 파일을 편집해 이름 지정
테스트의 편의를 위해 이번에 만든 3개의 인스턴스의 이름은 test-broker01, 02, 03으로 지정하여 진행한다.자기자신의 host는 0.0.0.0으로 설정하고 나머지 host는 ip로 할당되도록 설정해 준다.
- 각 서버 접속 후 wget 명령어로 Zookeeper 설치
이제 실질적인 애플리케이션 설치 및 실행을 하도록 한다. 여기부터는 3개의 인스턴스(노드)에 모두 동일하게 진행하면 된다.
zookeeper 설치를 위해 아래 명령어로 zookeeper 3.4.12 압축파일을 다운받아 준다.
wget https://downloads.apache.org/zookeeper/zookeeper-3.7.2/apache-zookeeper-3.7.2-bin.tar.gz다운받은 zookeeper 압축파일은 아래 명령어로 풀어준다.
tar xvf apache-zookeeper-3.7.2-bin.tar.gz vi zoo.cfg zoo.cfg 파일 생성
(vi 명령어는 기본적으로 파일의 내용을 편집하는 것)
(파일이 존재하지 않을 경우 파일을 생성하여 편집창을 띄운다)
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
initLimit=20
syncLimit=5
server.1=test-broker01:2888:3888
server.2=test-broker02:2888:3888
server.3=test-broker03:2888:3888- tickTime
- 기준 시간 (현재 2초)
- dataDir
- zookeeper의 상태, 로그 등을 저장하는 디렉토리 위치 지정
- clientPort
- client 의 연결을 감지하는 port
- initLimit
- follower 가 leader와 처음 연결을 시도할 때 가지는 tick 횟수. 제한 횟수 넘으면 timeout<br>
(현재 40초로 설정) (tickTime * initLimit)
- syncLimit
- follower 가 leader와 연결 된 후에 앙상블 안에서 leader와의 연결을 유지하기 위한 tick 횟수
- 제한 횟수 넘으면 time out
- (현재 10초로 설정) (tickTime * syncLimit)
- server.(zookeeper_server.pid의 내용)=(host name 이나 host ip):2888:3888
- 앙상블을 이루기 위한 서버의 정보
- 2888은 동기화를 위한 포트, 3888은 클러스터 구성시 leader를 산출하기 위한 포트
- 여기서 서버의 id 를 dataDir 에 설정해 줘야 한다.
- (서버id 설정 경로 : /var/lib/zookeeper 의 zookeeper_server.pid 파일) 이제 zookeeper 앙상블을 만들기 위해 각 zookeeper마다 myid라는 파일을 만들어줘야 한다.
myid의 위치는 /var/lib/zookeeper/myid 이고, 해당 파일에는 숫자를 하나 넣으면 된다.
test-broker01은 1, test-broker02는 2, test-broker03은 3 으로 지정한다.
// 만약 test-broker01에서 실행한 경우 1이 나와야함
cat /var/lib/zookeeper/myid // 만약 test-broker01에서 실행한 경우 1이 나와야함
cat /var/lib/zookeeper/zookeeper_server.pidOpenJDK 설치
yum install java-1.8.0-openjdk-devel.x86_64이제 zookeeper을 실행한다.
./bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/ec2-user/zookeeper-3.7.2/bin/../conf/zoo.cfg
Strating zookeeper ... STARTED주키퍼가 정상적으로 실행됨
주키퍼 상태 확인 -> 3. `./zkServer.sh status`
- Kafka 설치
zookeeper가 설치완료되었으니 이제 kafka를 다운받고 실행.
wget https://archive.apache.org/dist/kafka/2.6.0/kafka_2.12-2.6.0.tgz마찬가지로 아래 명령어를 통해 압축을 풀어준다.
tar xvf kafka_2.12-2.6.0.tgzkafka실행을 위해서 broker.id 설정, zookeeper에 대한 설정과 listener설정을 아래와 같이 설정한다. 대상 파일은 kafka 폴더 내부에 config/server.properties 이다.
// test-broker01인 경우 아래와 같이 설정합니다.
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://test-broker01:9092
zookeeper.connect=test-broker01:2181,test-broker02:2181,test-broker03/test참고로 zookeeper 설정시 마지막에 /test 와 같이 route를 넣는 것을 추천한다.
이렇게 넣을 경우 zookeeper의 root node가 아닌 child node에 카프카정보를 저장하게 되므로 유지보수에 이득이 있다.
이제 kafka를 실행해본다.
./bin/kafka-server-start.sh ./config/server.properties- console-producer,consumer 테스트
로컬컴퓨터에서 카프카 클러스터로 연동
실제로 kafka 클러스터가 동작하는지는 외부망에서 정상적으로 접근이 되는지 테스트를 해야한다.
이번에는 local machine(맥북)에서 kafka-console-producer와 kafka-console-consumer로 정상 동작하는지 테스트해보도록 한다.
./bin/kafka-topics.sh --create --zookeeper test-broker01:2181,test-broker02:2181,test-broker03:2181/test \
--replication-factor 3 --partitions 1 --topic test이제 console-producer와 console-consumer를 동시에 켜고 topic에 데이터가 정상적으로 처리되는지 확인한다.
./bin/kafka-console-producer.sh --broker-list test-broker01:9092,test-broker02:9092,test-broker03:9092 \
--topic test
> This is a message
> This is another message
./bin/kafka-console-consumer.sh --bootstrap-server test-broker01:9092,test-broker02:9092,test-broker03:9092 \
--topic test --from-beginning
This is a message
This is another messagenGrinder로 부하테스트
테스트 설정
1) Agent : 1개 (nGrinder에서 테스트를 실행하는 물리적/가상 머신)
2) Process : 3개 (Agent 내에서 실행되는 독립적인 프로세스 수)
3) Threads : 33개 (각 프로세스 내에서 실행되는 스레드 수)
4) 총 가상 사용자 수 (Total Users) : Agent×Process×Threads=1×3×33=99
5) 테스트 실행 시간 (Duration) : 15분
문의사항 생성 api (-> 판매자에게 알람전송)
15분동안 총 99개의 가상 사용자가 동시에 문의사항 생성 api를 요청하도록 설정함
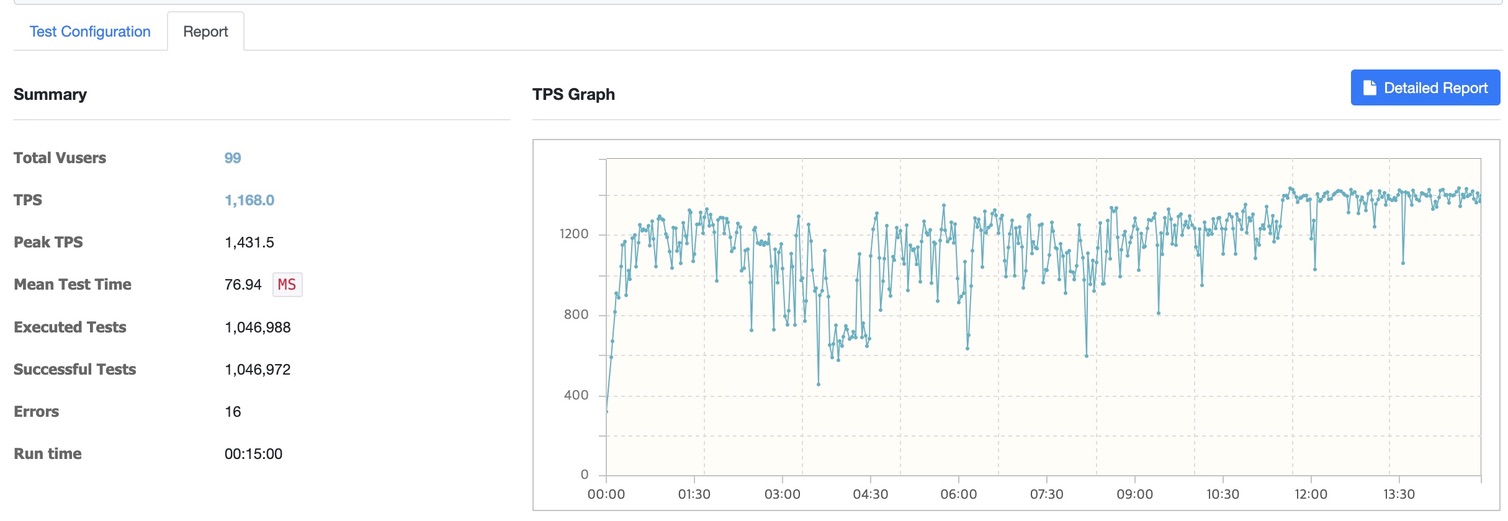
Kafka 미사용
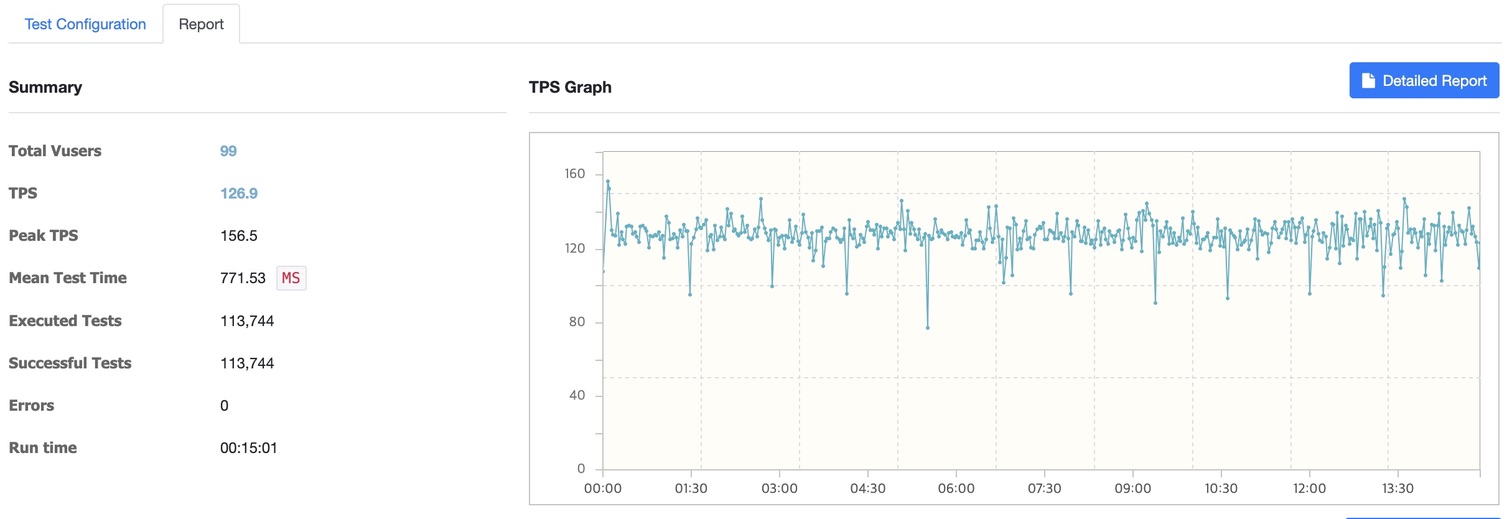
- 총 사용자 (Total Users): 99
- TPS (Transactions Per Second): 126.9
- 최대 TPS (Peak TPS): 156.5
- 평균 테스트 시간 (Mean Test Time): 771.53ms
- 실행된 테스트 수 (Executed Tests): 113,744
- 성공한 테스트 수 (Successful Tests): 113,744
- 오류 (Errors): 0
- 실행 시간 (Run Time): 15분
Kafka 사용
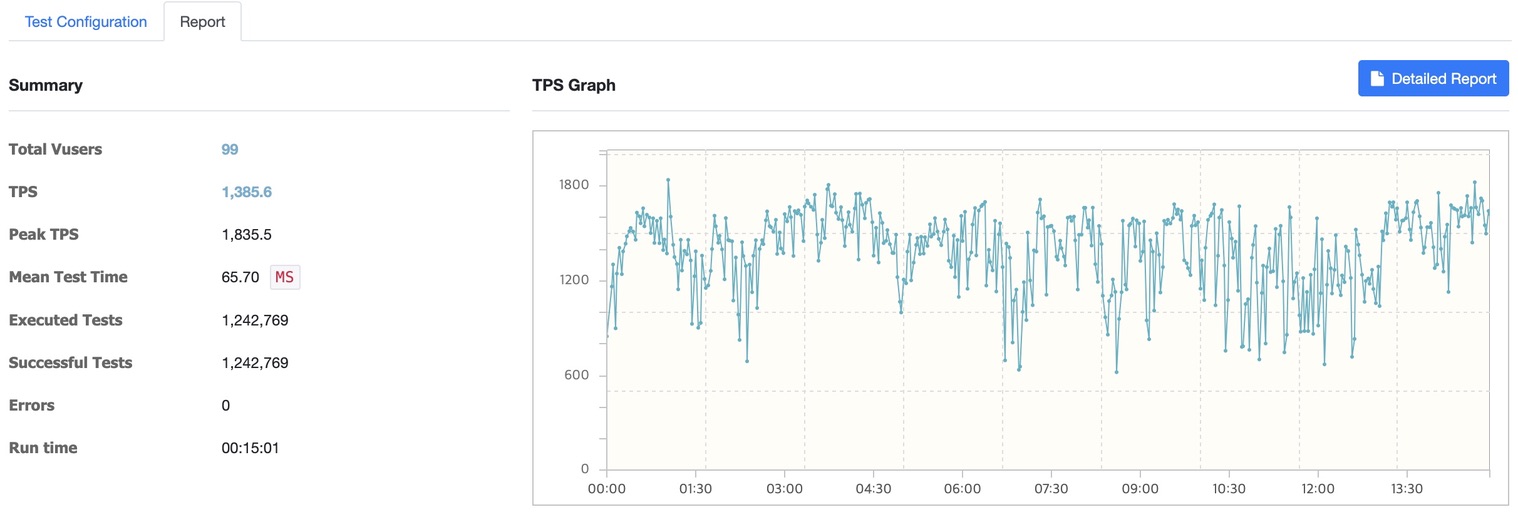
- 총 사용자 (Total Users): 99
- TPS (Transactions Per Second): 1,385.6
- 최대 TPS (Peak TPS): 1,835.5
- 평균 테스트 시간 (Mean Test Time): 65.70ms
- 실행된 테스트 수 (Executed Tests): 1,242,769
- 성공한 테스트 수 (Successful Tests): 1,242,769
- 오류 (Errors): 0
- 실행 시간 (Run Time): 15분
분석
| 항목 | Kafka 미사용 | Kafka 사용 |
|---|---|---|
| 총 사용자 | 99 | 99 |
| 평균 TPS | 126.9 | 1,385.6 |
| 최대 TPS | 156.5 | 1,835.5 |
| 평균 테스트 시간 | 771.53ms | 65.70ms |
| 실행된 테스트 수 | 113,744 | 1,242,769 |
| 성공한 테스트 수 | 113,744 | 1,242,769 |
| 오류 | 0 | 0 |
- 평균 TPS가 1,385.6으로 Kafka 미사용 환경에 비해 약 10배 이상 증가했습니다.
- 평균 테스트 시간이 65.70ms로 매우 짧아졌으며 이는 Kafka가 요청 처리를 비동기적으로 처리하여 성능이 크게 향상되었습니다.
- Kafka를 사용한 환경에서는 대량의 요청을 효율적으로 처리하며 병렬 처리가 잘 이루어지고 있습니다.
결과
Kafka를 사용한 경우 TPS가 약 10배 증가(126 → 1,385)하고 평균 응답 시간이 약 11배 감소(771ms → 65ms)했습니다.
고민한 내용
@Async 활용 비동기 테스트
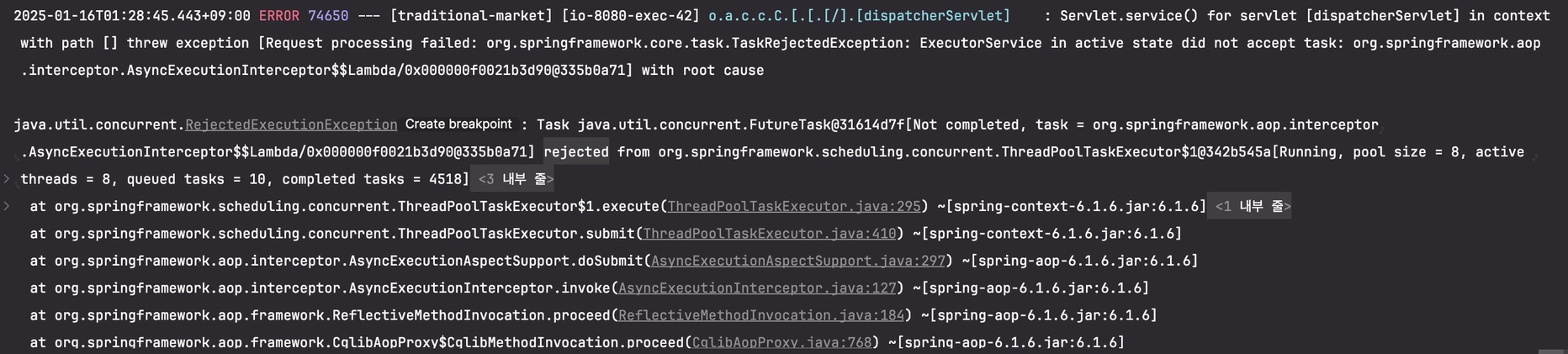
에러 메시지 주요 내용
org.springframework.core.task.TaskRejectedException: ExecutorService in active state did not accept task... java.util.concurrent.RejectedExecutionException: ... rejected from org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor
에러 해석 : 이는 비동기 작업을 처리하는
ThreadPoolTaskExecutor가 과부하 상태에 도달했음
원인 :ThreadPoolTaskExecutor가 설정된 최대 스레드 수와 큐 용량을 초과하여 더 이상 작업을 수용할 수 없는 상태
해결방법 :ThreadPoolTaskExecutor설정 조정
스레드 풀 크기와 큐 용량을 늘릴 수 있지만 CPU 코어 수보다 많은 스레드를 생성하면 컨텍스트 스위칭(Context Switching) 오버헤드가 발생하여 성능이 저하되고 많은 스레드가 동시에 실행되면 I/O 작업에서 리소스 경합이 발생할 가능성이 높아집니다. 또한 큐 용량을 늘리면 큐에 대기 중인 작업은 메모리를 차지하므로 큐 용량이 클수록 메모리 사용량이 증가하고 작업이 큐에 오래 대기하면 시스템 메모리가 부족해질 위험이 있고, 큐에 많은 작업이 쌓이면 작업이 실행되기까지의 대기 시간이 길어져 응답 시간이 지연됩니다. 특히 실시간 처리가 중요한 애플리케이션에서는 큰 문제가 될 수 있습니다.
@Async를 활용한 비동기 처리 방식도 고려하였으나, 이런 이유로 높은 처리량을 감당하기 어렵다고 판단하여 Kafka를 최종 선택하였습니다.
References
- 아파치 카프카 애플리케이션 프로그래밍 with 자바
- 실전 카프카 개발부터 운영까지
