
[ 정규화(Normalization)이란? ]
정규화(Normalization)의 기본 목표는 테이블 간에 중복된 데이타를 허용하지 않는다는 것이다. 중복된 데이터를 허용하지 않음으로써 무결성(Integrity)를 유지할 수 있으며, DB의 저장 용량 역시 줄일 수 있다.
이러한 테이블을 분해하는 정규화 단계가 정의되어 있는데, 여기서 테이블을 어떻게 분해되는지에 따라 정규화 단계가 달라지는데, 3차정규화까지 실무에서 자주 활용한다고 하여 3차까지 알아보았다.
[ 제2 정규화 ]
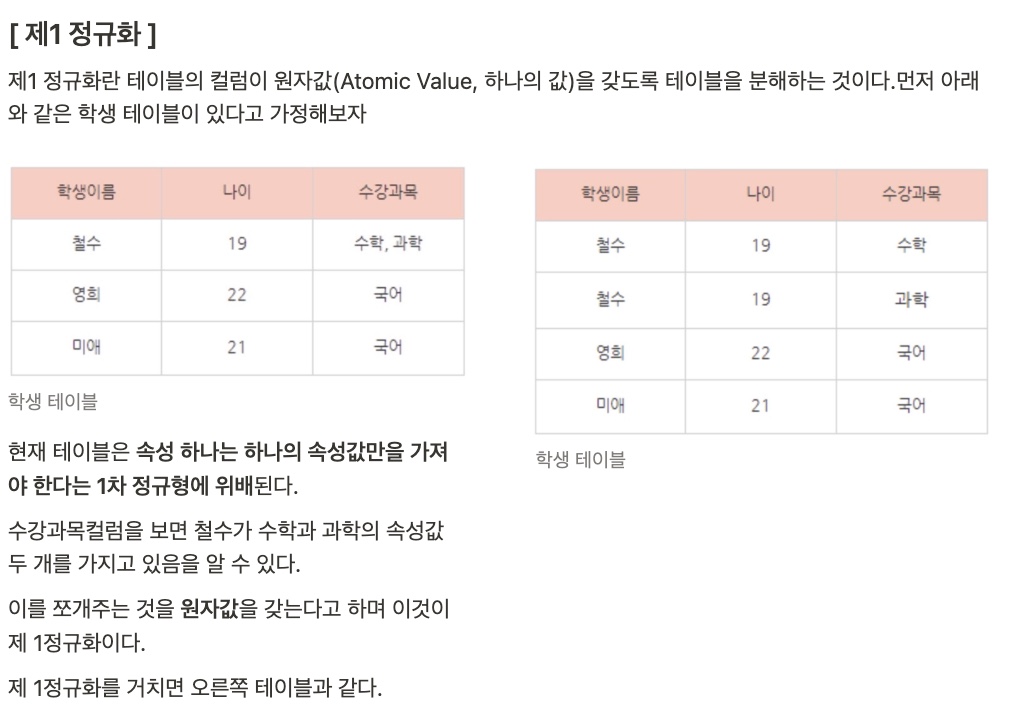
제2 정규화란 제1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해하는 것이다.
완전 함수 종속이라는 것은 기본키의 부분집합이 결정자가 되어서는 안 된다는 것이다.
위 테이블의 기본키는 이름, 과목으로 복합키(이 둘이 합쳐야 한 줄의 ROW로 구분할 수 있다.)
방금 제 1정규화를 거친 테이블을 보면
중복데이터로 인해 학생이름으로 ROW를 구분할 수 없고 나이 또한 ROW를 구분할 수 없다.
학생이름과 수강과목 두 가지를 합친 [ 학생이름, 수강과목 ] 기본키로만 각 ROW를 구분할 수 있다.
이는 다르게 말해 학생이름과 수강과목을 알면 나이를 알 수 있다는 말이 되기도 하는데
여기서 문제가 나이는 학생이름에 종속되어져 있기에 학생이름 하나만 알더라도 나이를 알 수 있다는 것이다. (나이가 두 번 들어가는 것은 불필요!)
이렇게 기본키 중에 특정 컬럼에만 종속된 컬럼이 존재할 경우 2차 정규형에 위배된다.
이를 해결하기 위해 제 2정규화를 실행하며 제 2정규화를 거치면 아래와 같다.

[제3 정규화]
다음으로 제 3정규화는 제 2정규형을 만족하는 상태에서 이행 함수 종속을 제거하는 정규화 과정을 말한다.
아래와 같이 어느 한 통신사의 고객 정보 테이블이 있다고 가정하자.
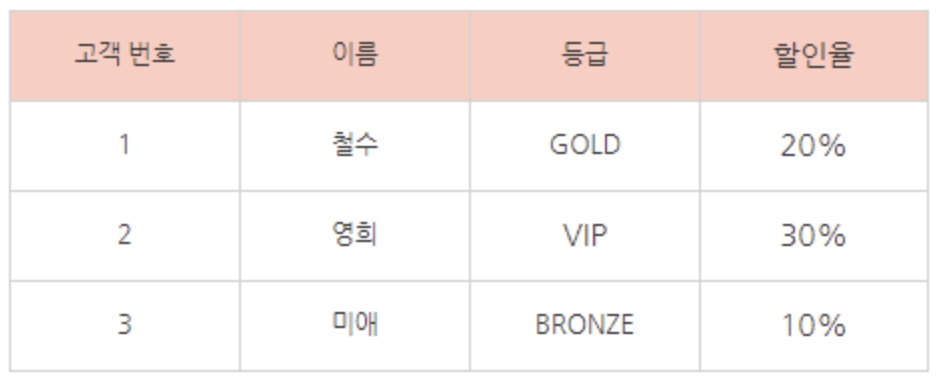
여기서 고객 번호를 알면 각 컬럼의 속성 값들을 찾아낼 수 있다. 그런데 자세히 보면 등급은 고객 번호에 의해 결정되어지고 할인율은 등급에 의해 결정되어진다. 이는 논리적으로 보면 할인율은 고객 번호에 의해 결정되어지는 아이러니한 모습을 나타내는 셈이다.
이 상황처럼 X->Y, Y->Z 일 때 X->Z(고객 번호가 등급에 영향을 주고 등급이 할인율에 영향을 주면서 고객번호가 할인율까지 영향을 준다?) 를 만족해버리면 이행 함수 종속이 발생한다고 한다. 이를 제거하는 것이 제 3정규화. 제 3정규화를 거치면 다음과 같이 테이블을 나타낼 수 있다.

