
만약 데이터베이스에 어떠한 쿼리문을 날렸다고 가정해봅시다. 이 때 이 결과를 신뢰할 수 있을까요? 아마 이 질문에 대해 당연히 신뢰할 수 있는데 왜 그런 질문을 하는지 생각할 수도 있을 것 같습니다. 저 역시 그랬습니다. 그렇다면 어떻게 우리는 쿼리문의 결과를 신뢰하고 그 결과값을 쓰는 것일까요?
트랜잭션이란?
트랜잭션은 짧게 말하자면 절대로 깨져서는 안 되는 일련의 과정입니다. 이에 대한 예로 가장 많이 나오는 것이 송금입니다.
A가 B에게 10000원을 송금한다고 가정해보겠습니다.
1. A의 잔액이 10000원보다 많은지 확인한다.
2. 1이 참이라면 B에게 10000원을 송금한다. 이 과정에서 A의 잔액을 -10000한다.
3. B의 잔액을 +10000한다.
만약 이 과정중 하나라도 오류가 생긴다면 아예 1번전의 단계로 돌아가야합니다. 이를 Rollback이라고 합니다. 또한 3까지 다 완료가 되면 이를 데이터베이스에 반영하게 되는데 이 과정을 commit이라고 합니다.
그렇다면 우리는 이런 트랜잭션이 어떤 특성이 있길래 데이터베이스를 신뢰하고 쓰는 것일까요?
트랜잭션의 특성
트랜잭션의 주요한 4가지 특성이 있습니다. 바로 ACID입니다.
Atomicity 원자성
위의 송금예시처럼 모두가 정상적으로 실행되거나 모두 취소되어야하는 성질입니다.
Consistency 일관성
시스템이 가지고 있는 고정요소는 트랜잭션 수행 전과 수행 완료후의 상태가 같아야한다는 것입니다.
즉, 트랜잭션이 일어난 이후의 데이터베이스는 데이터베이스의 제약이나 규칙을 만족해야한다는 것입니다.
예를 들어 Member테이블의 name은 NULL이면 안 된다는 제약이 있다고 한다면 이를 만족해야한다는 것입니다.
Isolation 고립성, 격리성
동시에 실행되는 트랜잭션들이 서로 영향을 미치지 않아야한다는 것입니다.
예를 들어 A도 B에게 송금하기를 원하고, C도 B에게 동시에 송금하기를 원한다면 이는 각각 송금한 결과와 같아야한다는 것입니다.
Durability 지속성
하나의 트랜잭션이 성공적으로 수행되었다면 해당 트랙잭션에 대한 로그가 영원히 남아야한다는 것입니다.
이렇게 데이터베이스의 특성을 읽고 나니 문득 이런 생각이 들었습니다. 대규모서비스에서는 DB에 접근을 굉장히 많이 할텐데 이를 다 순차적으로 진행하는 것일까요? 🤔 그렇다면 너무 오래 걸리지않을까요?
그래서 알아야하는 것이 고립화 수준입니다.
데이터베이스의 고립화 수준
Read Uncommitted
한 트랜잭션에서 아직 커밋되지않은 데이터를 다른 트랜잭션이 읽는 것을 허용합니다. 그러나 갱신중인 데이터에 대한 연산은 불가합니다.
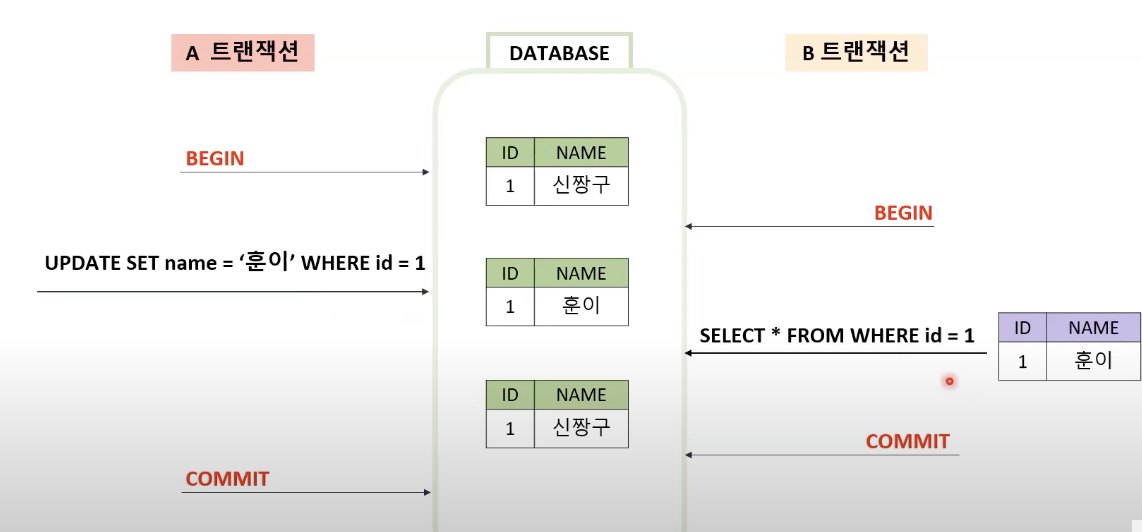
A의 트랜잭션이 commit 되기전에 B 트랜잭션에서 아직 커밋되지않은 데이터를 읽을 수 있습니다.
이 경우 Dirty Read 라는 문제가 발생하게 됩니다.
만약 A 트랜잭션에 오류가 생겨서 Rollback을 한다면 어떻게 될까요?
B트랜잭션은 커밋 전에 이 데이터를 가져갔으니 잘못된 데이터를 가져가게 됩니다. 이를 Dirty Read라고 합니다.
Read Committed
한 트랜잭션에서 연산을 수행할 때 연산이 완료될 때까지 연산 대상 데이터에 대한 읽기를 제한합니다.
연산이 완료된 데이터에 한해서만 다른 트랜잭션이 읽는 것을 허용합니다.
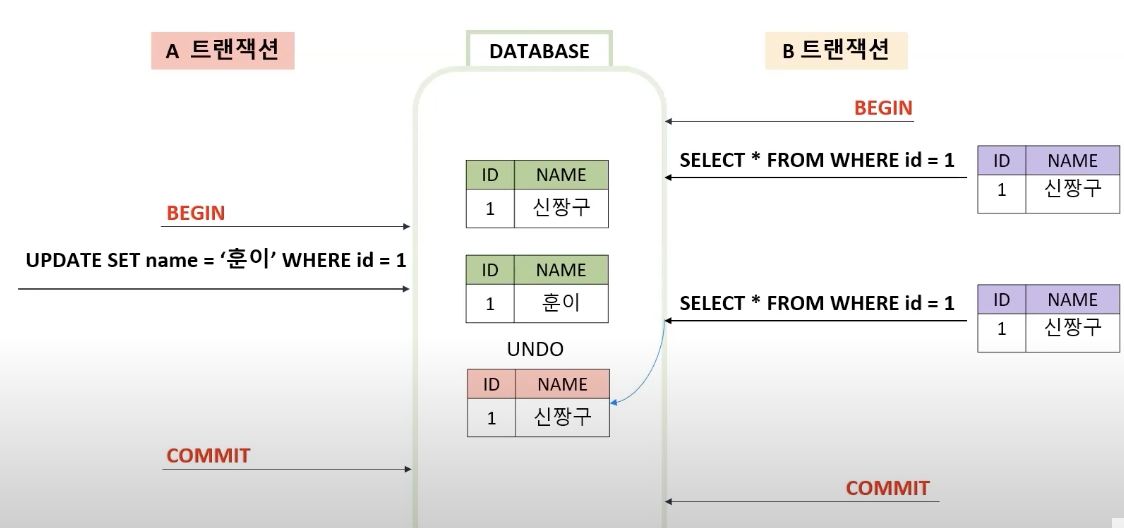
A에서 1번의 name을 훈이로 바꿨지만 아직 commit되기 전이므로 신짱구값을 가져갑니다.
이 때 이 신짱구 값은 UNDO 영역에 저장된 값입니다.
이 경우 Non-Repeatable Read라는 문제가 발생하게 됩니다.
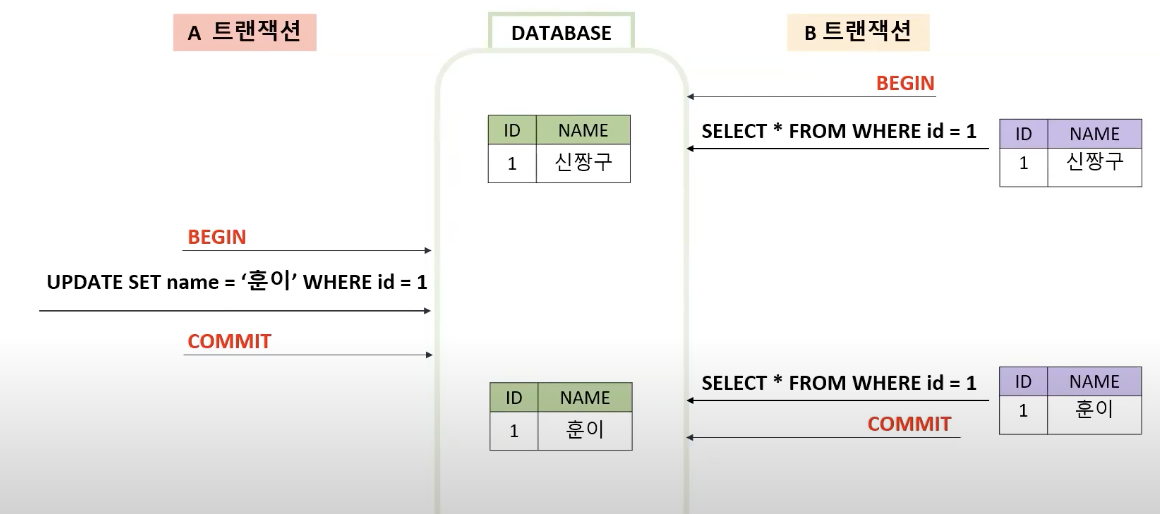
B가 처음에 id가 1인 값을 조회했을 때는 "훈이"였으나 다시 조회하면 "신짱구"가 되게 됩니다. 이 경우 하나의 트랜잭션내에서 동일한 SELECT 쿼리를 실행했을 때 항상 같은 결과를 보장해야 한다는 "REPEATABLE READ" 정합성에 어긋나게 됩니다.
Repeatable Read
Repeatable Read는 트랜잭션마다 고유한 트랜잭션 번호(순차적으로 증가)를 갖게 되고, 언두 영역에 백업된 모든 레코드는 변경을 발생시킨 트랜잭션 번호를 갖고 있습니다.

A의 커밋이 끝나고 나서도 B는 본인의 트랜잭션 번호보다 작은 경우의 값만 가져올 수 있습니다. 그래서 언두 영역의 값을 갖고 오게 됩니다.
그렇지만 이 경우에도 문제가 발생하게 됩니다. 바로 PHANTOM READ입니다.

SELECT .. FOR UPDATE 쿼리는 SELECT 하는 레코드에 쓰기 잠금을 걸어야하지만 언두 레코드에는 잠금을 걸 수 없습니다. 그래서 위의 쿼리는 언두 영역의 변경 전 데이터를 가져오는 것이 아니라 현재 레코드 값을 가져 오게 됩니다.
그래서 A 커밋 전에 실행한 쿼리문의 결과와 A 커밋 실행 후의 쿼리문의 결과가 다르게 됩니다. 위에서는 id가 3인 맹구가 팬텀 행이 되게 됩니다.
Serializable Read
가장 단순한 격리수준이며 가장 엄격합니다. 선행 트랜잭션이 특정 데이터 영역을 순차적으로 읽을 때, 해당 데이터 영역 전체에 대한 접근을 제어합니다.
이 경우 PHANTOM READ 문제는 발생하지 않지만, 동시 처리 성능이 매우 떨어지게 됩니다.
출처
[MySQL] - 트랜잭션의 격리 수준(Isolation level)
트랜잭션(Transaction) 격리 수준 - 박혜빈 | 백엔드 데브코스 2기 | 백둥이Deview 220621
