
Feature Engineering
정의: EDA를 하면서 주요한 Feature를 선택해 학습하는데 그것만으로 충분하지 않을때 도메인 지식과 창의성을 바탕으로 Feature를 재조합하여 새로운 Featrue를 만드는 것
7가지 Feature Engineering 기술
1. imputation
-missing value에서 row데이터 날리기
-Numerical: 숫자 컬럼 Default 값으로 채우기
-categorical: 빈번히 나타나는 값으로 채우기
-Random: 랜덤하게 채우기
2. 예외값 처리(Handling Outliers)
-표준편차에서 예외적으로 나타내는 값 삭제
-특정 Percent외에 있는 값들을 삭제(상/하위 5%)
3. Bin으로 묶기
-하나의 범주로 묶기
4. 로그변형
-정규성을 높여서 분석시 정확한 값을 얻기 위함(복잡한 계산을 심플하게)
-왜도(Skewness)와 첨도(Kurtosis)
5. one hot encoding
-데이터를 수많은 0과 한개의 1의 값으로 데이터를 구별하는 인코딩
-머신러닝 알고리즘은 문자열 값을 입력 값으로 허락하지 않아서 모든 문자열 값을 숫자형으로 인코딩
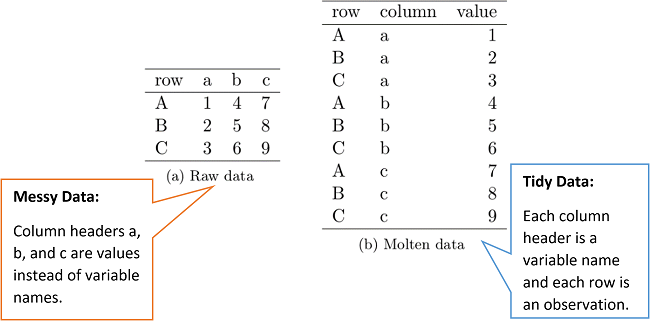
6. 그룹 연산(Grouping Operation)
-Tidy data
이미지 출처:https://www.ksk-anl.com/blog/hadley-wickhams-tidy-data-in-rapidminer-part-1/
-Pivot
7. Scailing
-표준화: 서로 다른 범위의 변수들을 평균이 0이고 분산이 1인 가우시안 정규 분포를 가진 값으로 변환하는 작업
-정규화: 서로 다른 범위의 변수들의 크기를 통일하기 위해 이를 변환하는 작업
Feature Engineering 기술 글 출처: https://magoker.tistory.com/118
String
문자열 다루기
1. 문자를 숫자로 바꾸기 위해 숫자가 아닌 부분(,) 제거
2. 숫자로 형변환#1. ,빼고 공백으로 채워서 replace 사용해서 바꾸기 data.replace(',', '') #apply 함수 사용해서 df.appy(pd.to_numeric) #한개의 컬럼에 적용하고 싶을때 df['col'] = pd.to_numeric(df['col']) # 3.함수로 만들어서 def toInt(string): return int(string.replace(',',''))float에서 int로는 언제바꿀까? 수학적 수치를 계산할때
추가
- 결측치를 표현하는 NaN은 프로그래밍 상, 어떤 데이터 type을 가지고 있는가?
NaN은 Not a Number의 줄임말로 pandas에서 결측치를 표현하는 방법입니다. NaN은 프로그래밍 상 float라는 type을 갖습니다.
List Comprehension
[f(x) for x in nums]
바다코끼리 연산자
- python 3.8부터 추가됨
- 대입연산자+표현식을 만들어낸다
print(a = 10)
# 오류뜸, 파이썬 이념이 한줄의 한의미만 담게
#그런데 바다코끼리 연산자를 사용하면 오류없이 출력됨
print(a := 10) # 10
# 반복문에서 사용
while s := input("입력: "):
print("출력: " +s)
print("프로그램 종료")
# 메모화
'''
기존
변수 = 값
메모[키] = 변수
return 변수
바다코끼리 연산자
return 메모[키] := 값
'''list comprehension with Walrus operator(바다코끼리 연산자로 리스트 컴프리헨션 구현)
nums = [1, 2, 3, 4, 5, 6]
[fibo(x) for x in nums]
# [1, 1, 2, 3, 5, 8]
[y for x in nums if (y := fibo(x)) % 2 == 0]
# [2, 8]
안녕하세요. 기억보다 기록을 믿는 레나입니다!