
벡터 변환 Vector Transformation
- 선형 변환은 임의의 두 벡터를 더하거나 혹은 스칼라 값을 곱하는 것을 의미한다
고유벡터 Eigenvector
- 변환에 의해 영향을 받지 않는 벡터인데 이말은 즉슨, 벡터를 변환시키려고 특정 매트릭스에 T를 곱했을 때 그 결과가 벡터의 방향이 안변하고 스칼라배 한 값이 나오면 그 벡터는 T의 고유 벡터가 된다
- (참고)벡터 연산에서 곱셈은 벡터의 크기를 변화시키고 덧셈은 벡터의 방향을 변화 시킨다
에이겐 벨류 관련 논문
https://arxiv.org/pdf/2101.02928.pdf
고유값 Eigenvalue
- 고유 벡터는 매트릭스를 곱했을 때 길이만 변화하는데 길이가 변한 스칼라 값을 고유값이라고 한다
주성분 분석 PCA
- Principal Component Analysis, 주성분 분석이라고 한다
- 데이터의 분산을 보존하면서 서로 직교하는 새 기저(축)를 찾아서 고차원 공간의 표본들을 선형 연관성이 없는 저차원 공간으로 변환하는 기법이다
주성분 분석에 사용하는 변수 추출(Feature extraction)
- 기존 변수를 조합해서 새로운 변수를 만드는 기법으로 일부 중요한 변수만 빼내는 변수선택과는 대비되는 개념이다
- 변수 추출 1. 기존 변수 가운데 일부만 활용, 2. 기존 변수 모두 사용하는 방식이 있는데 주성분 분석(PCA)는 기존 변수를 모두 사용한다
그럼 PCA를 구하면 어디에 사용하나요?
회귀 분석에서 설명변수의 개수를 결정하거나
인자를 구하는 방법으로 인자 분석의 전작업으로 사용하거나
클러스터링 할때 인력변수로 사용하기위해 pca를 통해 구함
논문을 통해 활용되는 방법 확인하기
논문 제목: Deep Learning for Automatic Quality Grading of Mangoes: Methods and Insights
논문 출처: https://arxiv.org/pdf/2011.11378.pdf
딥러닝 모델을 통해 망고의 품질 점수를 자동으로 매기는 것에 대한 논문인데, 여기서 PCA 내용만 보려고한다.

우선, 망고의 품질은 3종류로 나눠진다
딥러닝으로 위의 문제를 풀때는 정답 라벨이 3개가 있기때문에 모델이 Grade A, Grade B, Grade C를 구분해준다.
- 망고의 품질을 3가지로 분류하기위해 해당 논문에서 쓴 모델은 Mask RCNN, AlexNet, VGGs, ResNet등이 있다
- 사전학습된 ImageNet 가중치를 사용했다
이 논문에서는 PCA를 설명가능한 인사이트를 제공하기위해서 썻다고 한다
그 이유는 딥러닝 모델이 어떻게 결과 값을 낸건지 뜯어볼 수 없기 때문에 블랙박스 모델이라고 부르는데 이 논문에서는 그 블랙박스 모델이 낸 결과를 설명해주기위해서 PCA을 쓴것이다.

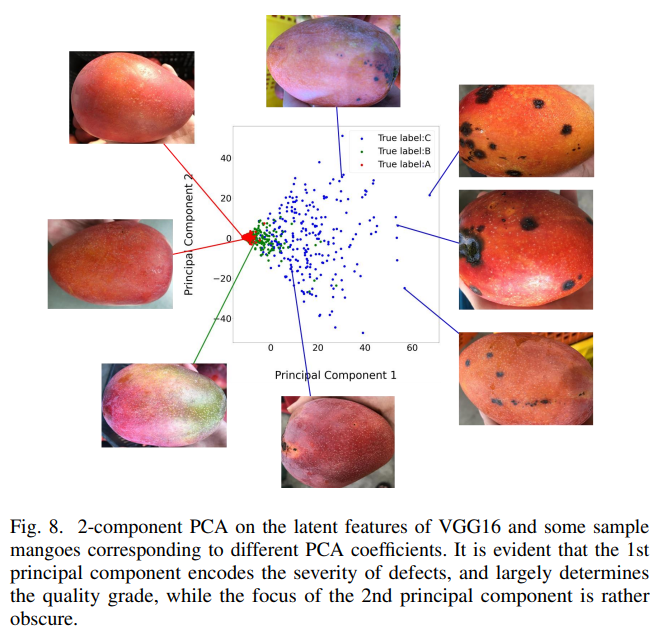
위의 사진을 보면 정답 품질과 vgg16 모델이 맞춘 품질이 다른 것을 알 수있다.
이는, 모델이 학습될 때 검은 점이 있는 망고의 품질이 낮아지는 쪽으로 학습이 되었기 때문이다.
-
망고 이미지들를 모델에 넣고 나온 값(고차원의 값임) 어떤 기준으로 망고의 품질을 구별해주는 결과를 냈는지 확인하기 위해서 PCA 방법을 사용하는데 즉, 모델을 통과한 많은 망고이미지의 고차원 값들을 에이겐디컴포지션을 사용해서 저차원으로 줄여준다(기존 벡터 값을 최대 편차를 가지는 에이겐 벡터로 바꿔는 거다)
여기 논문에서는 2차원으로 줄여서 그래프로 보여줬다(princial component 1, 2)
-
그럼 주성분=principal components 즉, 주성분의 coefficients 값이 vgg16 모델의 눈으로 볼때 어떤식으로 구별해왔는지를 알려주는 특성이 뭔지 알수있게 되는 것이다
-
위의 이미지를 보면 첫번째 주성분은 대부분의 데이터와 구별되는데 grade C의 샘플이 가장 높은 coeffients를 가지고 grade B, grade A순으로 따라온다
-
오른쪽에 있는 망고 사진을 보면 검은 점이 있는데 이 검은 점의 여부가 모델에서 품질을 구분하는데 가장 영향을 미친다는 것을 알 수 있다
-
또한, grade A의 샘플(그래프에선 빨간 점들)은 상당히 모여있고 B, C 순으로 점들이 퍼져있는 것을 알 수 있다
-
이 현상은 자연에서 좋은 품질의 망고는 비슷하게 생겼고 저품질 망고는 다르게 생겼다는 것을 설명해준다
