
주요 라이브러리
category_encoders
matplotlib
numpy
pandas
pandas-profiling
scikit-learn
scipy.stats
모델선택
- 우리 문제를 풀기위해 어떤 학습 모델을 사용해야할 것인지?
- 어떤 하이퍼파라미터를 사용할 것인지?
** 교차 검증은 시계열(time series) 데이터에는 적합하지 않음
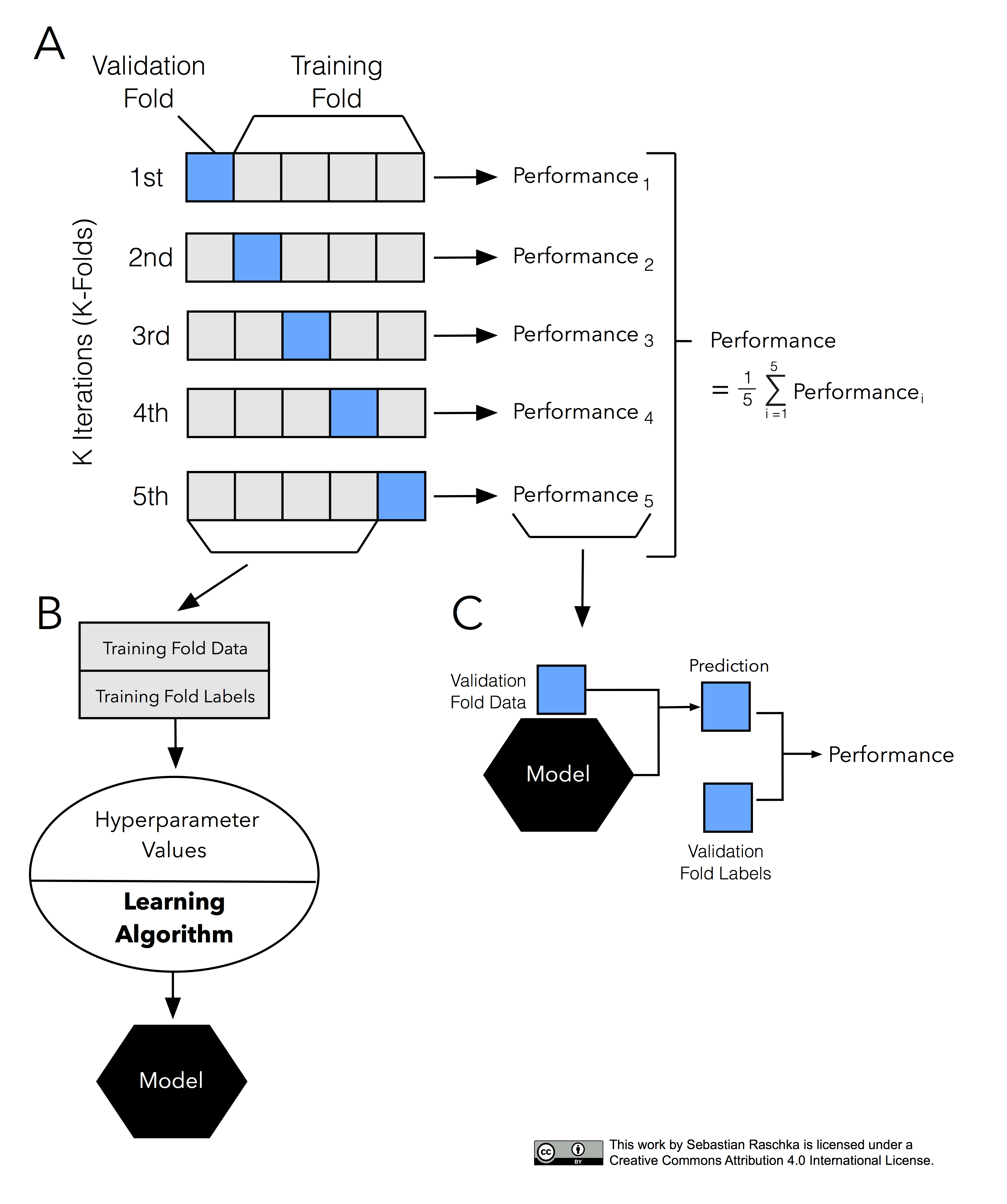
[그림 설명]
A
- 같은 데이터를 5개로 나누고 그걸 1st ~5th로 나눈다.
B
- 라벨을 붙인 4개의 트레인 셋에 최적의 하이퍼 파라미터를 적용해 모델을 만든다.
C
-
모델에 벨리데이션 데이터를 붙인 후 예측하고 베일리 폴드 라벨을 붙여서 퍼포먼스를 낸다.
-
퍼포먼스를 낸 후 시그마로 평균값을 낸다.
교차검증(Cross- validation)
hold-out 교차검증
- 훈련/검증/테스트 세트로 나누어 학습을 진행
- 문제점1) 훈련세트 크기가 모델학습에 충문하지 않을 경우 문제가 될 수 있음
- 문제점2) 검증세트 크기가 충분히 크지 않다면 예측 성능에 대한 추청이 부정확할 것
K-fold Cross Validation
- 보통 회귀 모델에 사용, 데이터가 독립적이고 동일한 분포를 가진 경우에 사용
- cross_val_score 함수에서는 cv로 폴드이 수를 조정할 수 있음
- 총 데이터 갯수가 적은 데이터 셋에 대하여 정확도를 향상시킬수 있음
- 데이터 수가 적은데 검증과 테스트 데이터를 더 뺏기면 underfitting등 성능이 미달되는 모델이 학습됨
- K개의 집합에서 k-1개의 부분집합을 훈련에 사용하고 나머지 부분집합을 테스트 데이터로 검증함
[과정]
1. traing/test set으로 나눈다.
2. trainng을 K개의 fold로 나눈다.
3. 한개의 fold에 있는 데이터를 다시 K개로 쪼갠다음, K-1개는 Training Data, 마지막 한개는 Validation Data set으로 지정
4. 모델을 생성하고 예측을 진행하며 이에대한 에러 값을 추출
5. 다음 fold에서는 validation셋을 바꿔서 지정하고, 이전 fold에서 validation 역할을 했던 Set은 다시 Training set으로 활용
6. 이를 K번 반복
7. 각각의 fold의 시도에서 기록된 에러를 바탕(에러들이 평균)으로 최적의 모델/조건을 찾음
8. 해당 모델(조건)을 바탕으로 전체 training set의 학습을 진행
9. 해당 모델을 처음에 분할했던 test set을 활용하여 평가
**단점: 시간 소요가 큼
Straitifed K-fold Cross Validation
하이퍼파라미터 튜닝
- 최적화: 훈련 데이터로 더 좋은 성능을 얻기 위해 모델을 조정하는 과정
- 일반화: 학습된 모델이 처음 본 데이터에서 얼마나 좋은 성능을 내는지
- GridSearchCV: 검증하고 싶은 하이퍼파라미터들의 수치를 정해주고 그 조합을 모두 검증
- RandomizedSearchCV: 검증하려는 하이퍼파라미터들의 값 범위를 지정해주면 무작위로 값을 지정해 그 조합을 모두 검증
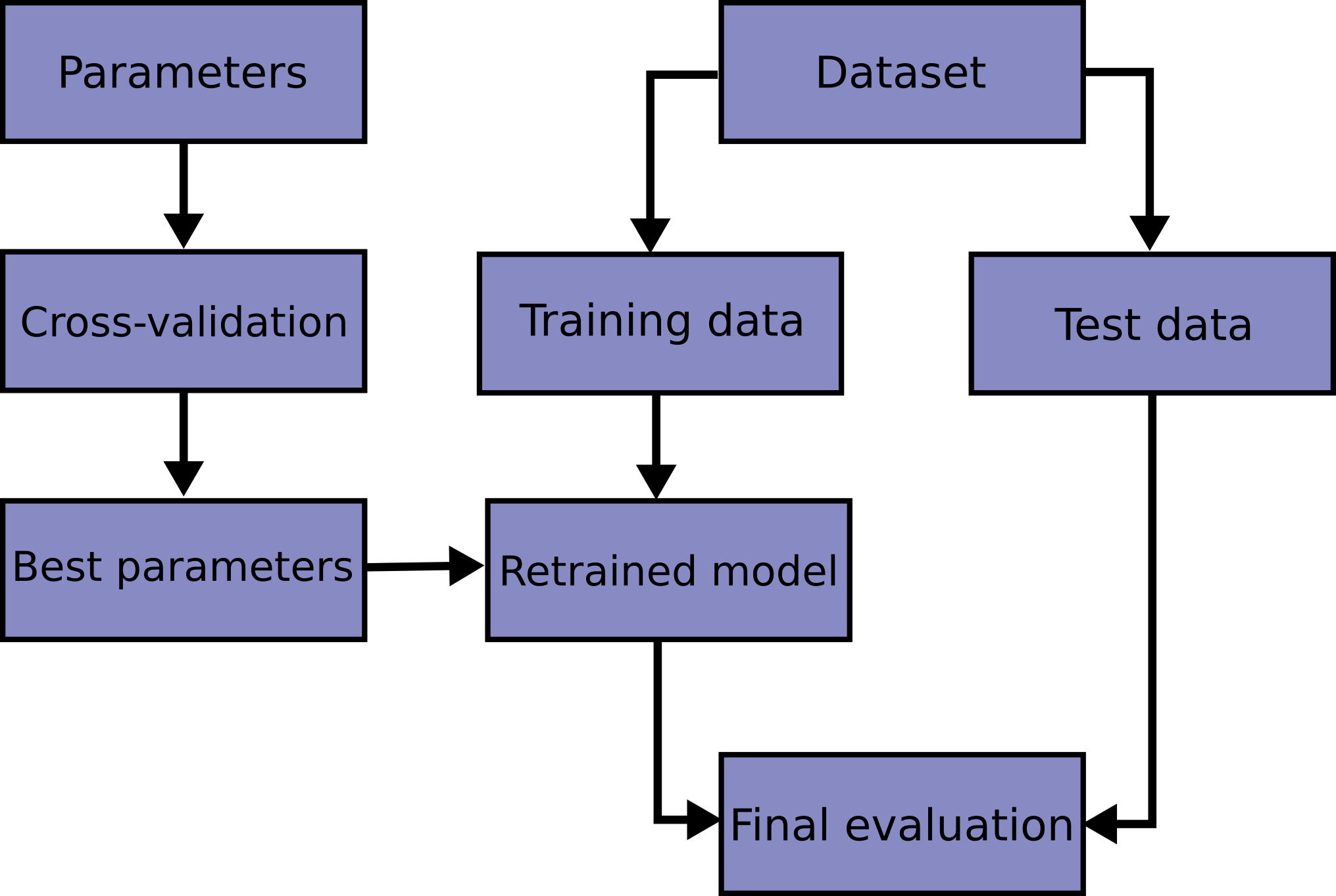
RandomizdsearchCV에서 bestestimator
- bestestimator는 cv가 끝난 후 찾은 best parameter를 사용해 모든 학습데이터를 가지고 다시 학습한 상태
검증곡선
- 훈련/검증 데이터에 대해
X축: 스코어
y축: 하이퍼파라미터로 그린 그래프이다
스코어에 - 를 넣는 이유
-
cross validation score는 숫자가 큰것을 좋게 보는데 mae는 숫자가 클수록 좋지 않은 것이기 때문에 -mae를 붙여줘야한다.
-
그렇다면 R2에는 -를 붙여야할까?
숫자가 1에 가까울수록 좋은거니까 -를 붙여줄 필요가 없음
