이번 포스팅에서는 의사결정나무의 과적합 문제를 해결하기 위한 방법으로 앙상블(Ensemble) 알고리즘을 설명하고, 그 종류를 알아보도록 하자.
앙상블 (Ensemble)
앙상블 (Ensemble)은 통일, 조화를 뜻하는 프랑스어다. 주로 음악에서 여러 악기에 협주를 뜻하는 말로 사용된다. 많은 수의 작은 악기소리가 조화를 이루어 더욱 더 웅장하고 아름다운 소리를 만들어낸다. 물론 그래서는 안되겠지만, 한 명의 아주 작은 실수는 다른 소리에 묻히기도 한다.
기계학습에서의 앙상블도 이와 비슷하다. 여러 개의 weak learner들이 모여 투표(voting)를 통해 더욱 더 강력한 strong learner를 구성한다. 많은 모델이 있기 때문에, 한 모델에서 예측을 엇나가게 하더라도, 어느정도 보정이 된다. 즉, 보다 일반화된(generalized) 모델이 완성된다.
단일 모델로는 Decision tree, SVM, Deep learning 등 모든 종류의 학습 모델이 사용될 수 있다.
Voting의 종류
최종 모델의 예측 값을 결정짓는 Voting은 크게 하드 보팅 (Hard voting)과 소프트 보팅 (Soft voting)으로 나눌 수 있다.
하드 보팅 (Hard voting)
하드 보팅은 각 weak learner들의 예측 결과값을 바탕으로 다수결 투표하는 방식이다.
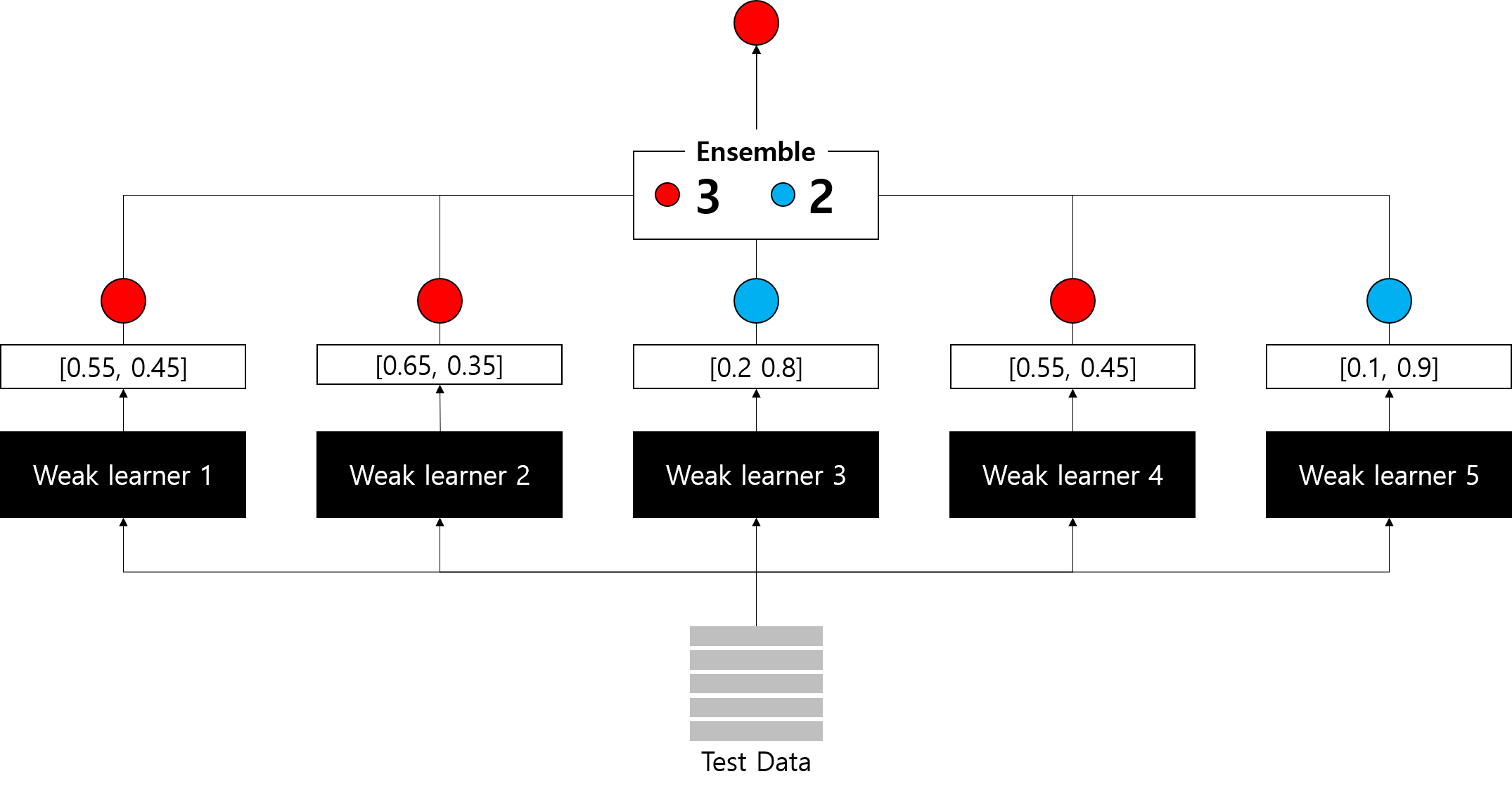
빨간공인지 파란공인지 예측하는 Binary classification 문제에서 동일한 데이터에 대해 각 분류기는 클래스별 예측 확률을 제시한다. 이 확률값에 따라 최종 예측값이 계산되는데, 하드 보팅은 이 예측값의 다수결 투표로 예측값을 결정한다.
따라서 다섯 개 분류기 중 빨간 공으로 예측한 분류기가 3개이니, 이 샘플에 대한 최종 예측값은 빨간 공이 된다.
소프트 보팅 (Soft voting)
반면 소프트 보팅은 weak learner들의 예측 확률값의 평균 또는 가중치 합을 사용한다.
- 평균(average)

weak learner 개별의 예측값은 중요하지 않다. 예측 확률값은 단순 평균내어 확률이 더 높은 클래스를 최종 예측값으로 결정한다.
동일한 예시에서 빨간 공으로 예측한 세 개 분류기 (1,2,4)의 클래스별 예측 확률은 크게 차이가 나지 않는다. 반면, 파란 공으로 예측한 두 개 분류기 (3,5)는 높은 확률로 파란 공을 예측했다. 그 결과, 최종 예측값은 파란 공이 된다.
- 가중치 합 (weighted sum)

만약 어떠한 이유 (단일 모델에 사용되는 feature engineering 방법 등)로 weak learner들에 대한 신뢰도가 다를 경우, 가중치를 부여하여 확률값의 평균이 아닌 가중치 합으로 사용할 수도 있다.
동일한 예시에서 각 분류기의 예측 확률 값에 상이한 가중치를 부여하였기에, 최종 예측값이 빨간 공이 되는 것을 확인할 수 있다.
가중치는 임의로 부여할 수도 있고, 뒤에서 다시 언급할 스태킹(stacking) 기법을 사용할 수도 있다.
앙상블의 종류
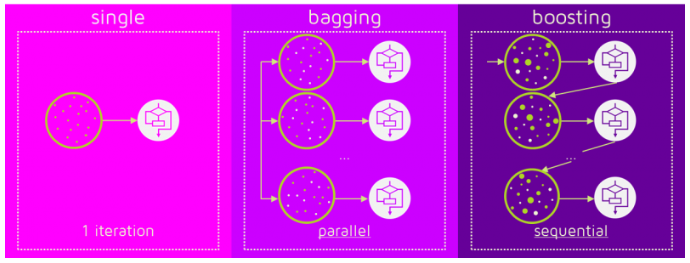
앙상블 알고리즘은 학습 방식에 따라 크게 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking)으로 나눌 수 있다. 본 포스팅에서는 개념만 간단히 정리하고, 추후 포스팅을 통해 예시를 추가로 정리하도록 하자.
배깅 (Bagging)
배깅 (Bagging)은 Bootstrap Aggregating의 약자이다. 이름에서 알 수 있다시피 부트스트랩(Bootstrap)을 이용한다.
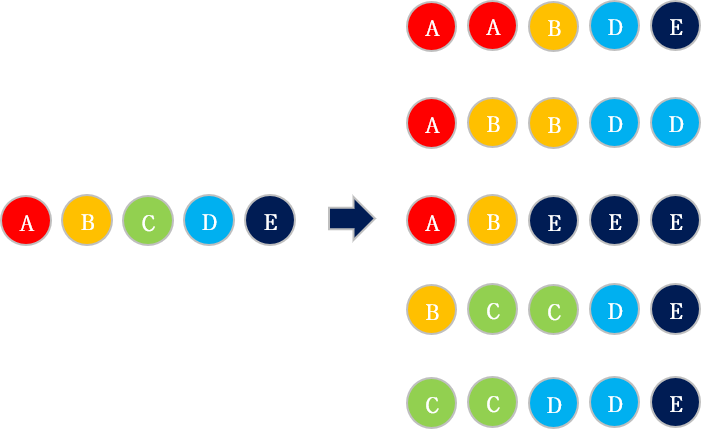
부트스트랩이란 주어진 데이터셋에서 random sampling하여 새로운 데이터셋을 만들어내는 것을 의미한다. 부트스트랩을 통해 만들어진 여러 데이터셋을 바탕으로 weak learner를 훈련시킨 뒤, 결과를 voting한다.
대표적인 예시로 Random Forest가있다.
부스팅 (Boosting)
부스팅 (Boosting)은 반복적으로 모델을 업데이트해나간다. 이 때 이전 iteration의 결과에 따라 데이터셋 샘플에 대한 가중치를 부여한다. 결과적으로, 반복할 때마다 각 샘플의 중요도에 따라 다른 분류기가 만들어진다. 최종적으로는 모든 iteration에서 생성된 모델의 결과를 voting한다.
아래는 Boosting 과정을 대략적으로 나타낸 그림이다.
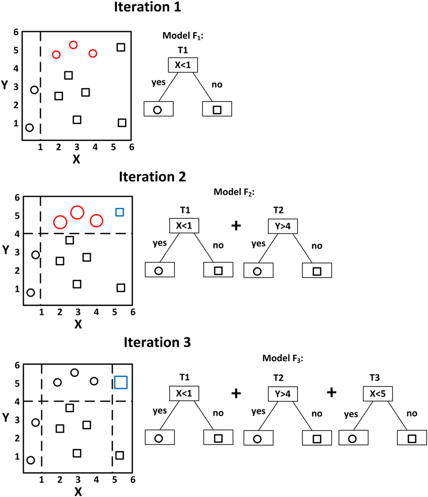
iteration 1에서 빨간 원은 잘못 분류된 샘플이다. 이 샘플에 대한 가중치를 높여 분류기를 다시 만든다
iteration 2에서 iteration 1의 분류기와 새로운 분류기를 함께 사용하여 분류한다. 그 결과 파란 사각형이 잘못 분류되었다. 이 샘플에 대한 가중치를 높여 분류기를 다시 만든다
동일한 방식으로 반복을 진행한 뒤, 만들어진 분류기들을 모두 결합하여 최종 모델을 만들어낸다.
Boosting은 다시 Adaptive Boosting (AdaBoost)와 Gradient Boosting Model (GBM) 계열로 나눌 수 있다.
-
AdaBoost
-
Gradient Boosting
정확도와 속도를 개선한 최근 부스팅 알고리즘들은 Kaggle 등 데이터 분석 대회에서 많이 사용되고 있다.
-
XGBoost
-
LightGBM
-
CatBoost
-
NGBoost
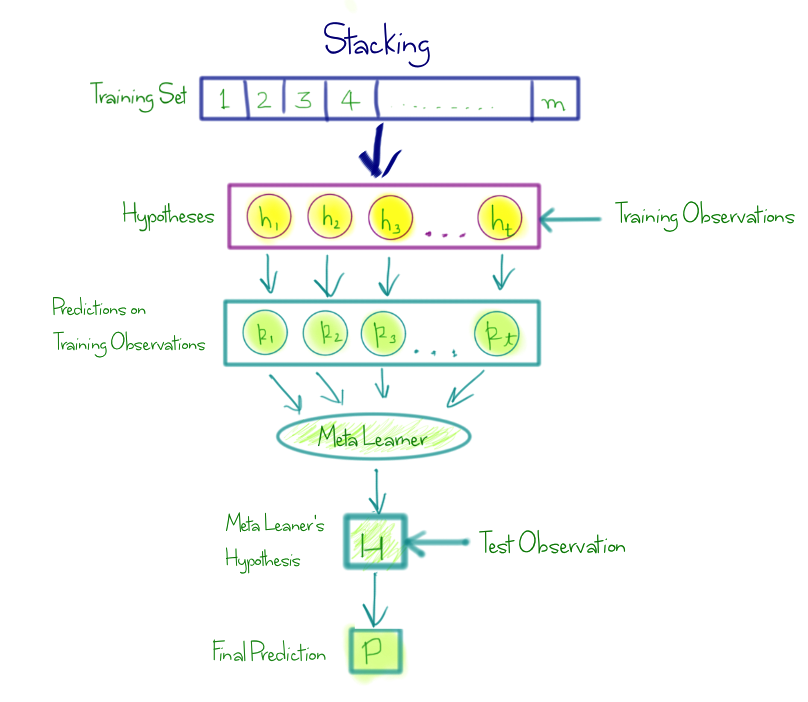
스태킹 (Stacking)
개인적으로 스태킹은 이 곳 보다는 보팅의 종류에 언급하는게 더 어울리는 것 같지만, 대부분 배깅, 부스팅과 함께 비교하기에 넣었다.스태킹은 weak learner들의 예측 결과를 바탕으로 meta learner로 학습시켜 최종 예측값을 결정하는 것을 말한다. meta learner 또한 학습이 필요하며, 이 때 사용되는 데이터는 training data에 대한 weak learner들의 예측 확률값의 모음이다. 과적합 방지를 위해 주로 k-fold cross validation을 이용한다.
그림으로 설명하기는 조금 애매하다. 그나마 아래 그림이 스태킹을 잘 나타내준다.
출처
https://tyami.github.io/machine%20learning/ensemble-1-basics/
