본 포스팅에서는 부스팅 기법 중 가장 기본이 되는 AdaBoost에 대해 알아보자. 부스팅에 대해 잘 모른다면 앙상블 (Ensemble) 이란 포스팅을 참고하는게 좋다
AdaBoost란
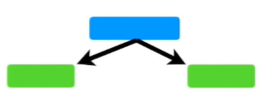
먼저, 아래와 같이 노드 하나에 리프(leaf)를 지닌 트리를 stump라고 한다.
AdaBoost는 아래와 같이 여러 개의 stump로 구성되어있다. 이를 Forest of stumps라고 부른다.
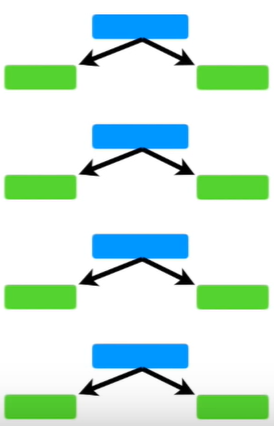
하지만, 트리와 다르게 stump는 정확한 분류를 하지 못한다. 여러 질문을 통해 데이터를 분류하는 트리와는 다르게, stump는 단 하나의 질문으로 데이터를 분류해야하기 때문이다. 따라서 stump는 약한 학습기 (weak learner)이다.
랜덤 포레스트(Random Forest)는 여러 개의 트리의 결과를 합산해서 최종 결과를 낸다. 다수결의 원칙을 통해 말이다. 최종 분류를 하는데 있어 각각의 트리는 동등한 가중치를 가지고 있다.
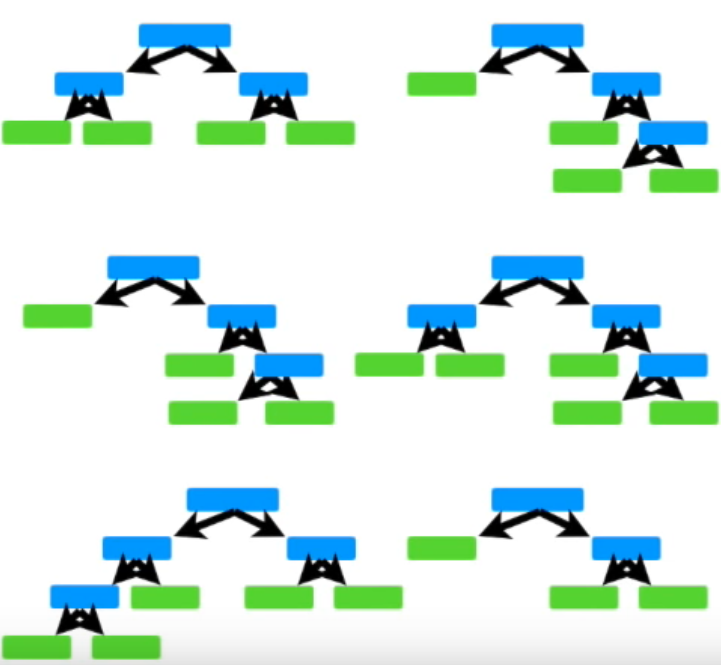
하지만 AdaBoost에서는 특정 stummp가 다른 stump보다 더 중요하다. (가중치가 더 높다) 아래 그림에서 보는 것 처럼 크기가 큰 것은 가중치가 더 높은 stump를 말한다. 여기서 가중치가 높다는 것을 Amount of Say가 높다고 표현한다. 결과에 미치는 영향이 크다는 뜻이다.
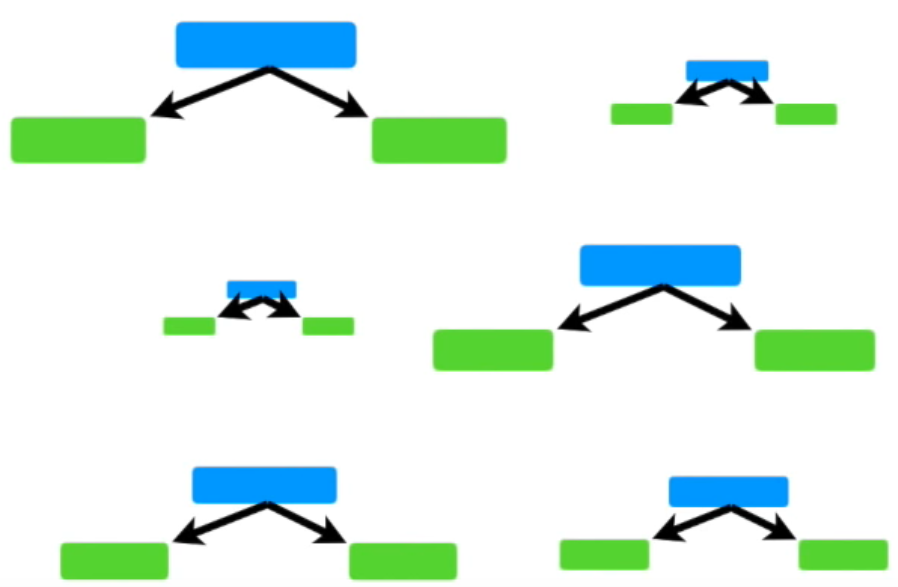
또한, 첫번째 stump에서 발생한 error는 두번째 stump의 결과에 영향을 준다. 두번째 stump에서 발생한 error 역시 세번째 stump의 결과에 영향을 준다. 그렇게 마지막 stump까지 줄줄이 영향을 준다. (AdaBoost가 부스팅 종류 중 하나라서 부스팅의 원리와 당연히 동일하다)
정리하자면, AdaBoost는 다음과 같은 3가지 특징을 가지고 있다.
-
약한 학습기(weak learner)로 구성되어 있으며, 약한 학습기는 stump의 형태이다.
-
어떤 stump는 다른 stump보다 가중치가 높다 (Amount of Say가 크다)
-
각 stump의 error는 다음 stump의 결과에 영향을 준다.
출처
https://www.youtube.com/watch?v=LsK-xG1cLYA
https://bkshin.tistory.com/entry/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-14-AdaBoost
