분류를 수행할 수 있는 기계 학습 알고리즘을 만들고 나면, 그 분류기의 예측력을 검증/평가 해봐야 한다.
모델의 성능을 평가하려면 모델을 생성하기 전부터 애초에 데이터를 학습 세트와 평가 세트로 분리해서, 학습 세트로 모델을 만들고 평가 세트로 그 모델의 정확도를 확인하는 절차를 거친다. (자세한 내용은 이 포스팅을 참고)
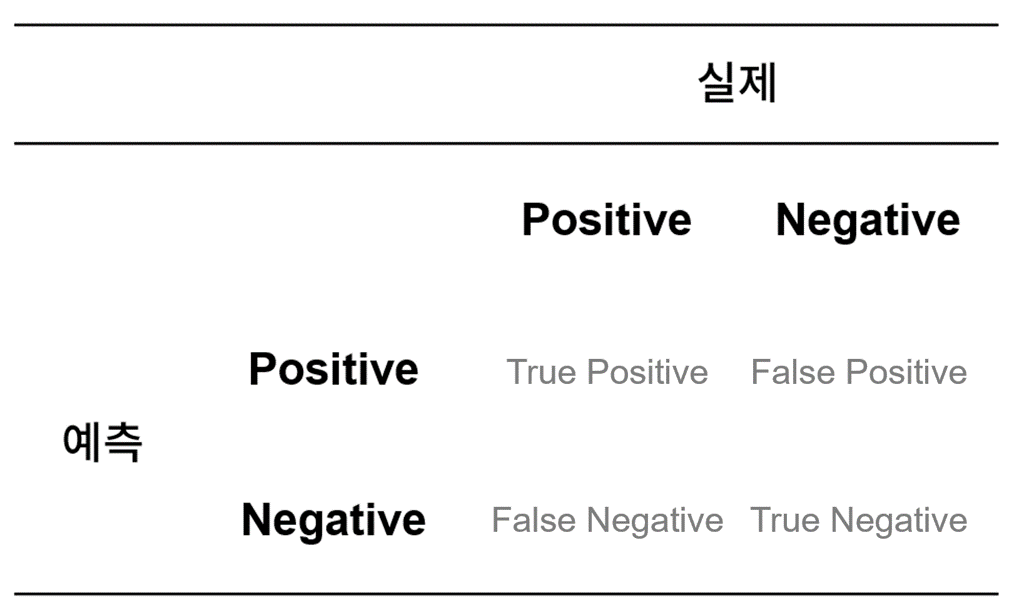
그런데 분류 모델 성능 평가 지표를 소개하기 전에 정답을 맞히거나 틀리는 경우의 수들을 먼저 이해해야 한다.
-
True Positive : 실제 Positive인 정답을 Positive라고 예측(True)
-
True Negative : 실제 Negative인 정답을 Negative라고 예측 (True)
-
False Positive : 실제 Negative인 정답을 Positive라고 예측 (False) - Type Ⅰ error
-
False Negative : 실제 Positive인 정답을 Negative라고 예측 (False) - Type Ⅱ error
여기서 그 유명한 1종 오류, 2종 오류의 개념이 등장한다. 이 두 유형의 오류는 분류 과제의 성격에 따라 경중이 다르다.
예를 들어 중고차 성능 판별 과제에서는 1종 오류(False Positive), 즉 좋은 자동차라 예측하고 구매하였지만 실제로는 좋지 않은 자동차였을 경우가 더 치명적이다. 좋은 중고차를 나쁜 차로 예측해서 구매하지 않더라도 손해볼 것이 없지만 나쁜 중고차를 좋은 차로 잘못 예측하여 구매하는 건 굉장한 손해니까.
그러나 분류 과제가 암환자 진단이라면 2종 오류(False Negative), 즉 암 환자를 건강하다고 판별하는 경우가 훨씬 치명적이다. 그 사람의 생명이 위험해질 수 있으니까.
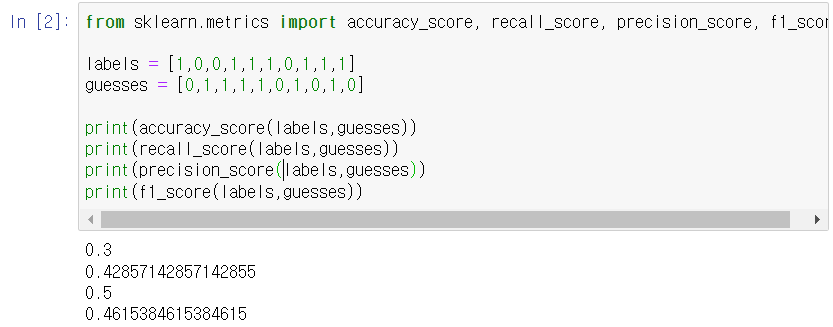
아무튼 이 개념을 파이썬 코드로 표현해보면 아래와 같다. (정답 labels와 예측한 값 guesses이 있을 때)
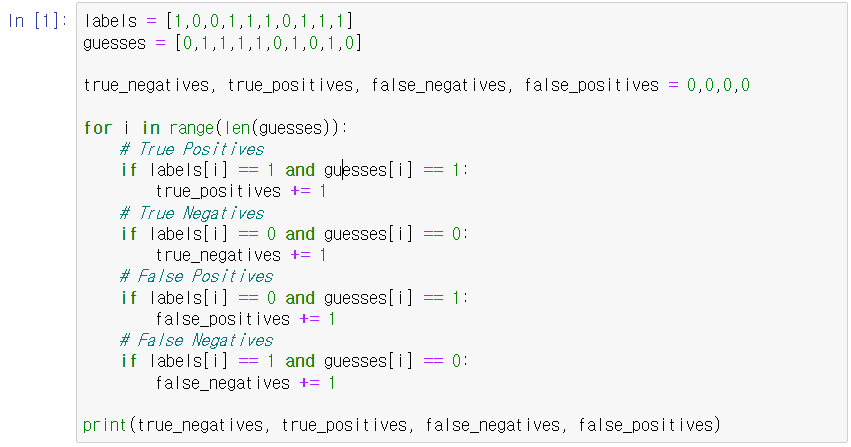
계산된 값을 보면 각각 3, 0, 3, 4 순으로 나온다.
이제 이 개념들을 가지고 분류 모델의 성능을 평가할 수 있는 지표를 총 4개 소개하고자 한다.
- Accuracy
- Recall
- Precision
- F1 Score
하나씩 자세히 살펴보자.
1. Accuracy (정확도)
accuracy는 다음과 같이 정의할 수 있다.
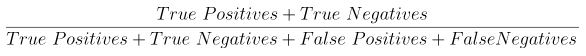
전체 예측 건수에서 정답을 맞힌 건수의 비율이다. (여기서 정답을 맞힐 때 답이 Positive든 Negative든 상관 없다. 맞히기만 하면 된다.)
Accuracy의 단점
예를 들면 내일 서울에 시간당 1m 이상의 눈이 내릴지 여부를 예측한다고 해보자. 그땐 뭐 머신러닝이고 뭐고 할 거 없이 나 혼자서도 매우 정확한 분류기를 만들 수 있다. 그냥 무조건 Negative를 예측하면 이 분류기는 99.9%의 accuracy를 나타낼 거다. 그 정도 눈 내리는 날은 거의 없으니까. 이 분류기의 정답을 True Negative로만 잔뜩 맞히는 셈이다. True Positive는 하나도 발견하지 못하고.
이런 상황을 정확도 역설(Accuracy Paradox)라고 부른다.
그래서 이렇게 실제 데이터에 Negative 비율이 너무 높아서 희박한 가능성으로 발생할 상황에 대해 제대로된 분류를 해주는지 평가해줄 지표는 바로 recall(재현율)이다.
2. Recall (재현율)
recall은 다음과 같이 정의할 수 있다.
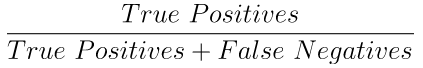
실제로 정답이 True인 것들 중에서 분류기가 True로 예측한 비율이다. 그래서 애초에 True가 발생하는 확률이 적을 때 사용하면 좋다.
그래서 위에서 예로 들었던 시간당 1m 이상의 눈이 내릴지 예측하는 과제에 적절한 거다. 그러면 실제로 그렇게 눈이 내린 날짜 중 몇 개나 맞히는지 확인할 수 있으니까. 만약 여기서 언제나 False로 예측하는 분류기가 있다면 accuracy는 거의 99%를 넘기겠지만, True Positive를 찾을 수 없으니 recall이 0이 된다.
Recall의 단점
그러나 안타깝게도 recall 또한 완벽한 통계 지표가 아니다. 시간당 적설량 1m 이상이 될지 분류하는 과제에서 언제나 True만 답하는 분류기가 있다고 해보자. 그러면 accuracy는 낮지만 눈이 많이 온 날에 대해서만큼은 정확하게 맞힐 수 있기 때문에 recall은 1이 된다. 이 역시 말이 안 되는 지표다.
3. Precision (정밀도)
precision은 다음과 같이 정의할 수 있다.
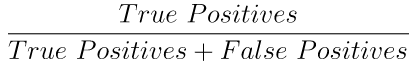
분류기가 눈이 많이 내릴 것이라고 예측한 날 중에 실제로 눈이 많이 내린 날의 비율을 구하는 것이다.
그래서 언제나 True만 답하는 분류기가 있다면 recall은 1로 나오겠지만, precision은 0에 가까울 거다. 시간당 1m 이상 눈 내리는 날이 며칠이나 되겠는가.
Precision의 단점
결국 precision을 사용할 때의 단점은 곧 recall을 사용할 때의 장점이 되기도 한다. recall과 precision은 서로 반대 개념의 지표이기 때문이다. 하나가 내려가면 다른 하나는 올라갈 수밖에 없다.
그래서 알고리즘을 평가할 때 recall과 precision 모두 나름대로 유용한 지표이긴 하지만, 그 알고리즘의 성능을 충분히, 효과적으로 표현하기에는 한계가 있다. 그래서 생겨난 게 recall과 precision의 조화평균, F1 Score다.
4. F1 Score
F1 score는 다음과 같이 정의할 수 있다.

조화평균에 대해서는 중고등학교 때 언젠가 배웠을 거다. 나도 가물가물하긴 한데 사실 잊어버렸더라도 상관없다. 컴퓨터가 알아서 계산해줄 테니 일단 개념만 알고 가면 되지 뭐.
아무튼 흔히 말하는 평균(산술평균)을 쓰지 않고 조화평균을 구하는 이유는 recall, precision 둘 중 하나가 0에 가깝게 낮을 때 지표에 그것이 잘 반영되도록, 다시말해 두 지표를 모두 균형있게 반영하여 모델의 성능이 좋지 않다는 것을 잘 확인하기 위함이다.
예를 들어 recall, precision이 각각 1과 0.01이라는 값을 가지고 있다고 하자.
산술평균을 구하면 (1+0.01)/2 = 0.505, 즉 절반은 맞히는 것처럼 보인다. 그러나 조화평균을 구해보면 2*(1*0.01)/(1+0.01) = 0.019가 된다. 낮게 잘 나온다.
이제야 분류기의 성능을 좀 제대로 확인할 수 있을 것 같다.
요약
본 포스팅에서는 분류 모델의 성능을 확인할 수 있는 다양한 지표들에 대해 다뤘다.
지표들을 계산하기에 앞서 정답을 맞히거나 틀리는 경우의 수들을 먼저 이해해야 한다.
-
True Positive (
truth = 1,guess = 1) -
True Negative (
truth = 0,guess = 0) -
False Positive (
truth = 0,guess = 1) - Type Ⅰ error -
False negative (
truth = 1,guess = 0) - Type Ⅱ error
이제 이 경우의 수를 사용해서 모델 성능을 평가하는 네 개의 지표를 산출할 수 있는데, 각각의 특징과 장단점이 있다.
-
Accuracy : 모든 분류 건수 중에서 분류기가 몇개의 정답을 맞혔는가 (맞거나 틀리다고 정확히 분류했는가)
-
Recall : 맞다고 분류해야 하는 건수 중에서 분류기가 몇개나 제대로 분류했는가
-
Precision : 분류기가 맞다고 분류한 건수 중에서 실제로 맞는 건수가 몇개나 되는가
*** Recall과 Precision은 trade-off 개념이기 때문에 하나가 높아지면 하나는 낮아진다.
- F1 Score : recall과 precision의 균형값 (조화평균)
어쨌든 분류기의 성능이 좋다는 뜻은 오류가 적다는 뜻이다. 오류가 발생하는 두 가지 경우를 잘 생각해보고, 그 과제의 경중에 따라 효과적인 지표를 사용해서 모델을 검증해야 한다.
scikit-learn에서 확인하는 방법
그리고 파이썬 라이브러리 scikit-learn에서는 이런 통계 지표들을 쉽게 확인할 수 있다. 이렇게.
그리고 분류 결과에 따라 나타나는 경우의 수를 Confusion Matrix(혼동 행렬)로 돌려주는 기능도 있다.

