본 포스팅에서는 파이썬 머신러닝 라이브러리 scikit-learn을 통해 로지스틱 회귀(Logistic Regression) 알고리즘을 통해 타이타닉 탑승객 생존 예측 예제를 소개한다.
이전 포스팅에서는 로지스틱회귀의 기초적인 개념에 대해서 간단히 짚어봤다.
이제 직접 돌려보자
sklearn LogisticRegression 사용법
실제 데이터 돌려보기 전에 사용법부터 익히고 가자. 일다 파이썬 머신러닝 라이브러리 싸이킷런을 불러오자.

이제 LogisticRegression 모델을 생성하고, 그 안에 속성들(features)과 그 레이블(labels)을 fit 시킨다.

fit() 메서드는 모델에 필요한 두 가지 변수를 전달해준다.
-
계수 :
model_coef_ -
절편 :
model.intercept
어쨌든 이게 끝이다.
여기서 만약 .predict()를 사용하면 새로운 속성들을 넣었을 때 그 레이블에 속하는지 아닌지 1 또는 0으로 구성된 벡터를 반환해준다.

그리고 만약 분류 결과가 아니라, 해당 레이블로 분류될 확률 값을 알고 싶다면 predict_proba()를 사용해주면 된다. 당연히 각 샘플에 대한 확률은 0에서 1 사이의 값으로 돌려줄거다.

그런데 실제로 로지스틱 회귀 알고리즘을 사용하기 전에는 반드시 데이터를 정규화(Normalization) 해줘야 한다.
정규화가 궁금하다면 이 포스트를 보고 오자
아래 예제에서 직접 sklearn에서 제공하는 StandardScaler을 통해 표준화, 데이터 스케일링하는 방법을 소개했다.
sklearn LogisticRegression 실전 예제
1. 데이터 불러오기
일단 pandas를 이용해 타이타닉 데이터를 불러와보자.


891명의 데이터가 있고, 총 12개의 컬럼이 있는 걸 확인했다

여기서 Survived가 살았는지 죽었는지 확인하는 레이블이 될 거다. 0 또는 1인데, 1이 살아남은 거다.
2. 데이터 전처리하기
분석에 사용할 feature 고르기
일단 생존 여부에 중요한 영향을 미쳤을 것으로 예상하는 값들만 추려보면, Sex, Age, Pclass를 생각해볼 수 있다. 여성, 어린이, 1/2/3등석 순으로 살아남을 확률이 높다고 가설을 세워본거다.
문자열을 숫자로 변환하기
일단 머신러닝 라이브러리 sklearn에 넣어주기 전에 성별(Sex)은 숫자 데이터 1과 0으로 바꿔주자. 여성이 살아남을 확률이 높을 것 같으니 남성을 0, 여성을 1로 놓자.

결측치 채워주기
데이터를 보면 Age 값이 비어있는 경우가 있다. 이 경우 그냥 평균 값으로 대체해서 넣어주자.
feature 분리하기
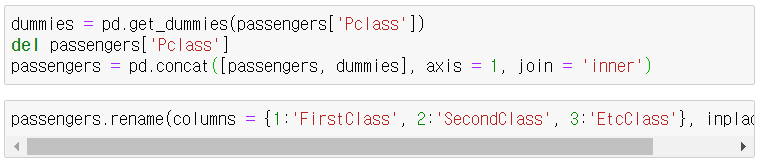
Pclass의 경우 1등석에 탔는지, 2등석에 탔는지에 대해 각각의 feature로 만들어주기 위해 컬럼을 새로 생성해보자.
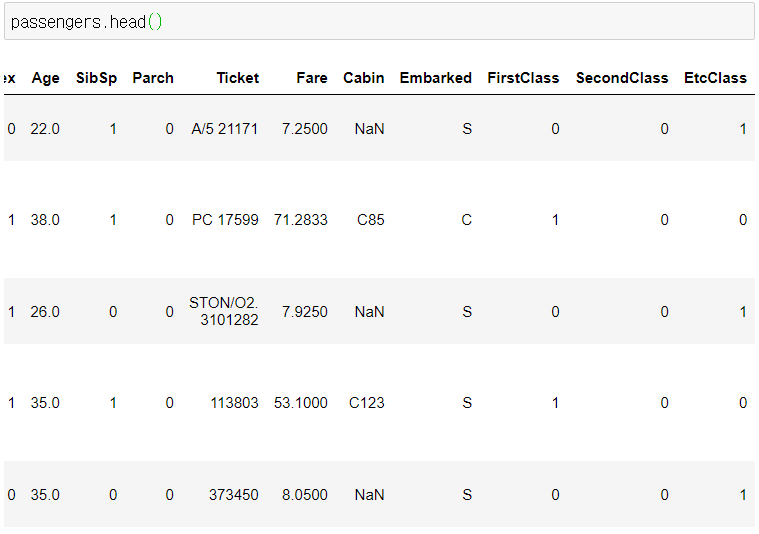
이 정도 했으면 이제 데이터 세트를 이렇게 준비할 수 있겠다.

3. 학습세트/평가세트 분리하기
sklearn의 train_test_split을 사용해서 학습세트와 평가세트를 분리하자

4. ⭐ 데이터 정규화(스케일링)하기
중요한 파트다
로지스틱 회귀는 실행할 때 regularation을 사용하기 때문에 그 전에 반드시 우리가 가진 데이터를 스케일링하는 작업이 필요하다. (이 부분은 이해 안 가더라도 일단 그냥 해야 된다고 생각하자.)
sklearn이 제공하는 StandardScaler를 활용해서 손쉽게 할 수 있다. StandardScaler는 평균 0, 표준편차 1로 변환하는 방법이지만 이외에도 최소값 0, 최대값 1이 되도록 변환하는 MinMaxScaler, 중앙값 0, IQR 1이 되도록 변환하는 RobustScaler 등이 있다.
StandardScaler를 사용하면 아래와 같이 데이터를 정규화(스케일러)할 수 있다

fit_transform은 fit과 transform을 합친건데, fit은 일단 각 속성(feature)마다 컬럼을 만드는 작업이라고 생각하면 된다. 이후 transform을 통해 데이터를 변형시키는 거다.
그래서 바로 위 코드에서도 학습세트로 fit을 한 번 해주었기 때문에, 평가세트에서는 별도로 fit을 할 필요 없이 바로 transform하면 되는 거다.
5. 모델 생성 및 평가하기
모델을 생성하는 방법은 아래와 같다

데이터만 넣어주고 fit 해주면 끝이다.
그러면 이제 학습 세트로 정확도를 바로 찍어볼 수 있다.

80% 정도 맞춘다고 한다.
아까 분리해놓은 테스트 세트에서도 확인해볼 수 있다.

이번엔 76% 정도. 나쁘지 않다.
이번엔 각 feature들의 계수(coefficients)를 확인해볼 차례다. 어떤 feature가 생존에 큰 영향을 주는지 확인해볼 수 있으니까.

아까 Sex, Age, FirstClass, SecondClass 순으로 넣었기 때문에 그 순서대로 확인해주면 된다. 성별이 1(여자)이고, 일등석 탑승 여부가 중ㅇ하다는 걸 알 수 있다. 반면 나이에 대한 계수는 음수가 나오는데 나이가 많을수록 생존 확률이 낮아진다는 의미로 이해하면 되겠다
6. 예측하기
이번엔 새로운 데이터를 넣어서 예측해보자
예를 들면 아래와 같이 타이타닉 영화 실제 주인공이었던 Jack, Rose의 값을 임의로 만들고, 내 정보도 넣어봤다.

그 다음 위에서 했던 것처럼 데이터 스케일링을 다시 해줘야 한다.

그리고 예측을 해보자

Jack만 죽는 걸로 나온다.
확률을 확인해보자

왼쪽이 죽을 확률(0) 오른쪽이 살 확률(1)로 해석하면 된다
난 살 확률이 90%나 된다 😀

"4. ⭐ 데이터 정규화(스케일링)하기"에서 test feature 다루실 때에는 fit_transform이 아니라 transform을 사용해야하지 않을까요? Data leakage같은데...