- 노래 : The Great Escape
- 아티스트 : Boys Like Girls
아주 대표적인 띵곡중의 하나조?

1. 웹 스크래핑 vs. 웹 크롤링 차이😀
- 웹 페이지 안에서 필요한 부분만 가져오는 것이 웹 스크래핑
- 크롤링은 웹 페이지내에서 허용된 페이지를 마구잡이로 데이터를 가져오는 것
웹은 크게 3가지로 구성되어 있조?👪
- html(뼈대)
- css(예쁘게)
- js(움직임)
xpath란?🌍
XPath란 (XML Path Language)를 의미합니다.
XPath는 XML 문서의 특정 요소나 속성에 접근하기 위한 경로를 지정하는 언어입니다.
XPath는 W3C 표준 권고안으로, XSLT와 XPointer에 사용될 목적으로 만들어졌습니다.
또한, XML DOM에서 노드를 검색할 때에도 사용할 수 있습니다.
현재 가장 최신 버전의 XPath는 2017년 3월 17일에 발표된 XPath 3.1입니다.
XPath 3.1에 대한 더 자세한 정보를 원한다면, W3C 공식 사이트를 방문하여 확인할 수 있습니다.
위치 경로(location path)🚀
위치 경로(location path)란 XML 문서의 각 노드의 위치를 지정하기 위한 XPath 표현식입니다.
위치 경로는 절대 경로와 상대 경로로 구분할 수 있습니다.
- 절대 경로는 슬래시(/)로 시작하며, 루트 노드부터 순서대로 탐색해 나갑니다.
- 상대 경로는 슬래시(/)로 시작하지 않으며, 기준으로 지정되는 노드부터 탐색해 나갑니다.
위치 경로는 모두 시작 위치 이외에도 슬래시(/)로 구분되는 여러 단계(step)를 포함할 수 있습니다.
위치 경로 표현에 사용되는 대표적인 경로 연산자는 다음과 같습니다.
| 경로 연산자 | 설명 |
|---|---|
| 노드 이름 | 해당 '노드 이름'과 일치하는 모든 노드를 선택함. |
| / | 루트 노드부터 순서대로 탐색해 나감. |
| // | 현재 노드의 위치와 상관없이 지정된 노드에서부터 순서대로 탐색해 나감. |
| . | 현재 노드를 선택함. |
| .. | 현재 노드의 부모 노드를 선택함. |
| @ | 속성 노드를 선택함. |
xpath가 무엇인지 그리고 경로를 copy해서 가져올 때 어느정도의 이해 할 수 있는 수준이면되요.
request 모듈🌍
백문이 불여일타!
아래 코드 따라서 한번 쳐보시조?!
import requests
# res = requests.get('http://naver.com')
res = requests.get('https://velog.io/@hyeseong-dev')
print('응답코드',res.status_code) # 200이면 정상여기서의 요점은
- 하나, request모듈을 이용
- 둘, request객체의 속성인
status_code를 통해서 htpp code를 확인 할 수 있어요(ex.200, 404.등등)
status code에 따라 분기하기()🚀
import requests
# res = requests.get('http://naver.com')
res = requests.get('https://velog.io/@hyeseong-dev/오류발생시킬게요')
print('응답코드',res.status_code) # 200이면 정상
if res.status_code == requests.codes.ok:
print('정상입니다.')
else:
print('문제가 발생했어요.[오류코드 ', res.status_code,']')위 방법을 if문으로 처리 할 수 있지만 다른 방법도 있어요.
raise_for_status()🚀
간단히 오류 처리를 위한 유용한 메서드에요.
위 if문으로 오류 처리하는 것과 어떤 차이가 있을까요.
- 간단하다.(한줄이면 끝)
- 오류가 있는 부분을 확인해주고 그 오류 결과를 리턴해주며 프로그램을 끝내는 기본적으로 3가지 기능이 있음.
import requests
# res = requests.get('http://naver.com')
res = requests.get('https://velog.io/@hyeseong-dev/오류발생시킬게요')
print('응답코드',res.status_code) # 200이면 정상
# if res.status_code == requests.codes.ok:
# print('정상입니다.')
# else:
# print('문제가 발생했어요.[오류코드 ', res.status_code,']')
res.raise_for_status() # 오류를 발생시키고 해당 오류에 대한 결과를 반환해주며 프로그램을 끝내요.
print('웹스크래핑을 진행합니다.')그래서 기본적으로 웹 스크래핑을 본격적으로 진행하기 이전에 아래와 같이 res 객체 생성이후 바로 다음줄에 raise_for_stats()를 작성해줘요.
그래서 3,4번째 줄과 같이 항상 쌍으로 쓴다! 는 점만 짚고 넘어 갈게요.
import requests
res = requests.get('https://velog.io/@hyeseong-dev/오류발생시킬게요')
res.raise_for_status()res객체 html파일로 저장()🚀
with open구문으로 파일을 생성하고 res객체의 text를 저장해볼게요.
import requests
res = requests.get('http://google.com')
res.raise_for_status()
with open('mygoogle.html', 'w', encoding='utf8') as f:
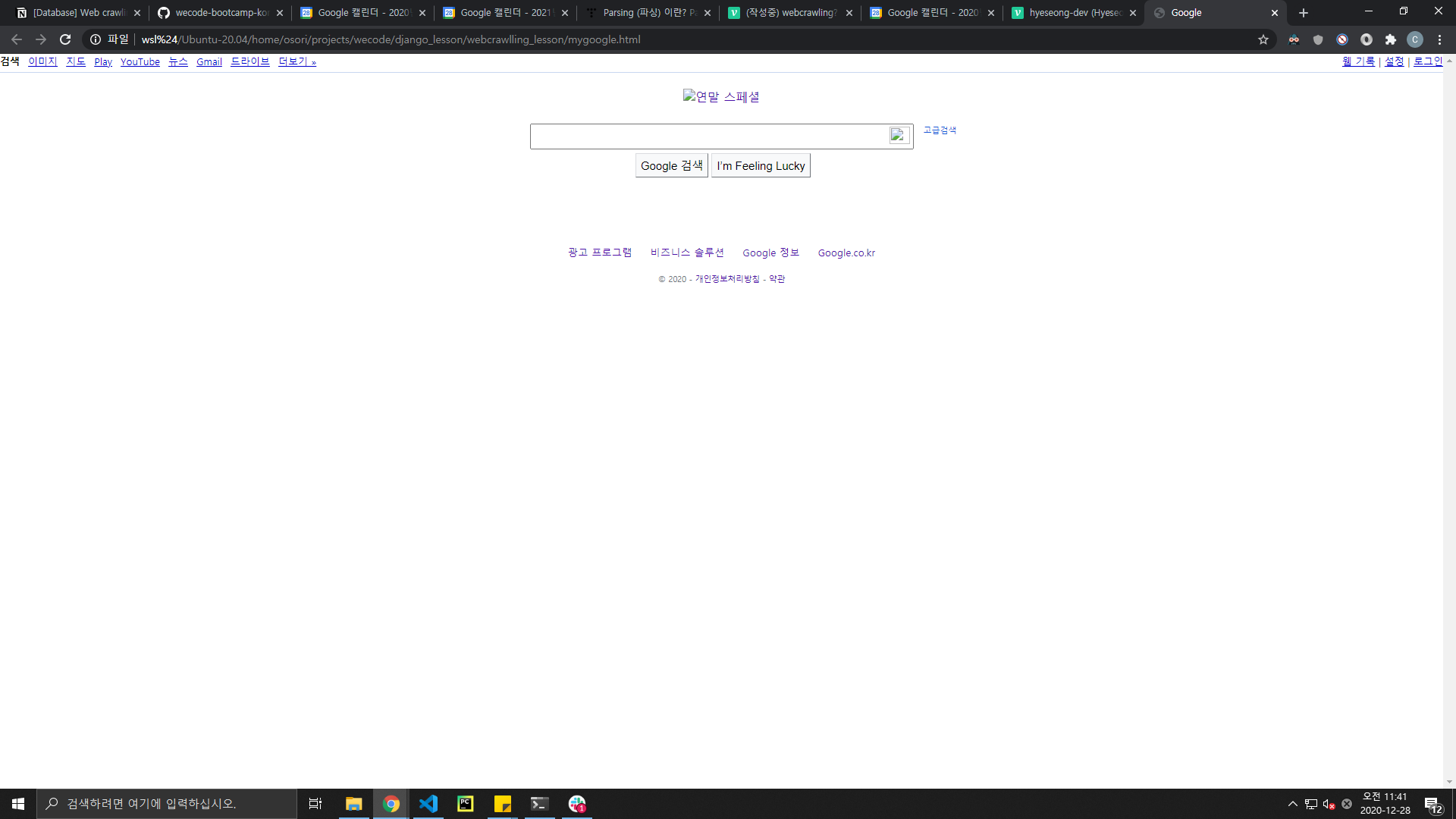
f.write(res.text)그럼 현재 작업 경로에 html파일이 만들어집니다. 열어보면 아래와 같아요.
물론 style이 안먹혀 있지만 결과적으로 해당 페이지의 뼈대를 가져온거에요.
re 모듈🌍
정규표현식(regular expression), 어떤 정해진 형태의 식을 말해요.
주민등록번호
900922-1798673
# 이것을 우리는 일반적인 주민등록 표현형태의 식이라고 봅니다.
abcddd-1183726 # 이라고 나오면 우리는 주민등록번호가 아니라고 파악합니다.
이메일주소
hyeseong43@gmail.com # 골뱅이를 기준으로 영문과 숫자가 있고 이후에는 다시 영문과 점이 있조.
hyeseong43@gmail@gmail.com # 이건 골뱅이가 2개나 있어서 이메일이 아닌거조?
차량 번호
11가 1234
123가 1234
# 차량 번호의 경우 앞에 2~3자리의 숫자가 나오가이후 문자하나가 오고 스페이스바가 온다음 숫자 4자리가 오게되조.
IP주소
192.168.0.1 # 올바른 IP 주소식(O)
1000.2000.3000.4000 # 올바른 IP 주소식(X)
사실 정규식은 굉장히 어렵습니다. 간단한 것만 짚고 넘어 갈게요.
정규식 사용 - 1 🚀
import re
# ca?e
# care, cafe, case, cave
# caae, cabe, cace, cade, ...
p = re.compile("ca.e") # compile 메소드를 통해서 패턴을 만들어주게 되요.
# . (ca.e) : 하나의 문자를 의미 > care, cafe, case (O) | caffe (X)
# ^ (^de) : 문자열의 시작 > desk, destination (O) | fade (X)
# $ (se$) : 문자열의 끝 > case, base (O) | face (X)
m = p.match('case')
print(m.group())
# Output : case- 내가 만든
re를 컴파일하고 객체를 변수에 담음
- 내가 만든
- compile객체의
match()메소드를 이용해 말그대로 내가 확인하고자 하는 문자를 파라미터로 두고 반환된 값을 변수 m에 저장함
- compile객체의
- m의 속성값 group() 메소드를 호출해 반환된 값 case를 확인하므로 정상적으로 매칭된것을 확인함.
참고 match되지 않으면 값을 반환하지 않고 error발생함
그럼 중요한 것이 값이 반환되지 않았을 경우 개발자의 대처가 필요합니다.
match() 메소드가 정상적이다면, 반환값이 있겠조?!
반대로 오류라면, 반환값이 없지요!
즉 if문 써서 오류 발생 처리를 할 수 있어요.
import re
p = re.compile("ca.e")
m = p.match('caffe') # 매칭되지 않음이라는 문자열이 터미널에 발생
if m:
print("m.group():", m.group()) # 일치하는 문자열 반환
else:
print("매칭되지 않음")
match(): 주어진 문자열의 처음부터 일치하는지 확인
p = re.compile("ca.e")
# . (ca.e) : 하나의 문자를 의미 > care, cafe, case (O) | caffe (X)
# ^ (^de) : 문자열의 시작 > desk, destination (O) | fade (X)
# $ (se$) : 문자열의 끝 > case, base (O) | face (X)
def print_match(m):
if m:
print("m.group():", m.group()) # 일치하는 문자열 반환
else:
print("매칭되지 않음")
# m = p.match("careless") # match : 주어진 문자열의 처음부터 일치하는지 확인
print_match(m)
# output : care정규식 사용 - 2 🚀
search() 메서드 사용⛄
search(): 주어진 문자열 중에 일치하는게 있는지 확인
p = re.compile("ca.e")
def print_match(m):
if m:
print("m.group():", m.group()) # 일치하는 문자열 반환
else:
print("매칭되지 않음")
# m = p.search("good care") # search : 주어진 문자열 중에 일치하는게 있는지 확인
# print_match(m)
# output : caregroup() 메서드 말고 다른것들⛄
m.group() - 일치하는 문자열 반환
m.string() - 입력받은 문자열
m.start() - 일치하는 문자열의 시작 index
m.end() - 일치하는 문자열의 끝 index
m.span() - 일치하는 문자열의 시작 / 끝 index
p = re.compile("ca.e")
def print_match(m):
if m:
print("m.group():", m.group()) # 일치하는 문자열 반환
print("m.string:", m.string) # 입력받은 문자열
print("m.start():", m.start()) # 일치하는 문자열의 시작 index
print("m.end():", m.end()) # 일치하는 문자열의 끝 index
print("m.span():", m.span()) # 일치하는 문자열의 시작 / 끝 index
else:
print("매칭되지 않음")
# m = p.search("good care") # search : 주어진 문자열 중에 일치하는게 있는지 확인
# print_match(m)
# output : carefindall() 너는 뭐니?⛄
findall : 일치하는 모든 것을 리스트 형태로 반환
good care cafe라는 문자열 2개를 넣었더니 일치하는 문자열 2개가 반환된거 보이조?
def print_match(m):
if m:
print("m.group():", m.group()) # 일치하는 문자열 반환
print("m.string:", m.string) # 입력받은 문자열
print("m.start():", m.start()) # 일치하는 문자열의 시작 index
print("m.end():", m.end()) # 일치하는 문자열의 끝 index
print("m.span():", m.span()) # 일치하는 문자열의 시작 / 끝 index
else:
print("매칭되지 않음")
lst = p.findall("good care cafe") #
print(lst)
# output : ['care','cafe']그래서~ 뭐 배웠지?😀
p = re.compile("원하는 형태")
m = p.match("비교할 문자열") : 주어진 문자열의 처음부터 일치하는지 확인
3. m = p.search("비교할 문자열") : 주어진 문자열 중에 일치하는게 있는지 확인
4. lst = p.findall("비교할 문자열") : 일치하는 모든 것을 "리스트" 형태로 반환
원하는 형태 : 정규식
. (ca.e) : 하나의 문자를 의미 > care, cafe, case (O) | caffe (X)
^ (^de) : 문자열의 시작 > desk, destination (O) | fade (X)
$ (se$) : 문자열의 끝 > case, base (O) | face (X)참고할 만한 사이트
- w3c
- python 공식문서
