Web Servers
프로그램은 네트워크가 제공하는 input보다 더 빠르게 처리를 합니다. 그렇게 되면 CPU의 사용률이 낮아서 CPU가 낭비가 됩니다.
Web Server는 특히 수 백개의 request를 처리하게 됩니다. 그렇게 되면 빠른 것도 있지만 느린 것도 있을 것입니다. 이것을 하나의 스레드로 처리한다면 어떨까요?
하나의 스레드라면 모든 작업을 순차적으로 진행해야 합니다. 먼저 들어온 작업이 느린 작업이더라도 아래 작업들이 모두 기다리고 있게 되는 상황이 발생합니다. 이처럼 여러개의 connection을 다뤄야 하는 Web server와 같은 상황에서 효율적인 CPU사용을 가능하게 하는 무엇인가가 필요합니다.
Handling Multi Request
여러개의 요청을 처리하기 위한 방법을 생각해봅시다.
- 새로운 요청마다 Process 생성
- Process는 별도의 메모리 공간이 필요
- 요청이 많아지면 메모리 공간이 부족해져서 활용성이 떨어짐
- process pool
- Process의 개수를 정해두고 사용
- multi-threaded program
- Thread가 Process보다 가벼움
Thread
- CPU 이용의 가장 기본적인 단위
- 별도의 독립적인 실행 흐름
- Thread vs Process
- Process는 memory가 완전히 따로 할당되어 있고 하나의 스레드를 가집니다.
- Thread는 레지스터와 스택만 새로 만들어지고 shared memory(code, data, files)는 공유합니다. 따라서 Process보다 부담이 덜 합니다.
- Multi threading
- 게임 프로그래밍
- 네트워크 프로그래밍
Running Threads in Java
Java에서 Thread를 만드는 2가지 방법이 있습니다.
- subclassing Thread class
- implementing Runnable interface
Subclassing Thread Class
- 생성 방법
Thread t = new Thread();
t.start()- 실행 : run() 오바라이드
- run 메서드
- Thread가 무엇을 할지 정의하는 메서드
- Thread가 하는 모든 일이 들어감
- 여기서 시작해서 여기서 끝나게 됨
- 프로그램의 main함수와 같다고 생각하면 됨
Example
여러 파일에 엑세스해서 어떤 작업을 해야 하는 상황을 가정합니다. 이 상황에서는 Thread를 사용하는 것이 효율적입니다. 그 이유는 파일 엑세스가 CPU보다 느리기 때문에 IO-bound 프로그램이기 때문입니다. 하나의 스레드만 사용한다면 파일을 엑세스할 때마다 blocking이 일어나게 됩니다.
이 문제를 Multi Thread로 해결을 한다면, 파일을 읽는 것을 기다리는 동안 다른 파일을 읽는 것이 실행되도록 하여 효율적인 CPU사용이 가능해집니다.
아래 간단한 코드를 살펴보겠습니다.
public class TestThread extends Thread {
private String filename;
public TestThread(String filename){
this.filename = filename;
}
@Override
public void run(){
//read file code
StringBuilder result = new StringBuilder(filename);
result.append("-> read file finished");
System.out.println(result);
}
public static void main(String[] args) {
for (String filename : args){
Thread t = new TestThread(filename);
t.start();
}
}
}- extends Thread하여 클래스 생성
- run메서드 오버라이드
- Thread가 start되면 run메서드에 정의한 작업을 하게 됨
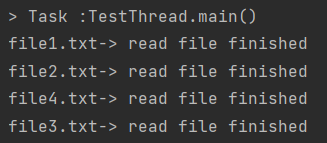
- 순서가 바뀔 수 있습니다.
- single thread는 첫번째 작업이 끝나야 다음 작업을 하지만 multi thread에서는 작업이 끝나는 순서가 보장되지 않습니다.
StringBuilder를 사용하는 이유
System.out.print(filename);
System.out.println("-> read file finished");위와 같이 출력을 한다면 개발자가 원하는 대로 출력이 될까요? 직접 출력을 해보면 아래와 같이 출력이 되는 것을 알 수 있습니다.
print는 기본적으로 공유되고 있다고 생각할 수 있다.
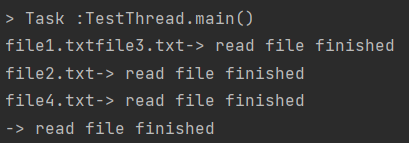
그 이유는 기본적으로 콘솔은 공유되기 때문입니다. 따라서 Multi Thread 환경에서는 저렇게 출력을 하면 안됩니다.
위의 예제처럼 StringBuilder를 사용하면 정상적을 출력되는 이유는 JVM에서 local variable은 공유되지 않기 때문입니다. Thread별로 변수를 가지고 있기 때문에 의도했던대로 출력이 된 것입니다.
Implementing Runnable Interface
Runnable interface를 구현을 하고, 이 Runnable 객체를 Thread의 생성자에 넣어주는 방법을 사용하게 됩니다.
subclassing Thread와 비교
- subclassing: white box
- Thread를 상속해서 사용하므로 Thread내용에 엑세스 가능
- run메서드에 해야할 일을 정의하는데, 이것은 Thread class와는 크게 관련이 없는 일
- Thread class는 단지 Thread를 만들고 실행되도록 하는 것
- interface: black box
- Thread class의 어떤 것도 엑세스 불가 → protected
- Thread와 task를 잘 분리함
앞서 Thread를 subclass한 방식과 구조는 동일합니다.
public class TestRunnable implements Runnable{
private String filename;
public TestRunnable(String filename) {
this.filename = filename;
}
@Override
public void run(){
//read file code
StringBuilder result = new StringBuilder(filename);
result.append("-> read file finished");
System.out.println(result);
}
public static void main(String[] args) {
for (String filename : args){
TestRunnable test = new TestRunnable(filename);
Thread t = new Thread(test);
t.start();
}
}
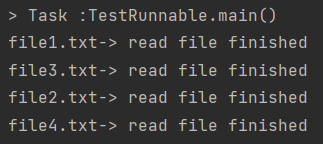
}아래와 같이 실행 결과가 동일하게 출력되는 것을 확인할 수 있습니다.
Returning Information from a Thread
스레드에서 만들어진 정보를 main에서 받아오는 작업을 하려고 합니다. 그러기 위해서는 getter 메서드를 추가로 만들어봅니다.
- Subclassing
- subclass에서 field를 추가해서 getter메서드를 통해서 field에 엑세스
- Runnable
- Runnable에 field를 추가해서 getter메서드를 통해서 field엑세스
하지만 getter()를 통해서 정보를 가져오는 시기를 어떻게 정해야 할까요?
Thread를 만드는 동시에 getter()로 정보를 가져오려고 한다면 아직 Thread가 끝나서 정보를 넣었다는 보장이 없어서 제대로 동작하지 않습니다. 이런 것을 Race Condition이라고 합니다.
Race Condition
getter메서드가 불리기 전에 Thread가 finish되지 않을 수 있습니다.
- 결과에 미치는 요소
- cpu속도
- thread 개수
- 사용 알고리즘
여러 요소에 의해서 보장이 불가능 합니다.
이런 상황을 race condition이라고 합니다. worker가 다 끝내야지 main이 get을 할 수있는데 누가 먼저 실행되는지에 따라서 결과가 달라집니다. 이것이 마치 race하는 것과 같아서 race condition이라고 부릅니다.
Polling
polling은 무언가 계속해서 물어보는 것입니다. polling방식을 이용한다면 field가 null이 아닐 때 print가 되도록 main에서 while문을 통해서 계속 확인하는 것입니다. null이 되면 출력을 하고 while문을 break합니다.
이 방법은 정상적으로 동작한다고 해도 busy waiting 방식이라 계속 CPU와 리소스를 낭비하게 됩니다.
중요한 것은 모든 플랫폼에서 정상적으로 동작하지 않을 수 있다는 것입니다. 어떤 시스템은 main에서 계속 확인을 하게 되니까 계속 리소스를 잡고 있게 합니다. 그러면 스레드에게 CPU사용권이 가지 않아서 무한루프에 빠지게 됩니다.
따라서 polling 방식은 좋은 방법이 아닙니다.
Callback
Callback은 thread가 main에 있는 것을 불러서 자신이 언제 끝났는지 main에 알려주는 방식입니다. CallbackInterface에 출력을 하는 메서드를 만들고, 그 메서드를 run안에서 불러서 출력을 하게 합니다.
public class TestCallback implements Runnable{
private String filename;
public TestCallback(String filename) {
this.filename = filename;
}
@Override
public void run() {
CallbackInterface.receiveString(filename);
}
}public class CallbackInterface {
public static void receiveString(String name) {
StringBuilder result = new StringBuilder(name);
result.append("-> read file finished");
System.out.println(result);
}
public static void main(String[] args) {
for (String filename : args){
TestCallback cb = new TestCallback(filename);
Thread t = new Thread(cb);
t.start();
}
}
}위의 방식은 static method를 call하는 방식입니다. 이 방식이외에도 인스턴스를 생성해서 인스ㅌㄴ스의 메서드를 call하는 방식으로도 가능합니다.
Callback vs Polling
이런 Callback방식은 Polling방식과 비교했을 때, CPU를 낭비하지 않고 유연하다는 장점이 있습니다.
- CPU를 낭비하지 않는다
- 더 유연하다
- 여러개의 인스턴스가 하나의 스레드의 정보에 관심있으면 배열로 만들어서 전달 가능
- 하나의 인스턴스가 하나와 매핑이 된다.
Futures, Callables, Executors
- ExecutorService: 필요에 따라 스레드 생성, callable필요
- Callable: call메서드에 return 타입 존재, 를 return가능
- Callable job을 ExcutorService에 서비스하고, Future인스턴스를 받음
- Future을 통해서 job의 결과를 가져옴
// TestTask는 Callable<Integer>을 implement한 class
TestTask task = new TestTask(data, 0, data.length);
ExecutorService sevice = Executors.newFixedThreadPool(1);
Future<Integer> future = service.submit(task);- 개발자가 asynchronicity를 신경 쓰지 않아도 돼서 편함
