YOLOv4 single class custom model using google colab
env: google colaboratory
1. 환경설정
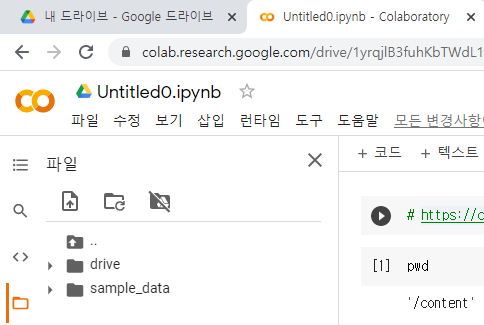
1) GPU 사용 설정
새 코랩 ipynb파일을 열고 수정 > 노트설정 > 하드웨어 가속기: GPU 선택
2) 현재 위치 확인
pwdcontent 디렉토리에 darknet git clone 해야 함
3) 구글 마운트 및 프로젝트 폴더 생성

내 드라이브 안에 중요한 파일들을 저장해둘 yolov4 파일 생성
yolov4 폴더 경로: /content/drive/MyDrive/yolov4
2. Darknet 설치
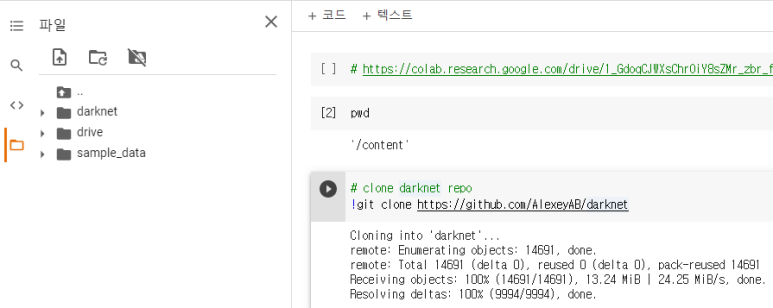
pwd가 content/인 상태에서 darknet 설치
darknet 경로: /content/darknet
change makefile to have GPU and OPENCV enabled
%cd darknet
!sed -i 's/OPENCV=0/OPENCV=1/' Makefile
!sed -i 's/GPU=0/GPU=1/' Makefile
!sed -i 's/CUDNN=0/CUDNN=1/' Makefile
!sed -i 's/CUDNN_HALF=0/CUDNN_HALF=1/' Makefile
# verify CUDA
!/usr/local/cuda/bin/nvcc --version
# make darknet (builds darknet so that you can then use the darknet executable file to run or train object detectors)
!make출처의 코드에서 make darknet 까지 그대로 실행
3. yolov4.weights 다운로드
!wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights다운로드 하고 나면 /content/darknet/yolov4.weights 이 경로에 파일이 생김
4. 테스트
# define helper functions
def imShow(path):
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
image = cv2.imread(path)
height, width = image.shape[:2]
resized_image = cv2.resize(image,(3*width, 3*height), interpolation = cv2.INTER_CUBIC)
fig = plt.gcf()
fig.set_size_inches(18, 10)
plt.axis("off")
plt.imshow(cv2.cvtColor(resized_image, cv2.COLOR_BGR2RGB))
plt.show()
# use this to upload files
def upload():
from google.colab import files
uploaded = files.upload()
for name, data in uploaded.items():
with open(name, 'wb') as f:
f.write(data)
print ('saved file', name)
# use this to download a file
def download(path):
from google.colab import files
files.download(path)# run darknet detection on test images
!./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights data/person.jpg이 코드를 실행하면 코드가 다 실행된 후 마지막 쯔음에
Done! Loaded 162 layers from weights-file
Detection layer: 139 - type = 28
Detection layer: 150 - type = 28
Detection layer: 161 - type = 28
data/person.jpg: Predicted in 55.230000 milli-seconds.
dog: 99%
person: 100%
horse: 98%
Unable to init server: Could not connect: Connection refused
(predictions:1362): Gtk-WARNING **: 23:58:39.903: cannot open display: unable~ 어쩌구가 떠서 제대로 안된건가 당황했지만 imShow하면 결과를 확인할 수는 있다.
# show image using our helper function
imShow('predictions.jpg')
5. OIDv4_Toolkit 설치
원본 git주소: https://github.com/EscVM/OIDv4_ToolKit
그러나 나는 나중에 http://convert_annotations.py/ 을 사용해야 되므로
https://github.com/theAIGuysCode/OIDv4_ToolKit 이거를 깃 클론해준다.
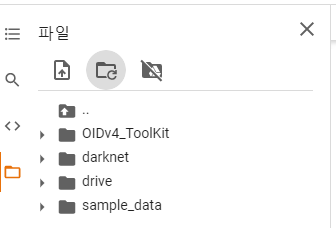
경로확인 후 /content에 다운받는다.
OIDv4의 경로 /content/OIDv4_ToolKit
# https://github.com/theAIGuysCode/OIDv4_ToolKit
!git clone https://github.com/theAIGuysCode/OIDv4_ToolKit6. OIDv4에 필요한 패키지를 설치 및 실행
cd /content/OIDv4_ToolKit
!pip3 install -r requirements.txt
!python3 main.py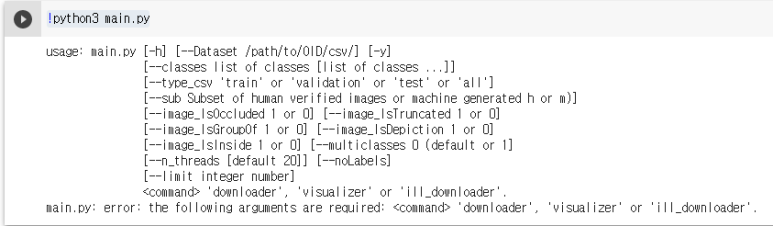
이런 에러가 나와도 괜찮다..아마도
7. 데이터 다운로드
준비된 데이터셋이 있으면 생략가능
!python main.py downloader --classes 'Vehicle registration plate' --type_csv train --limit 50
Vehicle registration plate를 training 용도로 50장 다운로드 하겠다는 의미
!python main.py downloader --classes 'Vehicle registration plate' --type_csv validation --limit 5Vehicle registration plate를 validation 용도로 5장 다운로드 하겠다는 의미
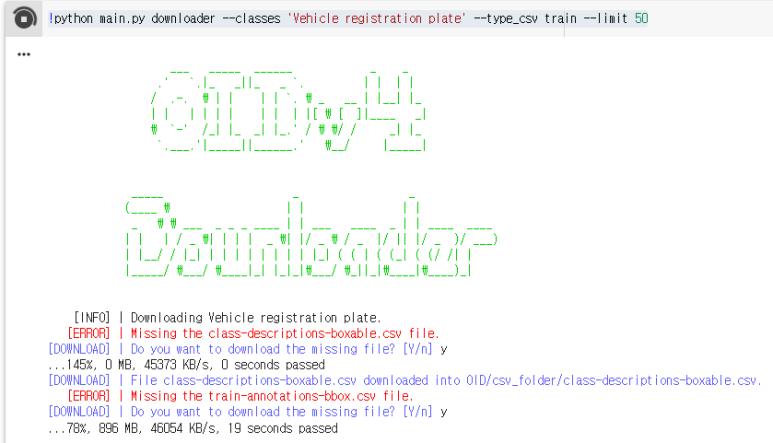
설치과정에서 모드 y를 입력해준다.
다 다운받고 나면,
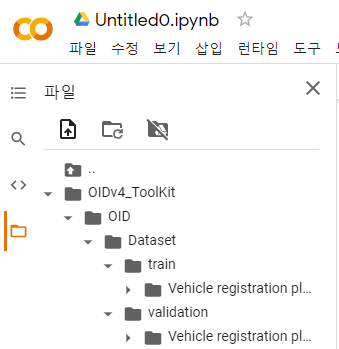
OIDv4_ToolKit 폴더 안에 이런식으로 생긴다 Vehicle registration plate 폴더 안에 파일들은
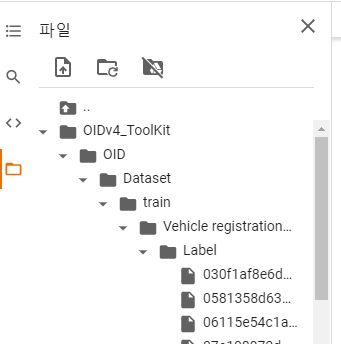
이런 식으로 들어 있음!
여기서 Vehicle 폴더가 하나 더 있는 것을 주의해야 한다.
8. yolo 라벨에 맞도록 convert 및 기존 라벨 파일 삭제
그전에 반드시 classes.txt 파일을 열어서 수정하기
내가 탐지할 객체인 Vehicle registration plate로 수정해준다.
수정 안하면 다음 코드에서 에러 발생한다.
pwd경로 확인 후, /content/OIDv4_ToolKit 위치에서
# yolo 레이블에 맞도록 convert
!python convert_annotations.py
# 예전 label 삭제
!rm -r OID/Dataset/train/'Vehicle registration plate'/Label/
!rm -r OID/Dataset/validation/'Vehicle registration plate'/Label/
아까 있었던 라벨 폴더가 사라졌음을 알 수 있다.
9. yolov4 폴더 구성
학습에 필요한 프로젝트 디렉토리 구성
!ls /content/drive/MyDrive/yolov4generate_test.py
obj.data
obj.zip
backup
generate_train.py
obj.names
test.zip뒤에 확장자가 없는 archive, backup은 폴더파일!
각각의 파일 내용은 다음과 같다.
obj.data와 obj.name, cfg파일은 그냥 텍스트파일로 만들어서 확장자 변경하면 에러가 나므로 다크넷 파일 내의 같은 확장자인 파일을 복사해서 마운트한 드라이브의 프로젝트 폴더 내에 올린 후 코랩 내에서 편집기능을 이용해 편집하는 것을 추천한다.
- obj.data
classes= 1
train = data/train.txt
valid = data/test.txt
names = data/obj.names
backup = /content/drive/MyDrive/yolov4/backup- obj.names
license_plate클래스명과 같아도 상관없지만 너무 길고 띄어쓰기를 없애보고자 이렇게 정했다.
- generate_test.py
import os
image_files = []
os.chdir(os.path.join("data", "test"))
for filename in os.listdir(os.getcwd()):
if filename.endswith(".jpg"):
image_files.append("data/test/" + filename)
os.chdir("..")
with open("test.txt", "w") as outfile:
for image in image_files:
outfile.write(image)
outfile.write("\n")
outfile.close()
os.chdir("..")- generate_train.py
import os
image_files = []
os.chdir(os.path.join("data", "obj"))
for filename in os.listdir(os.getcwd()):
if filename.endswith(".jpg"):
image_files.append("data/obj/" + filename)
os.chdir("..")
with open("train.txt", "w") as outfile:
for image in image_files:
outfile.write(image)
outfile.write("\n")
outfile.close()
os.chdir("..")- 수정한 yolov4-obj.cfg
[net]
# Testing
#batch=1
#subdivisions=1
# Training
batch=64
subdivisions=16
width=416
height=416
channels=3
momentum=0.949
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 6000
policy=steps
steps=4800,5400
scales=.1,.1
#cutmix=1
mosaic=1
#:104x104 54:52x52 85:26x26 104:13x13 for 416
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=mish
# Downsample
[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[route]
layers = -2
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[route]
layers = -1,-7
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
# Downsample
[convolutional]
batch_normalize=1
filters=128
size=3
stride=2
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[route]
layers = -2
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[route]
layers = -1,-10
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
# Downsample
[convolutional]
batch_normalize=1
filters=256
size=3
stride=2
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[route]
layers = -2
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[route]
layers = -1,-28
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
# Downsample
[convolutional]
batch_normalize=1
filters=512
size=3
stride=2
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[route]
layers = -2
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[route]
layers = -1,-28
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
# Downsample
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=2
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[route]
layers = -2
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[route]
layers = -1,-16
[convolutional]
batch_normalize=1
filters=1024
size=1
stride=1
pad=1
activation=mish
stopbackward=800
##########################
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
### SPP ###
[maxpool]
stride=1
size=5
[route]
layers=-2
[maxpool]
stride=1
size=9
[route]
layers=-4
[maxpool]
stride=1
size=13
[route]
layers=-1,-3,-5,-6
### End SPP ###
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = 85
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[route]
layers = -1, -3
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = 54
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[route]
layers = -1, -3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
##########################
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 0,1,2
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=1
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
scale_x_y = 1.2
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
max_delta=5
[route]
layers = -4
[convolutional]
batch_normalize=1
size=3
stride=2
pad=1
filters=256
activation=leaky
[route]
layers = -1, -16
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 3,4,5
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=1
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
scale_x_y = 1.1
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
max_delta=5
[route]
layers = -4
[convolutional]
batch_normalize=1
size=3
stride=2
pad=1
filters=512
activation=leaky
[route]
layers = -1, -37
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 6,7,8
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=1
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
scale_x_y = 1.05
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
max_delta=510. 다크넷 데이터 구축
여기서는 앞선 7번에서 다운로드한 데이터들이 있어서 바로 압축하여 진행했다. 그러나 학습할 트레이닝 데이터가 로컬에 저장되어있다면 구글 마운트한 yolov4 디렉토리에 각각 압축하여 업로드한뒤 압축을 푸는 것 부터 진행하면 된다.
OIDv4_Toolkit에 다운받아진 파일을 다시 다운받아서
(폴더>폴더>파일)안에 폴더 하나 더 있게 말고 (폴더>파일)이 되도록 수정한 다음 다시 압축해서
# copy over both datasets into the root directory of the Colab VM (comment out test.zip if you are not using a validation dataset)
!cp /content/drive/MyDrive/yolov4/obj.zip ../
!cp /content/drive/MyDrive/yolov4/test.zip ..//content/drive/MyDrive/yolov4 에 obj.zip / test.zip으로 저장한다
# unzip the datasets and their contents so that they are now in /darknet/data/ folder
!unzip ../obj.zip -d /content/darknet/data/obj/
!unzip ../test.zip -d /content/darknet/data/test/내폴더에서 VM에 올린걸 다시 darknet/data/ 로 넣는다. 이때, obj와 test가 구분되어 각각의 파일에 들어가야 한다
11. cfg 파일 수정 및 VM에 cfg, names, data 업로드
# download cfg to google drive and change its name
!cp cfg/yolov4-custom.cfg /content/drive/MyDrive/yolov4/yolov4-obj.cfg기존 파일을 내 드라이브로 복사한 다음에 yolyov4 안의 yolov4-obj.cfg 파일 수정한다.
이때, 코랩 내에서 이 파일을 더블클릭하여 편집기를 열어서 내용을 모두 비운다음에 위에
- 수정한 yolov4-obj.cfg
파일의 내용을 복사해서 붙여넣는다.
# upload the custom .cfg back to cloud VM from Google Drive
!cp /content/drive/MyDrive/yolov4/yolov4-obj.cfg ./cfg수정한 cfg파일을 다시 VM에 올린다.
# upload the obj.names and obj.data files to cloud VM from Google Drive
!cp /content/drive/MyDrive/yolov4/obj.names ./data
!cp /content/drive/MyDrive/yolov4/obj.data ./data마찬가지로 names, data 파일도 VM에 올려준다.
12. generate파일 실행
# upload the generate_train.py and generate_test.py script to cloud VM from Google Drive
!cp /content/drive/MyDrive/yolov4/generate_train.py ./
!cp /content/drive/MyDrive/yolov4/generate_test.py ./
!python generate_train.py
!python generate_test.py이 실행 결과
test.txt, train.txt는
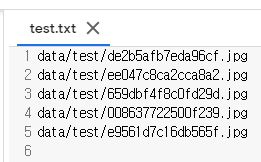
이런식으로 구성되어 있어야 함
13. 이미 학습된 weight 다운받기
경로 cd /content/darknet 로 이동
!wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.conv.137다운받은 파일은 다크넷 폴더안에 있어야 함
14. 학습
# train your custom detector! (uncomment %%capture below if you run into memory issues or your Colab is crashing)
# %%capture
!./darknet detector train data/obj.data cfg/yolov4-obj.cfg yolov4.conv.137 -dont_show -map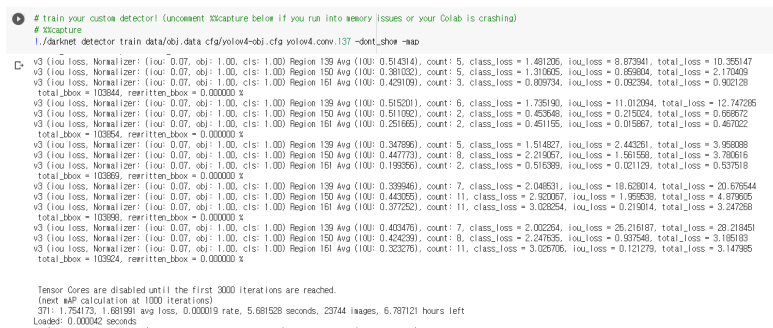
너무 오래걸려서 중간에 멈췄음
이때 /content/drive/MyDrive/yolov4/backup/ 이 경로에
yolov4-obj_last.weights 파일이 생겼는지 확인하고 실행 중단해야 함
15. 결과 확인
에폭당 학습 상태를 확인 가능
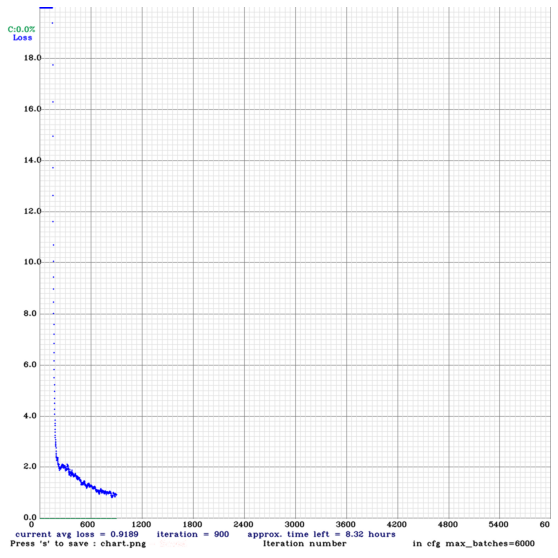
학습을 중간에 멈춰서 이정도이지만, 출처의 링크를 확인하면 전체 결과를 확인할 수 있다.
16. 위에서 만든 last_weights 가중치로 한번 더 학습
이에 더해서, 한번 학습을 마친 가중치를 가지고 학습을 하려면, backup/yolov4-obj_last.weights를 통해 이 가중치 값을 이용해 학습
# kick off training from where it last saved
!./darknet detector train data/obj.data cfg/yolov4-obj.cfg /content/drive/MyDrive/yolov4/backup/yolov4-obj_last.weights -dont_show+) 여기서 추가적으로 여러 weights 파일을 생성한 경우 성능(mAP)를 확인할 수 있는 코드도 있음! 링크 확인
17. 커스텀 모델로 새로운 사진에서 탐지하기
# need to set our custom cfg to test mode
%cd cfg
!sed -i 's/batch=64/batch=1/' yolov4-obj.cfg
!sed -i 's/subdivisions=16/subdivisions=1/' yolov4-obj.cfg
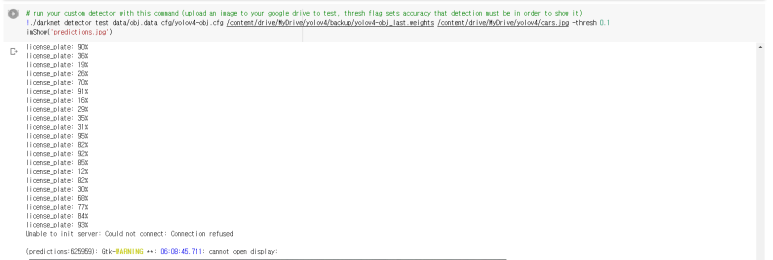
%cd ..# run your custom detector with this command (upload an image to your google drive to test, thresh flag sets accuracy that detection must be in order to show it)
!./darknet detector test data/obj.data cfg/yolov4-obj.cfg /content/drive/MyDrive/yolov4/backup/yolov4-obj_last.weights /content/drive/MyDrive/yolov4/cars.jpg -thresh 0.1
imShow('predictions.jpg')사전에 /content/drive/MyDrive/yolov4/ 경로에 cars.jpg 사진을 넣어두었다.
실행 결과


혹시 학습을 중간에 멈춰서 이정도이지만, 출처의 링크를 확인하면 전체 결과를 확인할 수 있다
라고 하셨는데 어떤 코드 넣으셨는지 알려주실수 있을까요?