
INDEX 가 뭔지 알아보자
디비에 있는 데이터를 조회할 땐 기본적으로 모든 데이터를 조회한다.
예를 들어 이름과 나이가 있는 테이블이 있다.
여기서 나이가 20살인 데이터를 찾으려면 모든 데이터를 조회하는데 만약 1억개의 데이터가 있으면 매우 오래 걸릴 것이다.
이 때 데이터를 빠르고 효율적으로 검색하기 위해 사용하는게 인덱스이다.
인덱스란?
특정 칼럼에서 데이터를 빠르게 찾고 싶다면, 칼럼을 복사하여 미리 정렬을 해놓으면 된다. 이렇게 복사하여 정렬해 둔 칼럼을 인덱스라고 한다.
1~100까지 숫자 중 1개의 숫자를 맞추는 게임을 예로 들어보자
1~100까지 순서대로 물어보면 총 100번의 질문을 해야 답을 맞출 수 있다.
하지만 50 보다 큰지, 75보다 큰지 물으면 반씩 숫자를 소거해가면서 정답을 더 빠르게 맞출 수 있다.
이러한 방법처럼 데이터를 절반씩 소거하면 내가 원하는 데이터를 빠르게 찾을 수 있다. 단 1~100까지 숫자를 정렬해 놓았듯이 데이터도 정렬을 해놔야 한다.
인덱스 구현
데이터베이스는 트리 형태로 데이터를 정렬해 놓는다.
 이렇게 간편하게 데이터를 배치해 놓으면 2번의 질문으로 5를 찾을 수 있다.
이렇게 간편하게 데이터를 배치해 놓으면 2번의 질문으로 5를 찾을 수 있다.
이런 형태의 트리를 이진탐색트리(Binary Search Tree) 라고 부른다.
여기서 성능을 좀 더 개선해보자
저 데이터가 들어간 공간을 노드라고 부르는데, 노드에 데이터를 하나가 아닌 2~3개씩 넣는 것이다.
이렇게 되면 데이터를 반씩 소거하는게 아닌 3분의 2씩 소거할 수 있다.
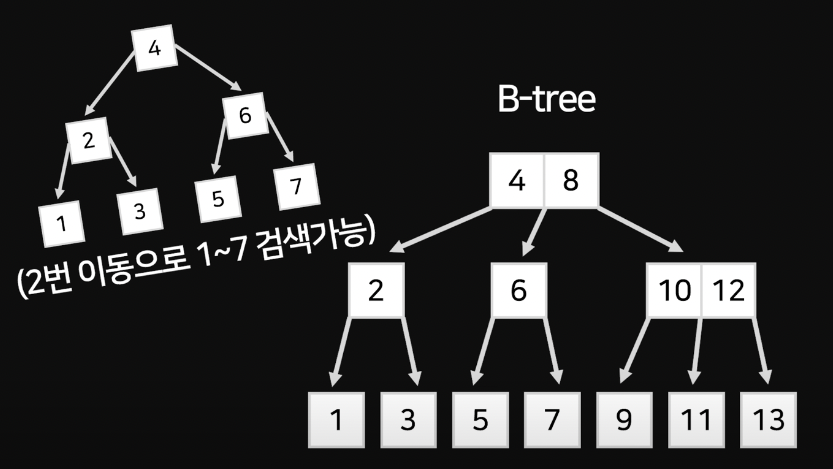 이진탐색트리에선 2번의 질문으로 1~7까지의 데이터만 검색할 수 있었는데, 비트리를 이용하면 13까지 검색할 수 있다.
이진탐색트리에선 2번의 질문으로 1~7까지의 데이터만 검색할 수 있었는데, 비트리를 이용하면 13까지 검색할 수 있다.
이러한 형태의 트리를 B-tree라고 한다.
여기서 성능을 더 향상시킨 형태를 B+tree라고 한다.
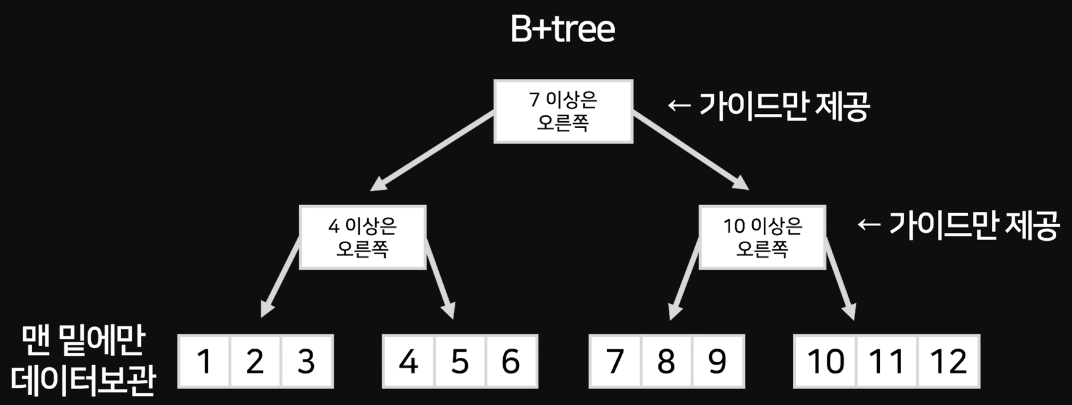 위와 같이 데이터는 가장 아래 노드에 보관하고 상위 노드는 데이터 조회 가이드 라인만 제공하는 것이다.
위와 같이 데이터는 가장 아래 노드에 보관하고 상위 노드는 데이터 조회 가이드 라인만 제공하는 것이다.
B+tree와 B-tree의 다른 점은 B+tree 같은 경우 데이터가 보관된 가장 아래 노드끼리도 연결되어 있다는 것이다. 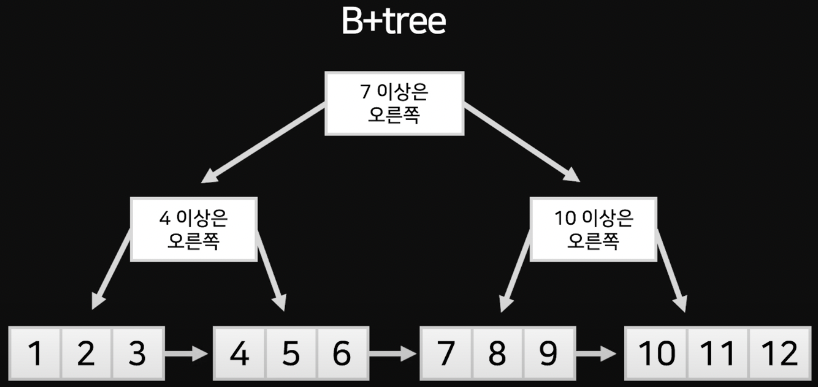 이렇게 자료를 배치해두면 범위 검색이 매우 쉬워진다는 점이다.
이렇게 자료를 배치해두면 범위 검색이 매우 쉬워진다는 점이다.
예를 들어 4~8까지 데이터를 조회해보자
 B-tree에선 4~8을 찾기 위해 여러 노드들을 비효율적으로 움직여야 된다.
B-tree에선 4~8을 찾기 위해 여러 노드들을 비효율적으로 움직여야 된다.
 하지만 B+tree에선 4만 찾은 후 계속 다음 노드로 이동만하면 되니 훨씬 빠르고 간단하게 찾을 수 있다.
하지만 B+tree에선 4만 찾은 후 계속 다음 노드로 이동만하면 되니 훨씬 빠르고 간단하게 찾을 수 있다.
따라서 요즘 데이터베이스에선 B+tree 형태로 인덱스를 생성하는 경우가 많다.
물론 인덱스의 단점도 있다.
인덱스는 원본 테이블의 칼럼을 복사하기 때문에 당연히 디비 용량이 늘어난다.
또한 원본 테이블의 데이터의 삽입이나 수정, 삭제 등이 발생할 때, 인덱스에도 반영해줘야 하기에 성능 하락이 있을 수 있는데 그렇게 크진 않다고 한다.
<참고>
유튜버 코딩애플
