Memory
ConversationBufferMemory
이전 대화 내용 전체를 저장하는 메모리
단점: 대화 내용이 길어질수록 메모리도 증가하여 비효율적
text completion, 예측을 해야할 때, text를 자동완성 하고 싶을 대 유용
※ 메모리 종류와 상관없이 api는 모두 동일
(save_context, load_memory_variables를 가지고 있음)
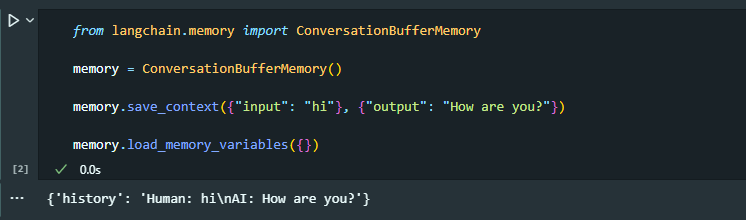 결과가
결과가 string형식으로 출력, 챗모델에서 사용할거라면 부적절
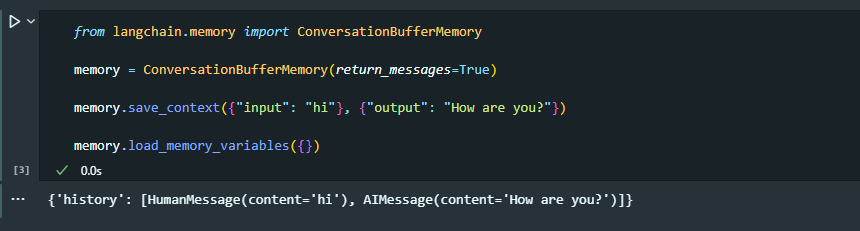
return_messages=True로 챗모델이 사용할 수 있는 형태로 출력
ConversationBufferWindowMemory
대화의 특정부분만을 저장하는 메모리
ex) 5개의 메세지를 저장한다고 가정하면 6번째 메세지를 저장할 때 가장 오래된 메세지를 버리고 최근 5개의 메모리를 저장
장점: 메모리를 특정 크기로 유지할 수 있음, 모든 대화 내용을 저장하지 않아도 됨
단점: 챗봇이 전체 대화가 아닌 최근 대화에 집중하는 것, 예전 대화를 기억하지 못함
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(
return_messages=True, k=4
) # k: 버퍼 윈도우의 사이즈, 몇개의 메세지를 저장할 것인가
def add_message(input, output):
memory.save_context({"input": input}, {"output": output})
add_message(1, 1)
add_message(2, 2)
add_message(3, 3)
add_message(4, 4)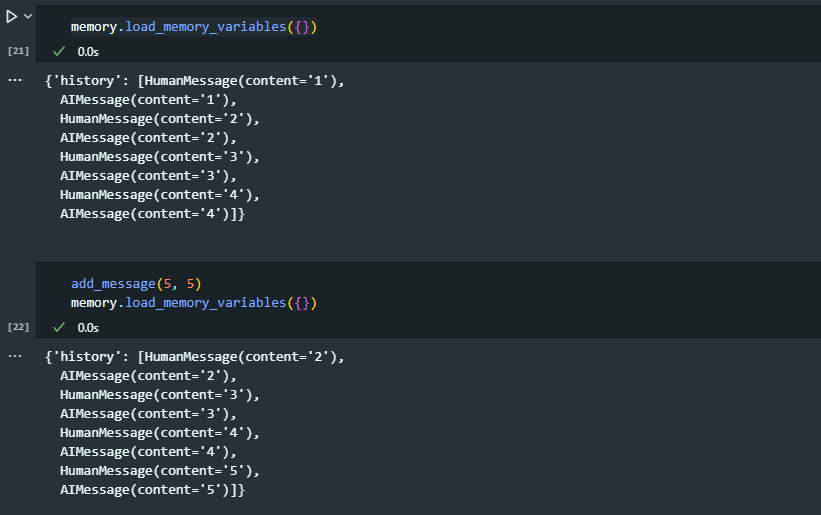
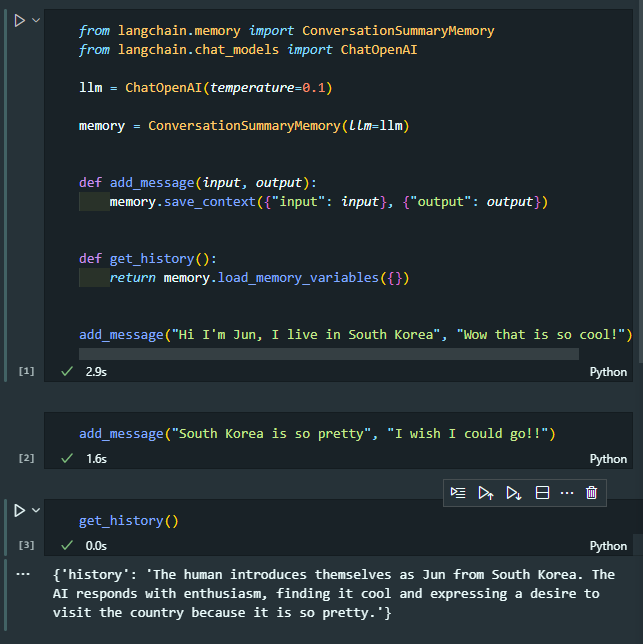
ConversationSummaryMemory
Message를 그대로 저장하는 것이 아니라 Conversation의 요약을 자체적으로 해줌
LLM이 필요함
매우 긴 Conversation이 있는 경우에 유용
초반에는 이전보다 더 많은 토큰과 저장공간을 차지함
Conversation의 메세지가 많아질수록 ConversationSummaryMemory의 도움을 받음
요약하면서 토큰의 양도 줄어듬
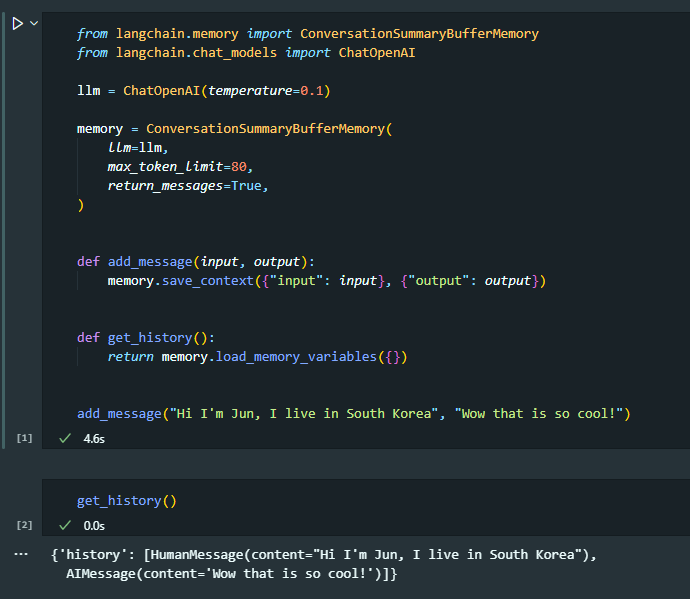
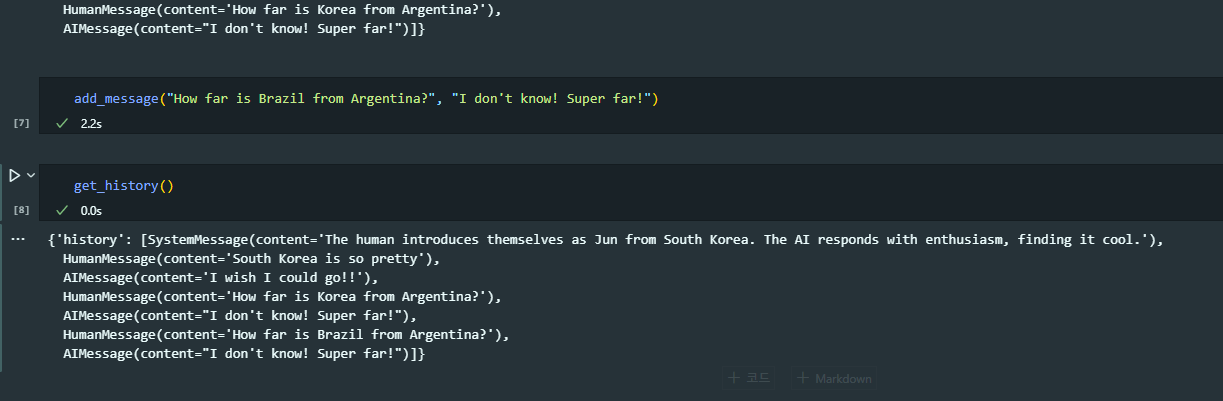
ConversationSummaryBufferMemory
ConversationSummaryMemory, ConversationBufferMemory의 결합
메모리에 보내온 메시지의 수를 저장
사용자가 limit에 다다른 순간에, 무슨 일이 일어났는지 잊어버리는 것 대신 오래된 메시지들을 요약
=> 가장 최근의 상호작용을 계속 추적, 가장 최근 및 가장 오래 전에 주고 받은 메시지를 잊지 않고 요약
. . .
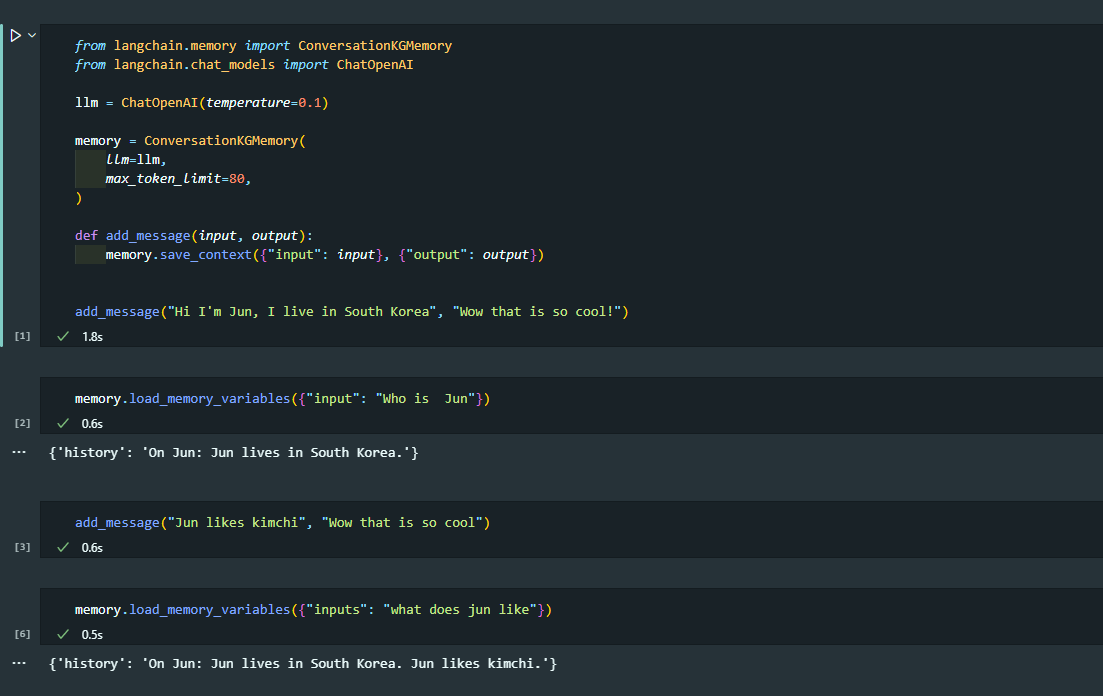
ConversationKGMemory
대화 중의 엔티티의 Kwonledge Graph 생성
가장 중요한 것들만 뽑아내는 요약본