
프로젝트 소개
- kaggle의 영화 제목, 줄거리, 장르 데이터셋을 이용하여 이용자가 입력한 데이터를 기반으로 영화를 추천해주는 시스템을 개발.
https://www.kaggle.com/datasets/hijest/genre-classification-dataset-imdb
데이터 전처리
- 먼저 "title" 데이터의 날짜를 제거한뒤, 전처리를 해줘야하는 칼럼인 "title", "genre", "content"를 모두 합해 "all" 칼럼을 만든 후 자연어처리를 했다.
[문장의 토큰화 및 어간 추출]
- nltk의 WordPunctTokenizer, PorterStemmer사용시 아래와 같이 모든 단어의 끝이 y -> i로, e 또는 s로 끝나면 해당 문자가 생략되는 등의 오류가 발생했다.
Before | After |
|---|
- 따라서 nltk의 word_tokenize와 WordNetLemmatizer을 사용하여 아래와 같이 전처리를 해주었다.

-> WordPunctTokenizer와 word_tokenize의 차이점은 WordPunctTokenizer는 단어와 구두점을 구분하여 토큰화를 하고, word_tokenize는 공백을 기준으로 단어를 분리하여 토큰화를 한다는 것이다.
-> PorterStemmer와 WordNetLemmatizer의 차이점은 PorterStemmer는 단어의 접미사를 제거하여 단어의 원령을 추출하고, WordNetLemmatizer는 사전 형태에 기반한 형태학 분석을 사용해 단어의 원형을 추출한다. 따라서 PorterStemmer가 처리 속도에서는 우수하지만 성능에 있어서는 WordNetLemmatizer가 우수하다.
[불용어 처리]
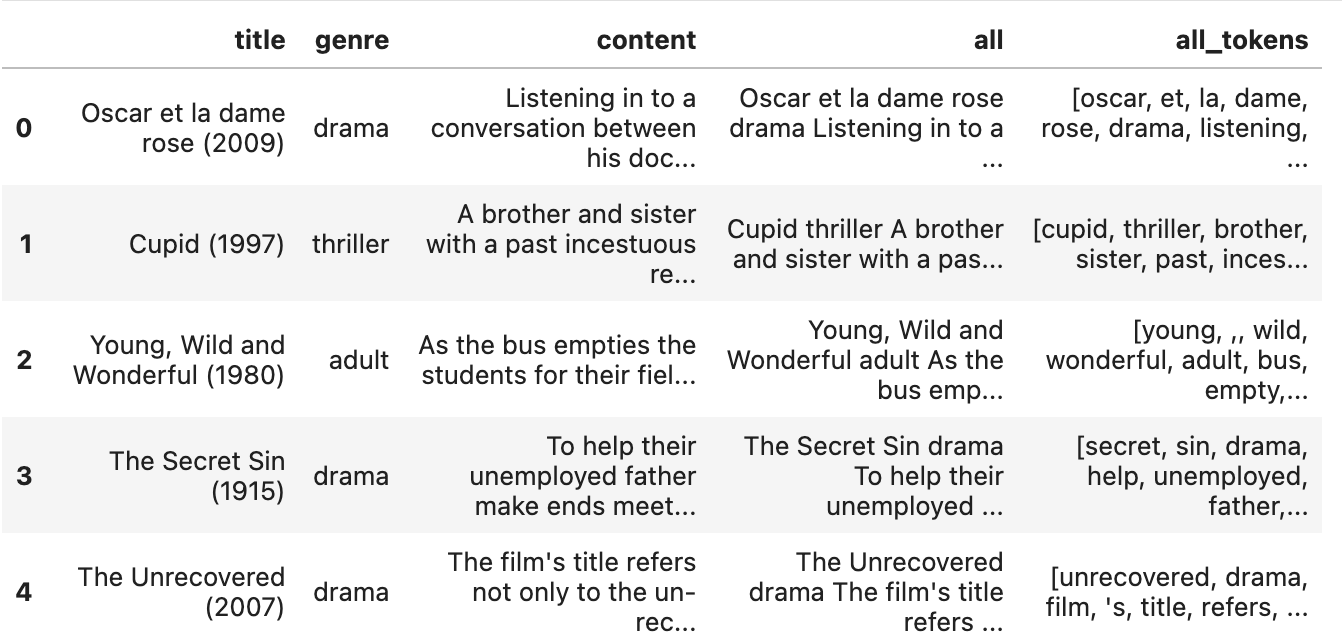
- stopwords를 사용해서 불용어를 제거한 후 "all_tokens" 칼럼을 생성하여 넣어주었다.
영화 추천 모델링
- 아래의 코드를 사용해서 영화를 추천해주는 시스템을 만들었다.
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
df['all_tokens'] = df['all_tokens'].apply(lambda tokens: ' '.join(tokens))
# Vectorize the 'all_tokens' column
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(df['all_tokens'])
tfidf_csr_matrix = tfidf_matrix.tocsr()
# Define the tfidf_search function
def tfidf_search(query, k=5):
query_csr_matrix = tfidf_vectorizer.transform([query])
similarities = cosine_similarity(query_csr_matrix, tfidf_csr_matrix).flatten()
top_similarities = sorted(similarities, reverse=True)[:k]
top_indices = similarities.argsort()[-k:][::-1]
top_titles = [df.iloc[i]['title'] for i in top_indices]
for top_title, top_similarity in zip(top_titles, top_similarities):
print(round(top_similarity, 4), top_title)- 사용자의 요청에 따른 영화 추천 결과는 다음과 같다.
[Please recommend a Christmas movie.]
[computer]
[coffee]
한계점 및 개선방향
- 복수형으로 문장을 만들어서 요청하면 단수형과 다른 단어로 인식하기 때문에 제대로된 결과가 출력되지 않는 것이 아쉬웠다.

💻🐜💡