
프로젝트를 해오면서 Spring Data JPA와 JPA를 진득하게 써왔지만 대체 어떻게 돌아가는건지, 원리는 뭔지 제대로 파악하지도 못했으면서 사용하니까 익셉션이나 원하는 결과가 나오지 않았을때 대처하기가 어렵다. 그래서 JPA의 원리와 개념을 정확히 파악하는 것은 중요하다.
이번에는 공부하다가 중요한 원리라고 생각한 것들을 모아두기위해 작성한 포스팅이다.
Proxy 객체
1. 너 정체가 뭐야..

아래는 User라는 엔티티와 일대다 / 다대일 관계로 매핑되어있는 게시글의 Entity라고 한다면, 아마 대부분 아래와 같이 적을 것이다. 중요하게 볼 부분은 User의 fetch 타입을 LAZY(지연로딩)로 설정해둔 것 이다.
@Entity
.
.
public class Board extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "content_id")
private Long id;
@Column(nullable = false)
private String content;
.
.
.
// 게시물을 작성자
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user;
}
그리고 해당 엔티티를 조회하기 위해 아래와 같은 쿼리가 나간다고 생각해보자. 아래는 QueryDSL의 예시이다.
@Override
public Optional<Board> findByBoardDetail(Long boardId) {
Board result = queryFactory
.selectFrom(board)
.where(board.id.eq(boardId))
.fetchOne();
return Optional.ofNullable(result);
}또는 아래와 같은 Spring Data JPA의 메서드 쿼리를 날린다고 가정하자.
boardRepository.findById()해당 쿼리로 반환된 Board 객체(Optional에서 get 하였다고 가정)에서 User를 꺼내려한다고 생각해보자. 엥 그러면 쿼리를 날린 시점에서 User가 조회될까?
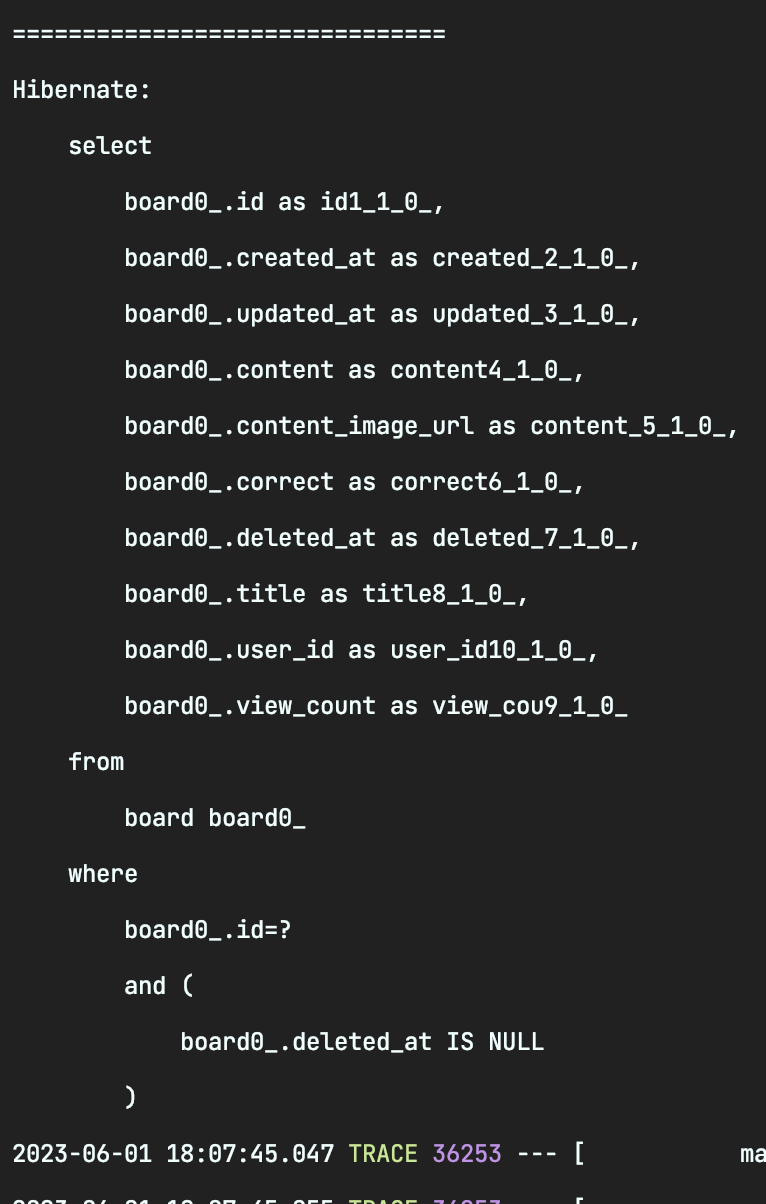
User를 조회하지 않았다. 이는 역시 User의 fetch 타입을 Lazy로 설정해두었기 때문인데, 그러면 여기서 생각해보자. 우리가 여기서 가져온 게시글에 .getUser()를 한다면 당연하게도 그때 User를 조회하는 쿼리를 한번 더 날릴 것 이다.
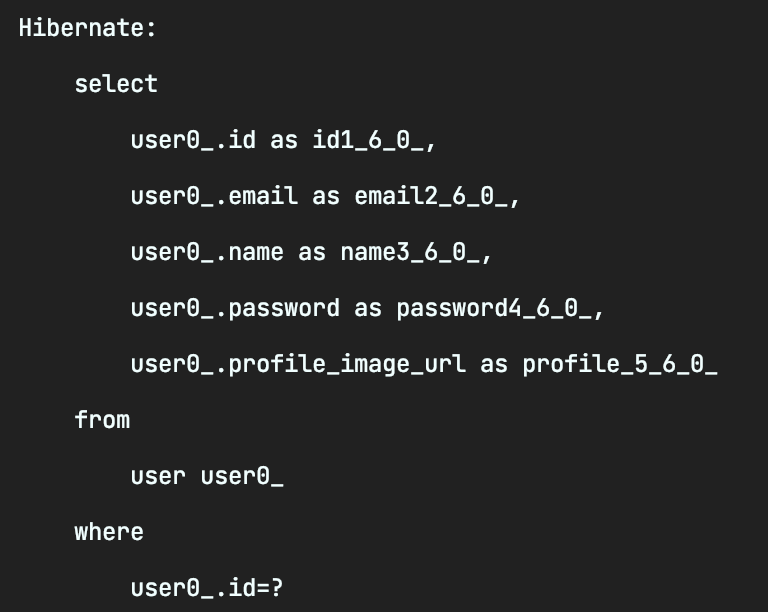
결국은 getUser()를 통해 게시글에서 유저를 조회하는 시점에 쿼리를 한번 더 날리는 것인데 그러면 애초에 처음 Board를 가져왔을때 들어가있는 User 객체의 정체는 뭘까?
2. 프록시 객체
정답은 프록시 객체이다.
💡 프록시 객체는 실제 엔티티 객체를 상속하고, 실제 엔티티와 동일한 인터페이스를 구현하여 동일하게 동작하는데 즉 실제 객체가 아닌 참조 객체이다.
Board가 조회됐을때 JPA는 User 라는 프록시 객체를 생성해두었고 우리가 해당 User를 호출하는 시점 (예를들면 getUser()와 같은 경우) 에 실제 엔티티를 데이터베이스로부터 로드하고, 해당 엔티티를 영속성 컨텍스트에 저장한 후 컨텍스트에서 해당 엔티티의 데이터를 가져온다. 그리고 이 과정을 프록시 객체를 초기화라고 한다.
프록시 객체는 엔티티를 지연로딩 하기 위해 사용되는 기술이며 지연로딩을 이해하기 위해 필수적인 지식이라고 생각한다.
⚠️ 프록시 객체를 사용할때 영속성 컨텍스트의 초기화, 밖에서 사용되면 LazyInitializationException 이 터지게 되니 생명주기를 잘 관리해주어야 한다.
프록시 객체를 이용한 지연로딩은 만능처럼 보이기도 하지만, 성능 문제를 야기하는 주범이기도 한다. 만약 Board 라는 엔티티가 여러 관계를 매핑하고 그에 관한 모든 정보를 가져온다고 했을때 지연로딩을 하게되면 지연로딩의 특성상 필요한 시점에 새로운 쿼리를 하나씩 생성하기 때문에 하나를 조회했는데 여러개의 쿼리가 나가게 되고 그것을..
3. 지연로딩의 N + 1 문제

N + 1 문제라고 한다. 위에서 말했든 우린 분명 Board를 조회하기 위해 쿼리를 하나 생성시켰는데, 그 이후에 그와 연관된 쿼리들이 N 만큼 생성된다는 것 이다. 이 부분은 성능에 매우매우 중요한 영향을 미치기 때문에 추후 포스팅에서 N + 1 문제를 해결하는 방법에 대해 작성하도록 하겠다.
N + 1 문제가 지연로딩의 가장 대표적엔 성능 이슈이다.
2. cascade는 외톨이 입니다,,

@ManyToOne과 @OneToMany와 같이 연관관계를 매핑하다보면 cascade 속성을 사용할때가 있는데 이 경우 매핑관계에 영향이 있거나 미칠 수 있다고 생각할 수 있겠지만, 사실 전혀 관계가 없습니다. cascade 속성은 독립적이라고 볼 수 있는데 단순히 데이터를 한번에 저장 시킬 수 있냐에 초점이 맞춰진거지 연관관계의 매핑과는 전혀 관련이 없다는 것을 알고있어야 한다.
@OneToMany(mappedBy = "board", cascade = CascadeType.ALL)
private List<Like> like = new ArrayList<>();위와같이 영속성전이를 통해 연쇄적으로 데이터가 저장될 수 있게끔 만들어주는 기능이기 때문에 연관관계에 초점을 맞추는 것이 아닌 부모가 자식까지 저장을 할 것 이냐 라는 관점에서 보는 것이 좋다.
그렇지만 cascade는 필수가 아닌 단순한 옵션으로써, 부모가 자식까지 꼭 저장을 해주어야 하는가에 대한 의문을 먼저 품고 충분한 고민 이후에 사용하는 것이 좋다.
그러면 여기서 부모가 자식을 저장과 동시에 삭제까지 영향을 미친다면?
3. Orphan Object (고아객체)
@OneToMany(mappedBy = "board", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Like> like = new ArrayList<>();위의 예제와 동일한 예제에서 orphanRemoval 이라는 옵션을 추가해주었다. 예를 들어 자식의 부모가 제거되면서 연관관계가 끊겼다고 생각하면, 해당 자식은 고아가 된다. 즉 Orphan Obejct가 되는데 이 경우 해당 옵션을 통해 부모가 삭제되면 자식이 함께 삭제되는 옵션이다.
대신 이 기능을 사용할때는 제거되는 자식이 다른 부모에게 영향을 주고있으면 안된다. 즉, 하나의 자식이 하나의 부모에게만 영향을 미칠때 사용해야하고, 생명주기와 관해서도 밀접한 영향을 미치기 때문에 해당 옵션은 주의해서 사용해야 한다.
4. 당신의 건강을 위해 OneToMany 하세요

만약 여러분이 임베디드 타입의 값타입 컬렉션을 사용하고자 아래와 같이 엔티티에 추가했다고 가정해봅시다.
@ElementCollection
@CollectionTable(
name = "hint",
joinColumns = @JoinColumn(name = "board_id")
)
List<hint> hints = new ArrayList<>();근데 잘 생각해보면 위와 같은 구조는 oneToMany로 만들기 아주 좋아 보인다. 그럼에도 불구하고 컬렉션을 사용하려 한다면 "아니 oneToMany 하면 또 Join 해야되고 한번에 관리해주는게 성능에 좋죵!!" 이라고 할 수 있지만 위 임베디드 값타입 컬렉션의 아주 치명적인 점을 설명해주겠다.
1. 아니 대체 어디로 간겨
값타입은 엔티티와 다르게 식별자가 없다. 그렇다는 말은 대체 누가 누군지 모른다는 거다. 만약에 어떠한 힌트가 수정되었는데 수정된 힌트가 뭔지를 알 수가 없다.
우리가 할 수 있는건 인덱스의 번호로 꺼내올 수 있는데, 수정된 힌트가 대체 몇번째 인덱스에 있는지 알 수 있을까? 찾을 수가 없다.
그러면 억지로 대충 힌트 하나 넣어줄때 힌트_id 라는 값을 임의로 하나 만들어서 넣어두면 어찌어찌 해결할 수는 있겠지만 그럴빠엔 그냥 oneToMany로 연결시켜주자.
2. 싹 다 갈아엎어주세요

위에 문제는 어찌어찌 해결해서 값타입 컬렉션을 사용해서 여러개의 힌트가 저장해둔 게시글이 있다고 생각해보자. 여기서 나는 27번의 힌트를 수정하고자 27번의 객체를 꾸역꾸역 다 써놓고 remove시키고 27번의 힌트를 재정의해서 새로 add 해주었는데 이게 왠걸, list가 전부 제거되고 이미 존재하던 리스트가 전부 다시 insert 됐다.
즉 데이터를 수정하려면 해당 컬렉션의 데이터가 모두 제거되고 추가된 데이터를 포함해서 제거된 데이터들이 전부 다시 insert 된다.. 말도 안되는 성능 이슈가 발생하기에.. 그냥.. 일대다 : 다대일 관계로 엔티티를 만들자 ^-^
Spring data Jpa 를 사용하기전 JPA 부터 제대로 알고 사용해야 한다는 것을 이번에 JPA를 공부하면서 뼈저리게 느꼈다. 결국은 기본적인 SQL이 탄탄해야 하겠지만 JPA를 사용하고 JPQL을 이용한 쿼리 등을 만들어보면서 내가 현재 부족했던 것들을 알차게 잘 채운것 같다.
테스트 코드를 돌리면서 findById를 해도 하이버네이트 로그가 찍히지 않아서 아니 이거 왜이래 이랬었는데 테스트에서 save하는 코드에서 이미 영속성 컨텍스트에 관리되기 시작해서 아무리 find해도 쿼리를 안날리기때문에 하이버네이트 로그가 없는 것 이였다. 그것도 모른채 속도를 비교하고 있던 나(...)
아무튼 오늘은 JPA를 공부하다가 약간 중요하다고 생각된 것들을 그냥 풀어보았다. 다음 포스팅에서는 N + 1 문제에 대해 다루어보도록 하겠다.
