
데이터베이스 기본
데이터베이스 기본
'데이터베이스(DB, Database)'는 일정한 규칙이나 규약을 통해 구조화되어 저장되는 데이터의 모음이다. 해당 데이터베이스를 제어, 관리하는 통합 시스템을 'DBMS(DataBase Management System)'라고 부른다. 데이터베이스 안에 있는 데이터들은 특정 DBMS마다 정의된 쿼리 언어(query language)를 통해 삽입, 삭제, 수정, 조회 등을 수행하게 된다. 또한, 데이터베이스는 실시간 접근과 동시 공유가 가능하다.
데이터베이스 위에 DBMS가 있고, 그 위에 응용 프로그램이 있는 구조를 기반으로 데이터를 주고 받게 된다. 만약, MySQL이라는 DBMS가 있고, 그 위에 응용 프로그램에 속하는 Java 등에서 해당 데이터베이스 안에 있는 데이터를 끄집어내 해당 데이터 관련 로직을 구축하게 되는 것이다.
엔터티
엔터티
'엔터티(entity)'는 사람, 장소, 등의 여러 개의 속성을 지닌 명사를 의미한다. 가족이라는 엔터티가 있다고 해보면 이름, 아이디, 주소, 전화번호 등의 속성을 가질 수 있을 것이다.
이러한 속성은 서비스의 요구 사항에 맞춰 정해진다.
약한 엔터티와 강한 엔터티
엔터티는 '약한 엔터티'와 '강한 엔터티'로 나뉜다. 만약 A는 혼자서 존재하지 못하고, B의 존재 여부에 따라 종속적으로 존재한다면, A는 약한 엔터티이고, B는 강한 엔터티이다.
자식은 부모님이 존재해야 존재할 수 있다. 따라서 자식은 약한 엔터티라고 할 수 있고, 부모는 강한 엔터티라고 할 수 있을 것이다.
릴레이션
릴레이션
'릴레이션(relation)'은, 데이터베이스에서 정보를 구분하여 저장하는 기본 단위이다. 엔터티에 관한 데이터를 데이터베이스는 릴레이션 하나에 담아서 관리하게 된다.
릴레이션은 관계형 데이터베이스에서는 '테이블' 이라고 하고, NoSQL 데이터베이스에서는 '컬렉션'이라고 한다.
테이블과 컬렉션
데이터베이스의 종류는 크게 관계형 데이터베이스와 NoSQL 데이터베이스로 나눌 수 있다. 대표적인 관계형 데이터베이스인 MySQL과 대표적인 NoSQL 데이터베이스인 MongoDB를 예로 들면, MySQL의 구조는 '레코드-테이블-데이터베이스'로 이루어져 있고, MongoDB 데이터베이스의 구조는 '도큐먼트-컬렉션-데이터베이스'로 이루어져 있다.
즉, 레코드가 쌓여서 테이블이 되고, 테이블이 쌓여서 데이터베이스가 되는 것이다.
속성
속성
'속성(attribute)'은, 릴레이션에서 관리하는 구체적이며 고유한 이름을 갖는 정보이다. 만약 '컴퓨터'라는 엔터티의 속성을 뽑아본다면, 모니터 종류, 마우스 종류, cpu 종류 등이 있을 것이다. 이 중에서 서비스 요구 사항을 기반으로 관리해야 할 필요가 있는 속성들만이 엔터티의 속성이 되는 것이다.
도메인
'도메인(domain)'은, 릴레이션에 포함된 각각의 속성들이 가질 수 있는 값의 집합이다. 만약 '성별'이라는 속성이 있다면, 이 속성이 가지는 값은 {남자, 여자}가 될 것이다.
정리해서 예로 들어보자면,
'회원'이라는 릴레이션에 이름, 아이디, 주소, 전화번호, 성별이라는 속성이 있을 수 있고, 성별은 {남, 여}라는 도메인을 가질 수 있다는 것이다.
필드와 레코드
필드와 레코드
위에 설명한 것들을 기반으로 데이터베이스에서는 '필드'와 '레코드'로 구성된 테이블을 만들게 된다.
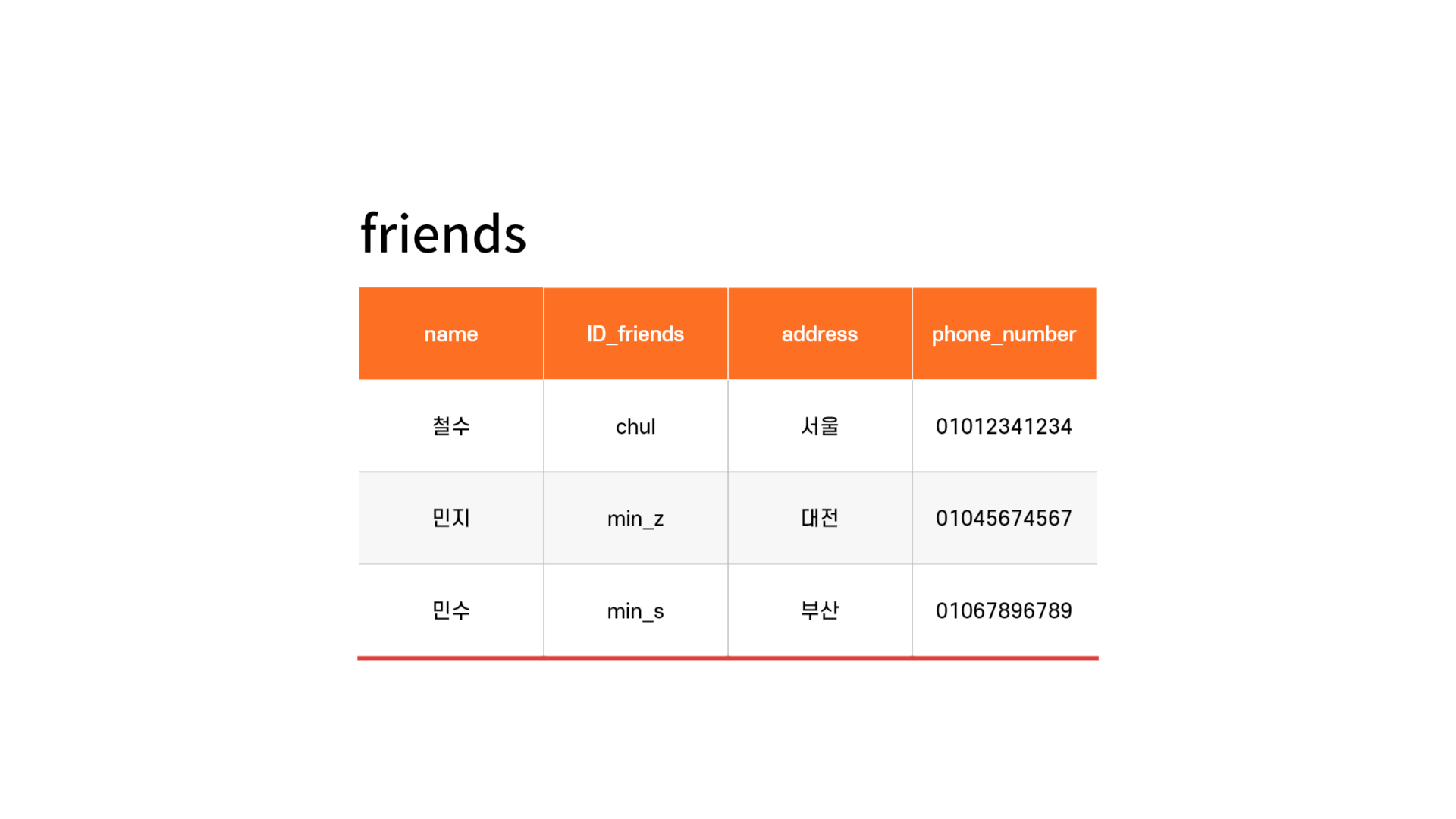
친구란 엔터티는 friends라는 테이블로, 속성인 이름, 아이디 등을 가지고 있고, name, ID_friends, address 등의 필드를 가지게 된다. 그리고 이 테이블에 쌓이는 행(row) 단위의 데이터를 레코드라고 한다. 레코드를 '튜플'이라고도 한다.
엔터티를 데이터베이스에 넣어 테이블로 만들려면 어떻게 해야할까? 속성에 맞는 타입을 정의해야 한다. 참고로 타입은 데이터베이스마다 조금씩 차이가 있다. MySQL 기준으로는 아래와 같이 만들 수 있다.
CREATE TABLE friends(
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(255),
address VARCHAR(255),
ID_friends carchar(255)
phone_number INT,
PRIMARY KEY (id)
;
)한글을 속성 이름으로 쓰지는 않는다. name, address 등으로 영어 이름에 매핑해서 쓰게 된다.
필드 타입
필드는 타입을 갖는다. 이름은 문자열이고, 전화번호는 숫자가 타입일 것이다. 이러한 타입들은 DBMS마다 다르다. 설명을 위해 MySQL을 기준으로 설명해보면, 아래와 같다.
숫자 타입
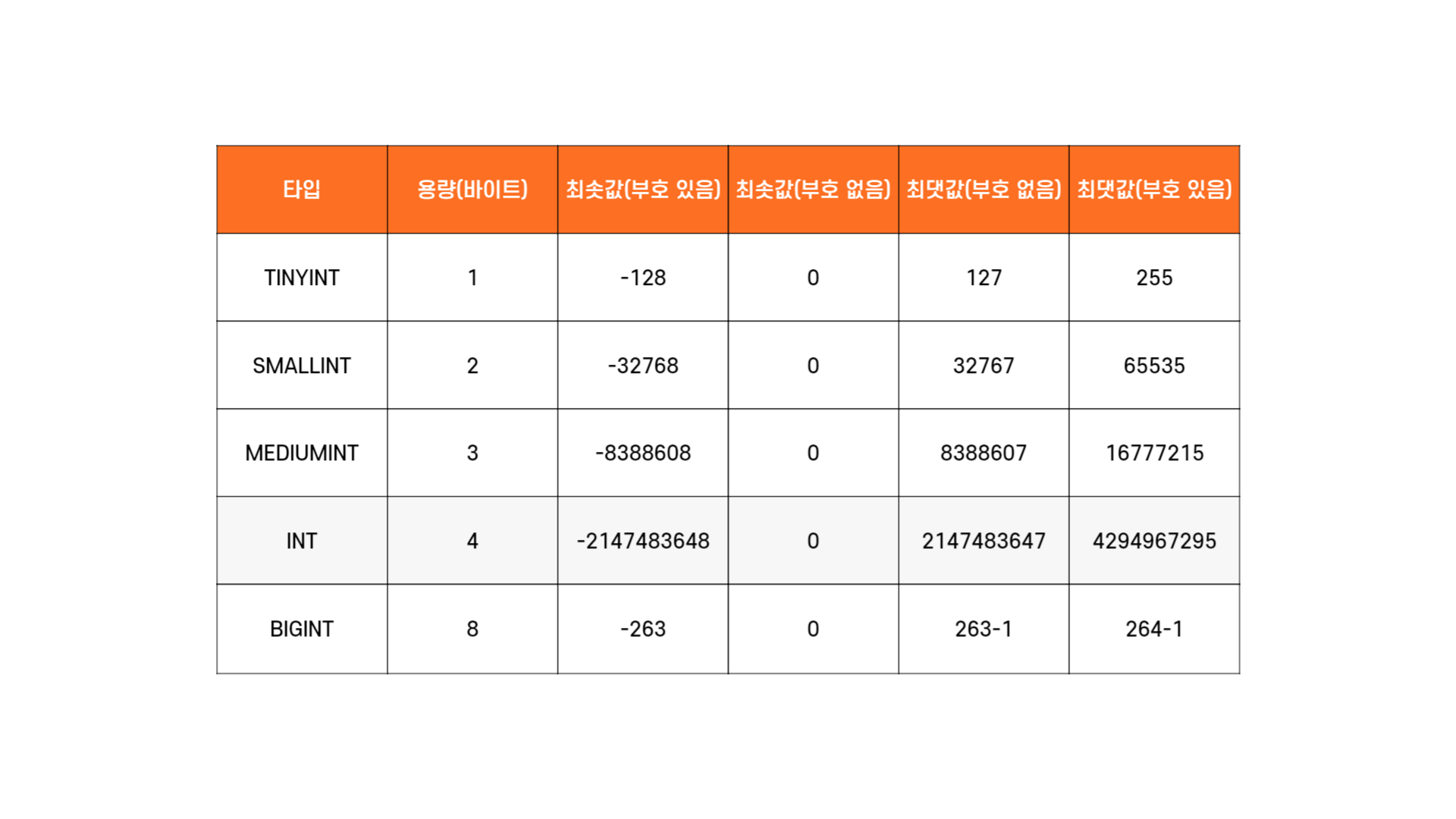
숫자 타입으로는 TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT 등이 있다.
아래 참고!
날짜 타입
날짜 타입으로는 DATA, DATETIME, TIMESTAMP 등이 있다.
- DATE
날짜 부분은 있지만, 시간 부분은 없는 값에 사용된다. 지원되는 범위는 1000-01-01~9999-12-31 이다. 3바이트의 용량을 가진다.
- DATETIME
날짜 및 시간 부분을 모두 포함하는 값에 사용된다. 지원되는 범위는 1000-01-01 00:00:00 에서 9999-12-31 23:59:59 DLEK. 8바이트의 용량을 가진다.
- TIMESTAMP
날짜 및 시간 부분을 모두 포함하는 값에 사용된다. 1970-01-01 00:00:01 에서 2038-01-19 03:14:07 까지 지원한다. 4바이트의 용량을 가진다.
문자 타입
문자 타입으로는 CHAR, VARCHAR, TEXT, BLOB, ENUM, SET이 있다.
- CHAR와 VARCHAR
CHAR 또는 VARCHAR 모두 그 안에 수를 입력해서 몇 자까지 입력할지 정하게 된다. 만약 CHAR(30)이라면 최대 30글자까지 입력할 수 있다.
CHAR는 고정 길이 문자열이고, 길이는 0에서 255 사이의 값을 가진다. 레코드를 저장할 때 무조건 선언한 길이 값으로 '고정'해서 저장된다. 만약 CHAR(100)으로 선언하고 10글자를 저장해도 100바이트로 저장되는 것이다.
VARCHAR는 가변 길이 문자열이다. 길이는 0에서 65,535 사이의 값으로 지정할 수 있고, 입력된 데이터에 따라 용량을 가변시켜 저장한다. 만약 10글자의 이메일을 저장할 경우 10글자에 해당하는 바이트 + 길이기록용 1바이트로 저장하게 된다. VARCHAR(1000)으로 선언해도 말이다.
따라서 CHAR의 경우에는 유동적이지 않은 길이를 가진 데이터의 경우에 효율적이고, 유동적인 길이를 가진 데이터는 VARCHAR로 저장하는 것이 좋다.
- TEXT와 BLOB
이 2개의 타입은 큰 데이터를 저장할 때 쓰는 타입이다.
TEXT는 큰 문자열 저장에 쓰이고, 주로 게시판의 본문을 저장할 때 쓰인다.
BLOB는 이미지, 동영상 등 큰 데이터 저장에 쓰인다. 보통은 아마존의 미지 호스팅 서비스인 S3를 이용하는 등, 서버에 파일을 올리고, 파일에 관한 경로를 VARCHAR로 저장한다.
- ENUM과 SET
ENUM과 SET은 모두 문자열을 열거한 타입이다.
ENUM은 ENUM('x-small', 'small', 'medium', 'large', 'x-large)형태로 쓰이고, 이 중에서 하나만 선택하는 단일 선택만 가능하며, ENUM 리스트에 없는 잘못된 값을 삽입하면 빈 ㅂ문자열이 대신 삽입된다. ENUM을 이용하면 x-small 등이 0,1 등으로 매핑되어 메모리를 적게 사용하는 이점을 얻는다. ENUM은 최대 65,535개의 요소들을 넣을 수 있다.
SET은 ENUM과 비슷하지만, 여러 개의 데이터를 선택할 수 있고, 비트 단위의 연산을 할 수 있으며, 최대 64개의 요소를 집어넣을 수 있다는 점이 다르다.
참고로 ENUM이나 SET을 쓸 경우, 공간적으로 이점을 볼 수 있지만, 애플리케이션의 수정에 따라 데이터베이스의 ENUM이나 SET에서 정의한 목록을 수정해야하는 단점이 있다.
관계
데이터베이스에 테이블이 하나만 있는 것은 아니다. 여러 개의 테이블이 있고, 테이블은 서로의 관계가 정의되어 있다. 이러한 관계를 '관계화살표'로 나타낸다.
1:1 관계

회원이 하나만 이메일을 가질 수 있다면, 1:1 관계가 된다.
1:1관계는 테이블을 두 개의 테이블로 나눠, 테이블의 구조를 이해하기 쉽게 만든다.
1:N 관계
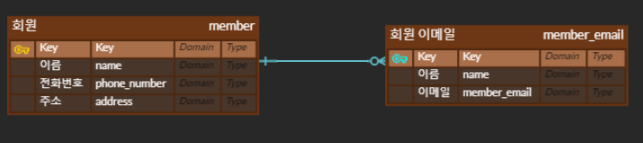
회원 당 여러 이메일을 가질 수 있다면, 1:N 관계가 된다. 하나도 없을 수도 있다면! 위 그림과 같이 0도 포함되는 화살표를 통해 표현해야 한다.
즉, 한 개체가 다른 많은 개체를 포함하는 관계를 말한다.
N:M 관계
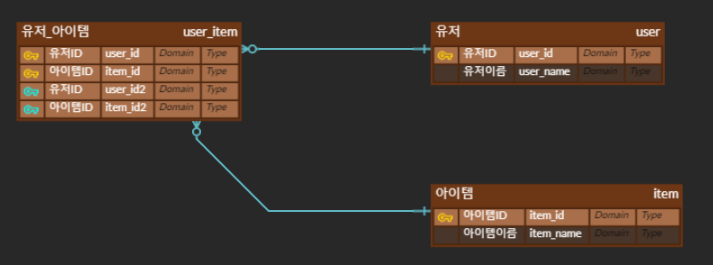
유저와 아이템 관계를 정의하면 위와 같을 수 있다. 유저도 아이템을 여러 개 가질 수 있고, 한 개의 아이템을 여러 유저가 가질 수 있을 것이다. 이런 경우 N:M 관계가 된다.
이럴 때는, 즉, 다대다의 경우일 때는, 위와 같이 유저_아이템이라는 테이블이 중간에 있다. N:M은 테이블 두 개를 직접적으로 연결해서 구축하기보다, 1:N, 1:M 관계를 갖는 테이블 두 개로 나눠 설정한다.
키
키
테이블 간의 관계를 좀 더 명확히 하고, 테이블 자체의 인덱스를 위해 설정된 장치로 기본키, 외래키, 후보키, 슈퍼키, 대체키가 있다.
그림으로 보면 아래와 같다.
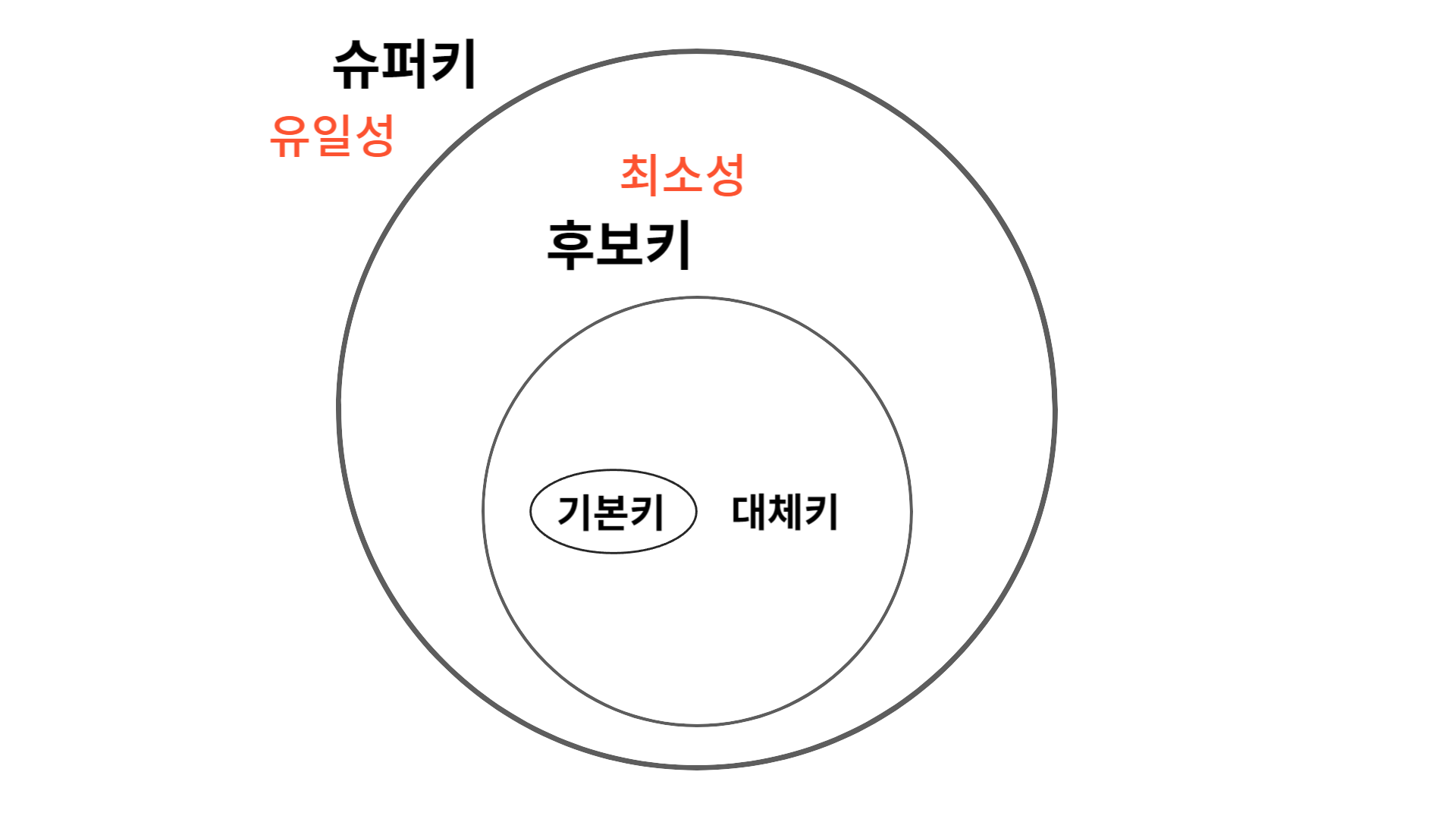
위 그림은 키들의 관계를 표현한 것이다. '슈퍼키'는 유일성이 있고, 그 안에 포함된 '후보키'는 최소성까지 갖춘 키이다. 후보키 중에서 기본키로 선택되지 못한 키는 '대체키'가 된다.
'유일성'은 중복되는 값이 없으며, '최소성'은 필드를 조합하지 않고 최소 필드만 써서 키를 형성할 수 있는 것을 말한다.
기본키
'기본키(Primary Key)'는 줄여서 PK 또는 프라이머리키라고 많이 부른다. 또한, 유일성과 최소성을 만족하는 키이다.
테이블의 데이터 중 고유하게 존재하는 속성이며, 기본키에 해당하는 데이터는 중복되어서는 안된다.
{ID, nickname} 이라는 복합키를 기본키로 설정할 수는 있지만, 이렇게되면 최소성을 만족하지 않는다.
기본키는 '자연키' 또는 '인조키' 중에 골라서 설정한다.
자연키
만약 User 테이블을 만든다고 할 때, 그 안에는 주민등록번호, 이름, 성별 등의 속성이 들어갈 수 있다.이 중에 이름, 설별 등은 중복된 값이 들어올 수 있어 부적절하고, 남는 것은 주민등록번호이다.
이렇듯, 중복된 값들을 제외하며 중복되지 않는 것을 '자연스럽게' 뽑다가 나오는 키를 '자연키'라고 한다. 다만 자연키는 언젠가는 변하는 속성을 지닌다.
인조키
이번에도 User 테이블을 만든다고 했을 때, 회원 테이블을 생성한다고 가정하면, 주민등록번호, 이름, 성별 등의 속성이 있을 것이다. 여기에 인위적으로 user_id를 부여하는 것이다. 이를 통해 고유 식별자가 생겨난다. 오라클은 sequence, MySQL auto increment 등과 같이 설정한다. 이렇게 인위적으로 생성한 키를 '인조키'라고 한다.
자연키와는 대조적으로 변하지 않는다. 따라서 보통 기본키는 인조키로 설정하게 된다.
외래키
'외래키(Foreign Key)'는 FK라고도 하며, 다른 테이블의 기본키를 그대로 참조하는 값으로 개체와의 관계를 식별하는 데 사용한다.
또한, 외래키는 중복되어도 괜찮다.
후보키
'후보키(candidate key)'는 기본키가 될 수 있는 후보들이며, 유일성과 최소성을 동시에 만족하는 키이다.
대체키
'대체키(alternate key)'는 후보키가 두 개 이상일 경우, 어느 하나를 기본키로 지정하고 남은 후보키를 말한다.
슈퍼키
'슈퍼키(super key)'는 각 레코드를 유일하게 식별할 수 있는 유일성을 갖춘 키이다.
