
MongoDB
MongoDB란?
- MongoDB는 C++로 작성된 오픈소스 문서지향(Document-Oriented)적 Cross-platform 데이터베이스이며 뛰어난 확장성과 성능을 자랑
- 또한, 현존하는 NoSQL 데이터베이스 중 인지도 1위를 유지하고 있음
- 대중적으로 많이 알려져 사용되고 있는 MySQL은 RDBMS(Relational DataBase Management System)
- 이 때, MySQL은 대표적으로 SQL(Structured Query Language)을 사용
- SQL은 관계형 데이터베이스의 기본이며 이 둘을 혼용하여 사용하는 경우도 다분
- SQL의 가장 대표적인 특징은 바로, 정형화된 형태(Structure)
- SQL은 정해진 DB 내부에 정해진 Table만을 사용하여 데이터를 불러오거나 저장, 수정, 삭제 등을 수행
- 반대로 MongDB는 대표적인 NoSQL
- NoSQL이라는 의미는 "관계형 데이터베이스가 아니다"라는 의미
- 위의 SQL과는 다른 개념을 사용하며 정형적이지 않은 형태를 취하는 데이터베이스
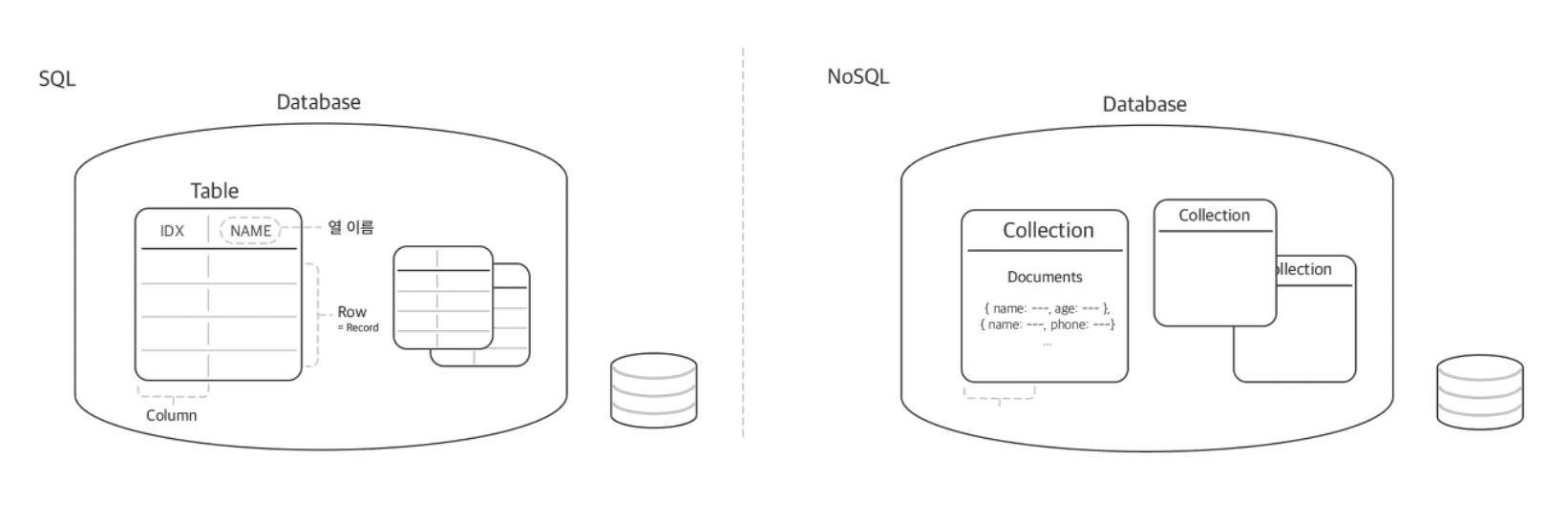
- SQL에서는 데이터베이스 내에 정확한 구조가 있음
- 마치 의미가 분명한 엑셀에 해당하는 데이터를 적어두는 느낌
- Table 내부에 Row와 Column의 정형화된 형태로 해당 칸이 의미하는 데이터(Record)들이 기록됨
- 중요한 점은, SQL에서는 관계(Relationship)를 통해 데이터들이 연결되어 있다는 점
- 주로 서로 다른 테이블에 분산된 데이터가 있을 때 서로의 관계를 통해 연결되어지는데 이 때 주로 인덱스(Index)를 통한 연결이 이어짐
- NoSQL(Not Only SQL)에서는 데이터베이스 내에 정확한 구조가 없음
- 마치 문서에 나름대로 생각한 구조를 적어두는 느낌
- Collection은 SQL에서의 Table과 동일한 의미를 지님- NoSQL은 SQL과는 다르게 관계가 없기 때문에 JOIN이라는 개념이 없음
- NoSQL은 Key 부분의 타입만 동일하고, 생략되지 않는 (Mandatory) 필드로 지정하면 값에 해당 하는 컬럼은 어떤 타입 또는 어떤 이름이 오든 허용됨
- Id 필드는 공통이지만, 데이터를 저장하는 컬럼은 각기 다른 이름과 다른 데이터 타입을 가질 수 있음
- 마치 문서에 나름대로 생각한 구조를 적어두는 느낌
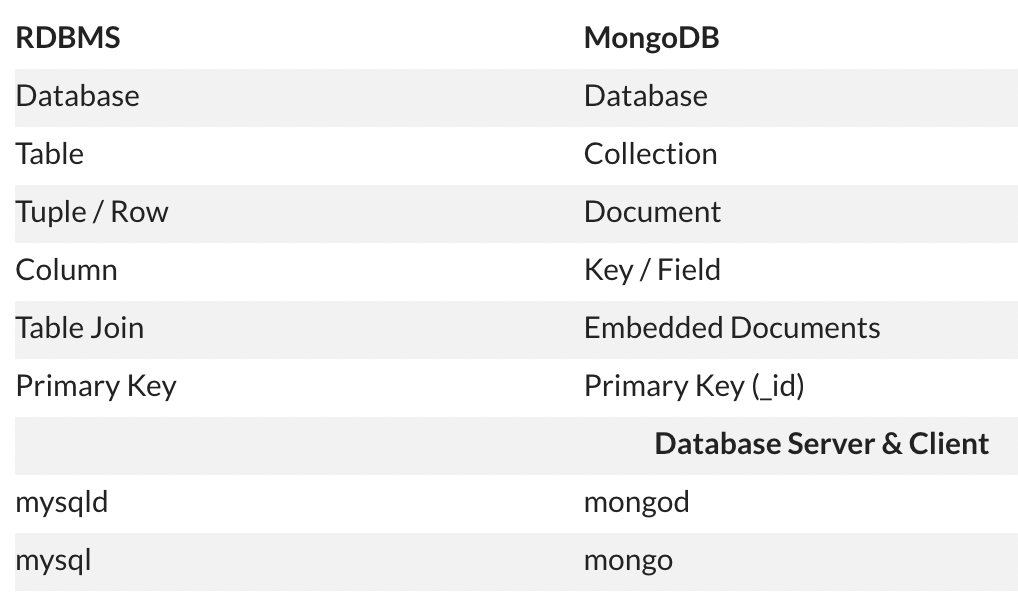
Tip! 추가 자료
Document
- 문서지향(Document-Oriented)적 데이터베이스라는데 여기서 말하는 문서(Document)는 RDMS의 데이터(Record)와 비슷한 개념
- 데이터 구조는 한 개 이상의
key-value로 이뤄져있음
- 데이터 구조는 한 개 이상의
# MongoDB Sample Document
{
"_id": ObjectId("5099803df3f4948bd2f98391"),
"username": "velopert",
"name": { first: "M.J.", last: "Kim" }
}- 여기서
_id,username,name은 key이고 그 오른쪽에 있는 값들은 value_id는 12bytes의 hexadecimal 값으로서, 각 Document의 유일함(Uniqueness)을 제공- 이 값의 첫 4bytes는 현재 timestamp, 다음 3bytes는 machine id, 다음 2bytes는 MongoDB 서버의 process id, 마지막 3bytes는 순차번호로 추가될때마다 값이 높아짐
- Document는 동적(Dynamic) 구조(Schema)를 갖고있음
- 같은 Collection 안에 있는 Document 끼리 다른 구조(Schema)를 갖고 있을 수 있는데, 쉽게 말하면 서로 다른 데이터(=서로 다른 key)들을 가지고 있을 수 있음
Collection
- Collection은 MongoDB Document의 그룹
- Document들이 Collection 내부에 위치하고 있음
- RDMS의 Table과 비슷한 개념이지만 RDMS와 달리 구조(Schema)를 따로 가지고 있지않음
Database
- Database는 Collection들의 물리적인 컨테이너
- 각 Database는 파일시스템에 여러 파일들로 저장됨
NoSQL 데이터 모델링
-
구조(Schema)를 디자인 할 때 고려사항
- 사용자 요구(User Requirement)에 따라 디자인
- 객체들을 함께 사용하게 된다면 한 Document에 합쳐서 사용
- 예시: 게시물-댓글과의 관계
- 그렇지 않으면 따로 사용
- JOIN을 사용하지 않는걸 확실하게 해두기
- 읽을 때 JOIN 하는게 아니라 데이터를 작성할 때 JOIN 사용
-
예제
- 간단한 블로그를 위한 데이터베이스를 디자인한다고 가정
- 요구사항
- 게시글에는 작성자 이름, 제목, 내용이 담겨져 있음
- 각 게시글은 0개 이상의 태그를 가지고 있을 수 있음
- 게시글엔 댓글을 달 수 있으며 댓글은 작성자 이름, 내용, 작성시간을 갖고 있음
- 요구사항
- 간단한 블로그를 위한 데이터베이스를 디자인한다고 가정
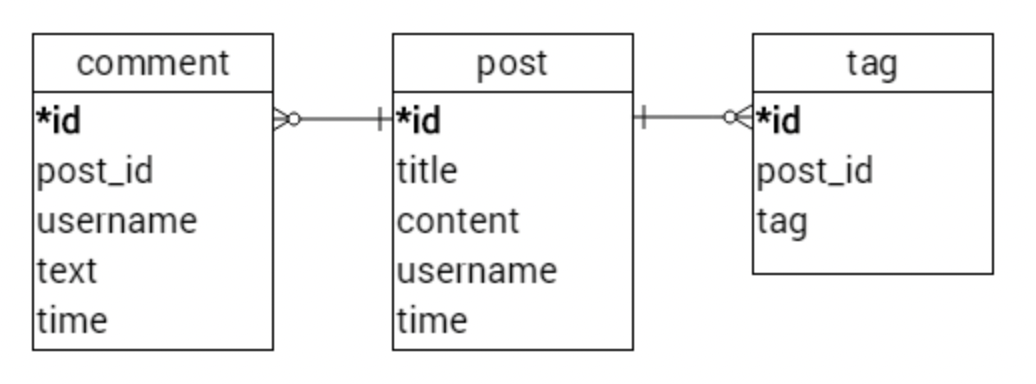
- RDMS라면 이런 식으로 테이블 3개를 만들어야 효율적
- NoSQL에선 모든걸 하나의 Document에 넣음
{
_id: POST_ID,
title: POST_TITLE,
content: POST_CONTENT,
username: POST_WRITER,
tags: [ TAG1, TAG2, TAG3 ],
time: POST_TIME
comments: [
{
username: COMMENT_WRITER,
mesage: COMMENT_MESSAGE,
time: COMMENT_TIME
},
{
username: COMMENT_WRITER,
mesage: COMMENT_MESSAGE,
time: COMMENT_TIME
}
]
}MongoDB 기본적인 사용법
Create Collection
- RDB에는 Table 개념이 있듯이 MongoDB에는 Collection이 있음
- Collection은 Documents의 집합이라고 볼 수 있음
- Collection을 만드는 방법은 간단
- 아래 query가 실행하는 동시에 만약 해당하는 collection이 없으면 해당 collection를 만듬
inserOne과createIndex두 명령어만이 새로운 collection을 만들 수 있음
db.test.insertOne( { x: 1 } )
db.test1.createIndex( { y: 1 } )- 주의: Collection 이름은 MongoDB의 Naning 규칙 을 따라야 함
- 만약 Collection에 관하여 여러 가지 옵션을 설정할 필요가 있다면 아래 명령어를 이용하여 Collection을 만들 수 있음
db.createCollection( <name>,
{
capped: <boolean>,
timeseries: { // Added in MongoDB 5.0
timeField: <string>, // required for time series collections
metaField: <string>,
granularity: <string>
},
expireAfterSeconds: <number>,
autoIndexId: <boolean>,
size: <number>,
max: <number>,
storageEngine: <document>,
validator: <document>,
validationLevel: <string>,
validationAction: <string>,
indexOptionDefaults: <document>,
viewOn: <string>, // Added in MongoDB 3.4
pipeline: <pipeline>, // Added in MongoDB 3.4
collation: <document>, // Added in MongoDB 3.4
writeConcern: <document>
}
)CRUD: Insert
db.users.insert({username: "smith"})- 위에서 설명 했듯이
insert명령어를 실행하는 동시에 만약 users라는 collection이 없으면 자동 생성
CRUD: Read(Find)
find명령을 통하여 DB에 있는 데이터를 읽을 수 있음
db.users.find()
# result
[
{
"_id": {"$oid": "61873b253270f00a2c30c31d"},
"username": "smith"
},
{
"_id": {"$oid": "61873bb53270f00a2c30c31f"},
"username": "jones"
}
]- 특정 조전을 이용하여 조회하기
db.users.find({username: "jones"})
# result
[
{
"_id": {"$oid": "61873bb53270f00a2c30c31f"},
"username": "jones"
}
]- 여러 조건을 이용하여 검색
# and 조건
db.users.find({ $and: [
... { _id: ObjectId("552e458158cd52bcb257c324") },
... { username: "smith" }
... ] })
# or 조건
db.users.find({ $or: [
... { username: "smith" },
... { username: "jones" }
... ]})CRUD: Update
- 기록된 document를 수정하려고 하면
$set명령어를 사용하여 업데이트 가능
db.users.update({username: "smith"}, {$set: {country: "Canada"}})update구분 사용 시 주의 할 점,$set를 사용하지 않고 아래와 같이 명령어를 실행하면 username이 smith라는 document는 country: "Canada" 인 document로 대체됨
db.users.update({username: "smith"}, {country: "Canada"})$set을 이용하여 업데이트 할 수 있지만 매번마다 모든 document를 다시 써야 하는 번거로움이 있음- 예를 들어 하나의 키에 속성을 추가하고 싶을때는
$addToSet이나$push를 사용하면 됨
- 예를 들어 하나의 키에 속성을 추가하고 싶을때는
db.users.update( {"favorites.movies": "Casablanca"},
... {$addToSet: {"favorites.movies": "The Maltese Falcon"} },
... false,
... true )$addToSet에는 두 개의 파라미터가 필요한데 첫번째는 만약 존재하지 않으면insert할지 결정하고 두번째 파라미터는 여러개를 업데이트 할지 결정- MongoDB는 다른 요구사항이 없으면 기본적으로 1개만 적용 하게끔 설계되어 있음
CRUD: Delete
db.users.remove()- 아무 조건 없이 명령어를 실행하면 users collection의 모든 내용을 제거
- 조건을 붙이려면 파라미터에 조건을 넣으면 됨
db.users.remove({"favorites.cities": "Cheyenne"})remove명령어는 기본적으로 contents을 지우는 역할을 함- 만약 colection을 지우려면
drop()명령어를 써야함
- 만약 colection을 지우려면

🌱 Backend-Dev | hwaya2828@gmail.com