
1. 자료구조 기초
탐색이란 많은 양의 데이터 중 원하는 데이터를 찾는 과정을 의미한다. 프로그래밍에서는 자료구조 안에서 탐색을 하는 문제를 자주 다루는데, 여기서 자료구조란 데이터를 표현, 관리하고 처리하기 위한 구조를 말한다. 그 중 스택과 큐는 자료 구조의 기초 개념으로 삽입(push)과 삭제(pop)의 두 핵심적인 함수로 구성된다.
(1) 스택과 큐
스택은 선입후출/후입선출 구조이며, 큐는 선입선출 구조이다. append()와 pop() 메소드를 이용하여 스택 자료구조 문제를 해결할 수 있다. 한편 파이썬으로 큐를 구현할 때는 collection 모듈에서 제공하는 deque를 사용하면 효율적이다.
(2) 재귀함수
재귀함수란 자기 자신을 다시 호출하는 함수이다.
def recursion():
print('이것이 바로 재귀함수')
recursion()
recursion()이 경우 '이것이 바로 재귀함수'라는 문자열을 무한히 출력할 것이다. 따라서 재귀함수를 사용할 때에는 종료 조건을 명시하여야 한다.
2. DFS/BFS
(1) DFS(Depth-First Search)
DFS는 깊이 우선 탐색이라고도 부르며, 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘이다. 관행적으로 번호가 낮은 순서부터 처리한다.
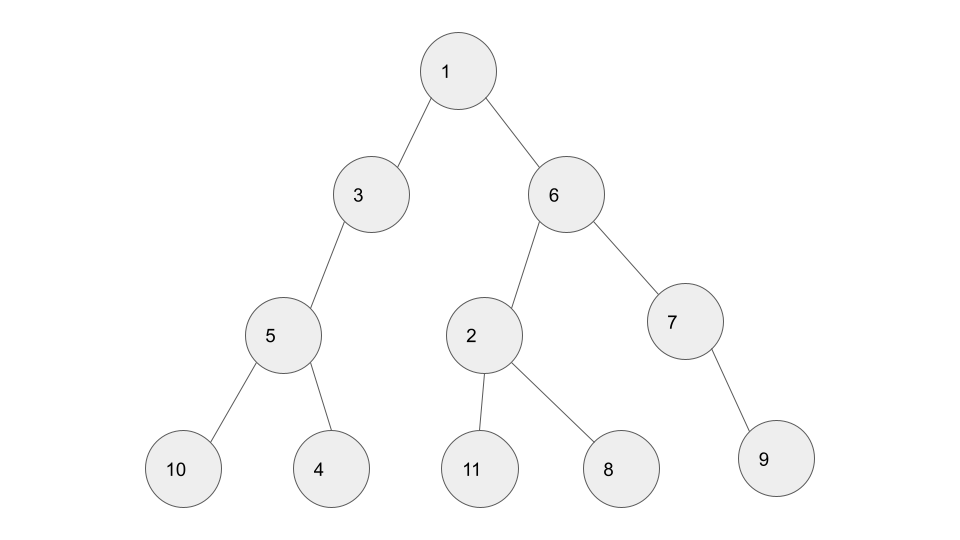
✏️ 시작노드인 1을 스택에 넣는다. 이후 인접한 3, 6 중 작은 노드인 3을 스택에 넣는다.
✏️ 3과 인접한 5를 스택에 넣고, 인접한 4, 10 중 작은 노드인 4를 스택에 넣는다.
✏️ 4에 인접한 노드 중 방문하지 않은 노드가 없으므로 4를 스택에서 꺼낸다.
✏️ 5와 인접한 10을 스택에 넣는다.
✏️ 10에 인접한 노드 중 방문하지 않은 노드가 없으므로 10을 스택에서 꺼내고, 마찬가지로 5, 다음으로 3을 스택에서 꺼낸다.
✏️ 1과 인접한 노드 중 방문하지 않은 6을 스택에 넣는다.
✏️ 6에 인접한 노드 중 작은 노드인 2를 스택에 넣는다.
✏️ 2와 인접한 노드 중 작은 노드인 8을 스택에 넣는다.
✏️ 8과 인접한 노드 중 방문하지 않은 노드가 없으므로 8을 스택에서 꺼내고, 2와 인접한 다른 한 노드인 11을 스택에 넣는다.
✏️ 11과 인접한 노드 중 방문하지 않은 노드가 없으므로 11을 스택에서 꺼내고, 마찬가지로 2도 꺼낸다.
✏️ 6과 인접한 노드 중 방문하지 않은 노드인 7을 스택에 넣는다.
✏️ 7과 인접한 9를 스택에 넣는다.
결과적으로 노드의 탐색 순서는 다음과 같다.
1 ⇨ 3 ⇨ 5 ⇨ 4 ⇨ 10 ⇨ 6 ⇨ 2 ⇨ 8 ⇨ 11 ⇨ 7 ⇨ 9
이를 재귀함수로 표현하면 다음과 같다.
>>> def dfs(graph, v, visited):
... visited[v] = True
... print(v, end=' ')
... for i in graph[v]:
... if not visited[i]:
... dfs(graph, i, visited)
...
>>> graph = [
... [],
... [3,6],
... [6,8,11],
... [1,5],
... [5],
... [3,4,10],
... [1,2,7],
... [6,9],
... [2],
... [7],
... [5],
... [2]
... ]
>>> visited = [False] * 12
>>> dfs(graph,1,visited)
1 3 5 4 10 6 2 8 11 7 9(2) BFS(Breadth-First Search)
BFS는 너비 우선 탐색이라고도 하며, 가까운 노드부터 탐색하는 알고리즘이다.
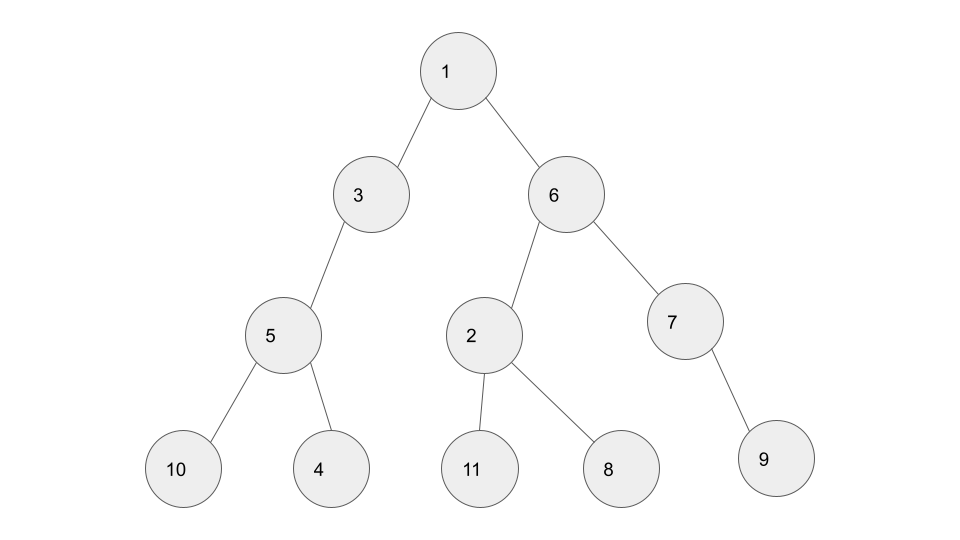
✏️ 시작 노드인 1을 큐에 삽입한다.
✏️ 이미 방문한 1을 큐에서 꺼내고 3과 6을 큐에 넣는다.
✏️ 큐에서 3을 꺼내고 방문하지 않은 인접 노드인 5를 큐에 넣는다.
✏️ 큐에서 6을 꺼내고 방문하지 않은 인접 노드인 2와 7을 모두 큐에 넣는다.
✏️ 큐에서 5를 꺼내고 방문하지 않은 인접 노드인 4와 10을 모두 큐에 넣는다.
✏️ 큐에서 2를 꺼내고 방문하지 않은 인접 노드인 8과 11을 모두 큐에 넣는다.
✏️ 큐에서 7을 꺼내고 방문하지 않은 인접 노드인 9를 큐에 넣는다.
결과적으로 노드의 탐색 순서는 다음과 같다.
1 ⇨ 3 ⇨ 6 ⇨ 5 ⇨ 2 ⇨ 7 ⇨ 4 ⇨ 10 ⇨ 8 ⇨ 11 ⇨ 9
이를 deque로 구현하면 다음과 같다.
>>> from collections import deque
>>> def bfs(graph, start, visited):
... queue = deque([start])
... visited[start] = True
... while queue:
... v = queue.popleft()
... print(v, end=' ')
... for i in graph[v]:
... if not visited[i]:
... queue.append(i)
... visited[i] = True
>>> graph = [
... [],
... [3,6],
... [6,8,11],
... [1,5],
... [5],
... [3,4,10],
... [1,2,7],
... [6,9],
... [2],
... [7],
... [5],
... [2]
... ]
>>> visited = [False] * 12
>>> bfs(graph, 1, visited)
1 3 6 5 2 7 4 10 8 11 93. 예시 문제
(1) Baekjoon Online Judge
(2) 프로그래머스

from itertools import product
def solution(numbers, target):
lst = [(n, -n) for n in numbers]
sum_lst = list(map(sum, product(*lst)))
return sum(1 for i in sum_lst if i == target)
from collections import deque
def solution(begin, target, words):
answer = 0
if target not in words:
return 0
queue = deque([begin])
while not target in queue:
for w in list(queue):
v = queue.popleft()
for word in words:
count_diffs = 0
for a, b in zip(v, word):
if a != b:
count_diffs += 1
if count_diffs == 1:
queue.append(word)
answer += 1
return answer
