
머신 러닝 기초
머신러닝
인공지능의 한 분야로, 누적된 경험을 통해 컴퓨터가 스스로 학습할 수 있게 하는 알고리즘
“우리는 데이터를 보고 "어떤 함수에 비슷한 모양일 것이다"라고 가설을 세우고 그에 맞는 손실 함수를 정의합니다. 우리가 하는 일은 여기서 끝이고 기계는 우리가 정의한 손실 함수를 보고 우리의 가설에 맞출 수 있도록 열심히 계산하는 일을 한답니다. 그래서 기계학습(머신러닝)이라는 이름이 붙게 된 것이지요.”
딥러닝
인공지능의 하위 개념이며, 인공신경망에서 발전한 형태
복잡한 인공신경망을 사용한 알고리즘을 통해 데이터를 학습
(ex. 무인 주행 자동차, 딥페이스, 포털 서비스 음성 검색 등)
머신러닝과 딥러닝
- 머신러닝은 알고리즘이 부정확한 예측을 반환하면 엔지니어가 개입하여 조정
- 딥러닝은 추상적인 정보를 인식하는 능력이 뛰어나기 때문에 머신러닝과 달리 개와 고양이를 식별
- 머신러닝은 엔지니어가 미리 각 데이터가 개인지 고양이인지를 정의 내려야 하는 반면, 딥러닝은 개의 데이터와 개가 아닌 데이터들이 주어지면 자동으로 개인지 아닌지를 군집화하고 분류
- 많은 양의 데이터가 주어진 경우에는 딥러닝은, 그렇지 않은 경우에는 머신러닝을 활용하는 것이 효율적
1. 분류 vs 회귀
1) 회귀 Regression
출력 값이 연속적인 것
연속적인 문제를 예측하도록 하는 것
2) 분류 Classification
비연속적 문제
이진 분류, 다중 분류
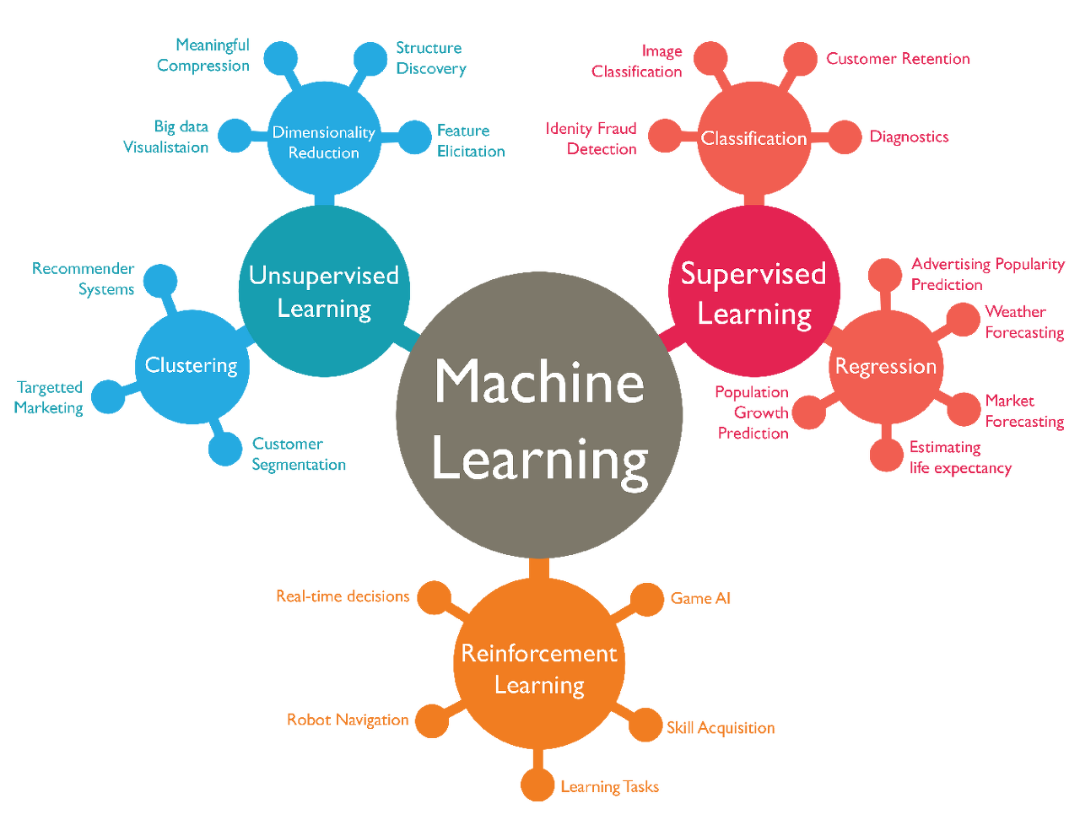
2. 학습 방법
1) 지도 학습(Supervised learning): 정답을 알려주면서 학습시키는 방법
2) 비지도 학습(Unsupervised learning): 정답값을 가지고 있지 않은 상태에서 자율 학습, 그루핑 알고리즘, 입력값만 많다
군집, 시각화, 차원 축소, 연관 규칙 학습
- 지도 학습 vs 비지도 학습:
정답값의 유무
정답 값이 있는 것이 학습하기 쉽고 정확성이 높다
3) 강화 학습(Reinforcement learning): 게임, 실시간 처리(ex. 알파고)
행동에 대한 보상을 받으며 학습, 마이너스 보상도 존재, 경우의 수 학습
- 에이전트(Agent): 학습하는 객체
- 환경(Enviroment): 게임 환경(룰)
- 상태(Status): 환경의 상태
- 행동(Action): 에이전트의 행동(목록이 정해져 있어야 함)
선형회귀(Linear Regression)
선형적으로 예측할 수 있는 방법
선형 1차 함수
1. 가설(Hypothesis)
예측하는 문제가 선형이다 라고 가정
가설에 맞춰 문제를 풀도록 학습
가설은 사람이 정함
2. 손실함수(cost fuction, loss fuction)
점과 직선의 거리
임의로 만든 직선 H(x)를 가설(Hypothesis)이라고 하고 Cost를 손실 함수(Cost or Loss function)라고 함
3. 평균제곱오차(Mean Squared Error)
직선(가설)과 점(정답)의 거리
최소화, 최적화 문제
H(x)는 우리가 가정한 직선이고 y는 정답 포인트라고 했을 때 H(x)와 y의 거리(또는 차의 절대값)가 최소가 되어야 이 모델이 잘 학습되었다고 말할 수 있을겁니다.
4. 다중 선형 회귀(Multi-variable linear regression)
입력 값 여러 개
경사 하강법
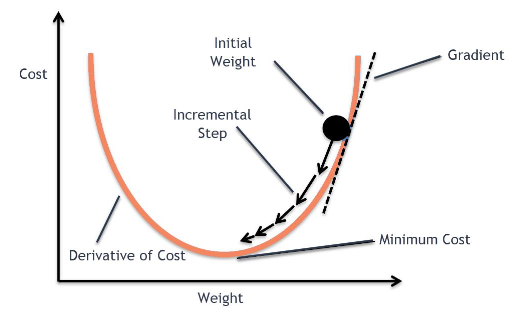
손실 함수를 최소화(Optimize)하기 위해 점진적으로 문제를 풀어감
Learning rate
- 전진하는 단위
- 최소 지점에 도달하면 학습 종료
- Learning rate가 작으면 학습하는데, 즉 최소값에 수렴하기까지 많은 시간이 걸린다
- Overshooting: Learning rate가 지나치게 크다면 최소값을 지나치고 진동하다가 발산하게 될 수 있다
머신러닝 모델이 학습을 잘하기 위해서는 적당한 Learning rate를 찾는 과정이 있어야 함
머신러닝과 엔지니어
머신러닝 엔지니어의 핵심 역할: 최적화 튜닝
핵심 개념: 직선은 하나고 정답값의 거리를 계산하는 것
실습
TensorFlow 기본 머신러닝 프레임워크
같은 코드가 많았음
Keras 사용하기 쉬운 상위 API, TensorFlow의 클래스
세션(Session) tf에서 사용하는 모든 변수들과 그래프들을 저장하고 있는 저장소
📋 Intro: 맥주를 얼마나 마셔야.. 행복해질까요?..
🚩 What to do: 맥주 소비량을 토대로, 행복 지수를 예측해보는 것

맥주소비량이 1000일 때의 행복지수를 예측한 결과 출력
# 데이터 프레임 읽기
df = pd.read_csv('HappinessAlcoholConsumption.csv')
# 데이터 프레임 생김 보기
df.head(5)
print(df.shape)
# pairplot
sns.pairplot(df, x_vars=['Beer_PerCapita'], y_vars=['HappinessScore'], height=5)
# 데이터셋 정의
x_data = np.array(df[['Beer_PerCapita']], dtype=np.float32)
y_data = np.array(df['HappinessScore'], dtype=np.float32)
# keras에 적합하게 reshape
x_data = x_data.reshape((-1, 1))
y_data = y_data.reshape((-1, 1))
print(x_data.shape)
print(y_data.shape)
# 데이터셋 분할
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2022)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)
# Linear Regression model 학습
model = Sequential([
Dense(1)
])
# compile
model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.046))
# fit
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val),
epochs=100
)
Epoch 100/100
4/4 [==============================] - 0s 10ms/step - loss: 1.5262 - val_loss: 1.4259
# 예측 그래프
y_pred = model.predict(x_val)
plt.scatter(x_val, y_val)
plt.scatter(x_val, y_pred, color='r')
plt.show()
# 예측값 출력
y_pred = model.predict([[1000]])
print(y_pred)
[[14.7191105]]