이전 포스팅에서 beautifulsoup을 알아봤다. 이어서 실습을 진행해보자.
실습할 사이트는 빌보드이며,
빌보드 순위 1~100위 까지의 순위, 노래제목, 아티스트, 앨범이미지에 대한 정보 크롤링이 목표이다.
사이트분석
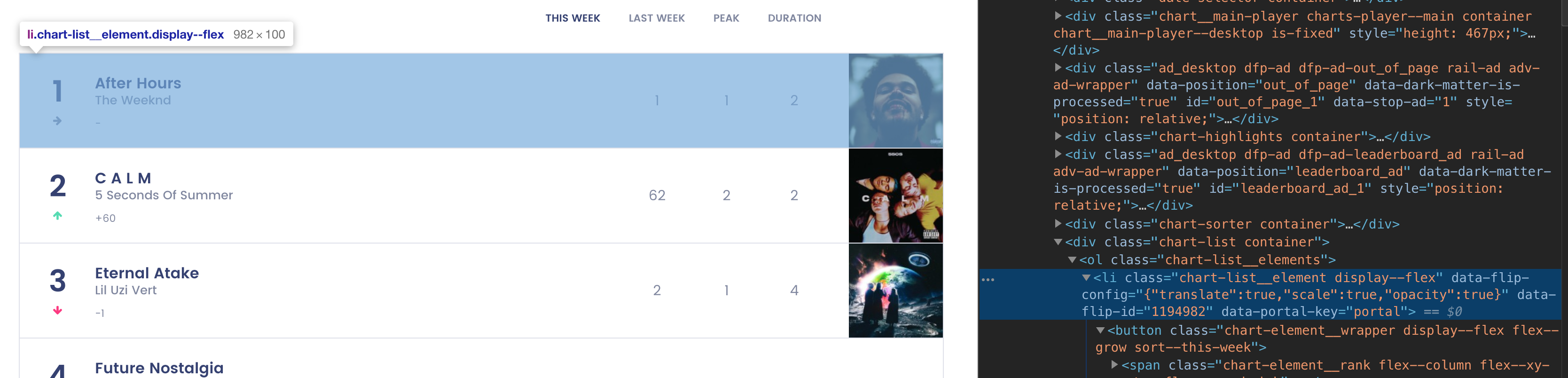
사이트에서 보여주는 차트를 보니 list 태그안에 동일한 클래스명을 갖고 있는 것이 보인다. 차트 리스트를 추출한 뒤 반복문을 통해 각각의 순위, 노래제목, 아티스트, 앨범이미지 정보를 가져오자.
- 차트 전체를 class = 'chart-list__element' 옵션을 통해 가져온다
- 반복문을 range(100) 동안 돌리고 내부에 포함된 순위, 노래제목, 아티스트, 앨범이미지를 추출한다.
- 순위 : span, class = 'chart-elementranknumber'
- 노래제목 : span, class = 'chart-elementinformationsong'
- 아티스트 : span, class = 'chart-elementinformationartist'
- 이미지 : span, class = 'chart-element__image', style = background-image속성
crawling
import
from bs4 import BeautifulSoup
import csv, re, requestscsv에 저장
output = 'test_crawling_01.csv' # 저장할 파일 지정, 경로+파일명.확장자 입력
csv_open = open(output,'w+', encoding='utf-8')
csv_writer = csv.writer(csv_open)
# 테이블의 컬럼명을 지정해 주자.
csv_writer.writerow(('index','title','artist','image_url'))추출한 데이터는 DB에 저장해도 되지만, 이번에는 CSV 파일에 저장하도록 하겠다.
사이트 정보
# 크롤링할 사이트 Url
orig_url = 'https://www.billboard.com/charts/billboard-200'
req = requests.get(orig_url) # requests모듈을 통해 데이터를 받는다.
html = req.text # req.text에는 html문서가 들어있다. beautifulsoup
# soup 만들기
soup = BeautifulSoup(html, 'html.parser') # html문서와, 해석기가 인자로 들어간다.탐색하기
top_200_list = soup.find_all('li', class_='chart-list__element')
result = []
for i in range(100):
# ㅇ위에서 사용한 class_='값' 과 아래 방식은 같은 결과를 출력한다. 편한 방식으로 사용하자.
result.append({
'index' : top_200_list[i].find('span', {'class':'chart-element__rank__number'}).text, # re.compile() 사용하고 안하고 차이는 뭘까?
'title' :top_200_list[i].find('span', {'class':'chart-element__information__song'}).text,
'artist' :top_200_list[i].find('span', {'class':'chart-element__information__artist'}).text,
'image_url': top_200_list[i].find('span', {'class':'chart-element__image'})['style'].split('\'')[1]
})
# print(i, top_200_list[i])
print(result)
Image_url의 정보를 가져오는데 오류가 났다. 참조사이트를 방문해 개발자도구/네트워크 탭을 보니, 처음 로딩때 받는 사진은 4순위 이미지 까지다. 나머지는 스크롤 이벤트에 따라 로딩되는 것이 확인 되었다...흑.. 이런 동적인 크롤링에는 selenium을 사용한다 한다.
.. 아직 셀레니움을 살펴보지 않아. 1~4번까지만 이미지를 저장하고, 나머지는 None을 입력하도록 수정하고 CSV파일로 최종 아웃풋이 되도록 코드를 수정해보자!
CSV에 데이터삽입
for i in range(100):
def check_image_url():
value = bool(top_200_list[i].find('span', {'class':'chart-element__image'})['style'])
if value:
return top_200_list[i].find('span', {'class':'chart-element__image'})['style'].split('\'')[1]
return None
index = top_200_list[i].find('span', {'class':'chart-element__rank__number'}).text # re.compile() 사용하고 안하고 차이는 뭘까?
title = top_200_list[i].find('span', {'class':'chart-element__information__song'}).text
artist = top_200_list[i].find('span', {'class':'chart-element__information__artist'}).text
image_url = check_image_url()
# CSV 에 저장하자
csv_writer.writerow((index, title, artist, image_url))
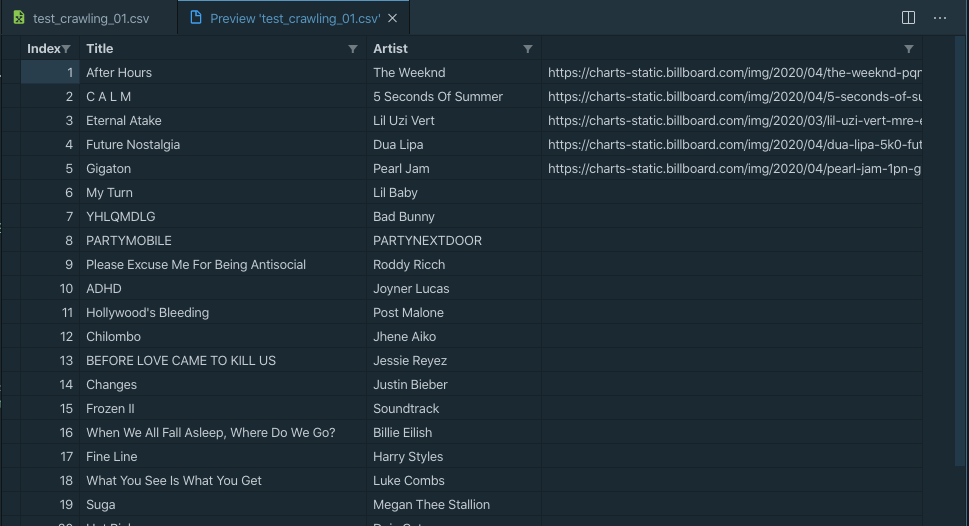
최종 아웃풋이 나왔다. 이미지가..빈공간이 많지만 원하는 데로 정보를 받아왔다.
다음 포스팅에서 셀레니움에 대해 알아보고, 빈 이미지URL을 체워보도록 하자!

TIL 기록 블로그 :: 문제가 있는 글엔 댓글 부탁드려요!