[머신러닝] Supervised Learning , Unsupervised Learning ( 지도 학습, 비 지도 학습 )

📌 Machine Learning 유형 분류
Machine Learning은 입력받는 데이터의 차이에 따라 두 가지의 유형으로 분류됩니다.
- 지도 학습 ( Supervised Learning )
- 비 지도 학습 ( Unsupervised Learning )
📌 지도 학습 ( Supervised Learning )
Predictive Learning 으로도 불리는 지도 학습은 Training set 으로 입출력의 쌍을 받습니다. 즉, input으로 들어오는 feature vector와 output으로 나가는 class 혹은 label을 Training set으로 받습니다.
Training set에서의 input은 D개의 차원으로 구성된 feature vector입니다.
Training set에서의 output은 label이나 class 같은 분류에 대한 정보이거나 일반적인 real value입니다.
여기서 output이 real value로 주어진다면, regression에 대한 문제가 됩니다.
또는 output이 categorical 즉, label 혹은 class로 주어진다면 classfication(분류) 혹은 pattern recognition(패턴 인식 문제)가 됩니다.
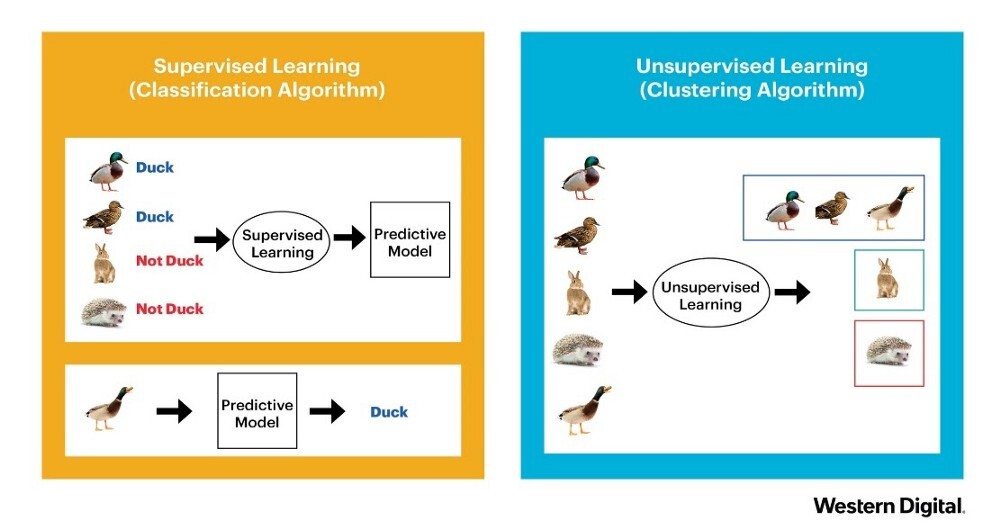
위의 사진을 예로 들면, 지도 학습의 경우 네 가지의 동물에 대한 정보(input)와 해당 동물의 분류(output)을 모두 train set으로 받습니다. train set을 통해 input과 output을 학습하여 앞으로 주어질 input을 올바른 output으로 이끌어낼 function을 학습하는 것이 지도학습의 목적입니다.
그림에서는 학습을 거쳐서 이후에 들어오는 동물에 대해 Predictive model을 거쳐서 해당 동물이 어떤 class에 속하는 지 판단합니다.
요약
지도학습은 input, output을 모두 training set으로 받는다.
트레이닝 셋으로 학습을 걸쳐서 Predictive Model을 만들어 낸다. ( 앞으로 있을 input에 대해 올바른 output을 낼 수 있는 function )📌 비 지도 학습 ( Unsupervised Learning )
비 지도 학습은 지도 학습과 다르게 training set으로 오직 input만을 받습니다. output은 주어지지 않습니다. 비 지도 학습에서는 input의 특징(feature)에서 패턴을 찾습니다.
따라서 비 지도 학습의 경우, 지도 학습과는 다르게 알려지지 않은 문제들이 많고, 지도 학습보다 어려운 경우가 많습니다.
특징들을 분석을 통해 알려지지 않은 패턴에 대해 학습을 할 수 있습니다. 그 결과로 새로운 데이터가 입력으로 주어졌을 때, 분류하도록 합니다.
비 지도 학습에서는 데이터 간의 유사도, 패턴, 차이 등을 이용하여 데이터를 분류할 수 있는 학습을 진행합니다.
위의 사진을 예로 들면, 비 지도 학습의 경우 동물들의 feature vector만을 train set으로 제공받습니다. 해당 정보들만을 이용하여 비슷한것끼리, 다른 것끼리 분류합니다.
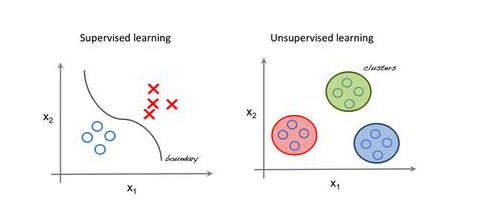
좌측의 경우가 지도 학습을 통해서, 얻어진 function을 통해서 input들을 적절한 output에 매칭시키는 경우입니다.
우측의 경우가 비 지도 학습을 통해서, 얻어진 패턴, 유사도, 차이를 이용하여 input들을 적절하게 분류시키는 경우입니다.
요약
비 지도학습은 input을 training set으로 받는다.
트레이닝 셋으로 학데이터 간의 유사도, 패턴, 차이 등을 이용하여 특성을 분석하는 학습을 진행한다.
기존에 학습된 density estimate를 기반으로 앞으로 있을 input에 대한 분류를 진행한다.📌 확률적 추측 ( Probabilistic Prediction )
현실에서는 training set이 무한하지 않고, 유한하기 때문에 한정적입니다. 따라서 새로운 input에 대해 이전에 보지 못했거나, 정확한 분류를 할 수 없는 모호한 경우가 발생할 수 있습니다. 따라서 이런 경우에 사용할 수 있도록 일반화되고 정규화된 학습이 필요합니다. 여기에 확률 모델을 사용합니다.
📌 마무리
다음에는 머신 러닝에서 사용되는 확률 모델에 대한 자세한 이야기를 이어서 하겠습니다.
