112만건의 정보, 220만건의 Insert (대규모 업데이트, Bulk Insert)
1. 개요
AI가 분류한 데이터 (130만건)를 처리하는 업무를 담당하게 되었다. 이 데이터는 CSV 형식으로 제공되며, 이를 두 개의 데이터베이스 테이블, Log와 Entity,에 각각 저장해야 합니다. Log 테이블에는 5개의 컬럼이, Entity 테이블에는 10개의 컬럼이 있다. 결과적으로, 총 260만건의 데이터 삽입 작업이 필요하다.
초기에는 백오피스 서버에서 CSV 파일을 스트림 처리하여 데이터를 나누고 삽입하는 방식을 고려했다. 그러나 이 방법은 처리 속도가 느리고, 스트림 처리 중 문제가 발생하면 처음부터 다시 시작해야 한다는 단점이 있었다. 이에 대한 해결책으로, 저는 스프링 배치(Spring Batch)를 사용하기로 결정했다.
스프링 배치를 선택한 이유는 다음과 같다.
- 먼저, 대규모 데이터 처리에 적합하며, 처리 과정 중 발생하는 오류를 관리하고 이어서 처리할 수 있는 기능이 필요했고,
- 트랜잭션 관리가 자동화되어 있고, 데이터 가공 과정이 필요했고,
- 백오피스 서버에서의 데이터 처리는 안정성 측면에서 많은 불편함을 예상했기 때문에, 스프링 배치를 통한 접근 방식이 훨씬 효과적일 것으로 기대하고 있다.
2. 10,000건 처리하는데 걸리는 시간?
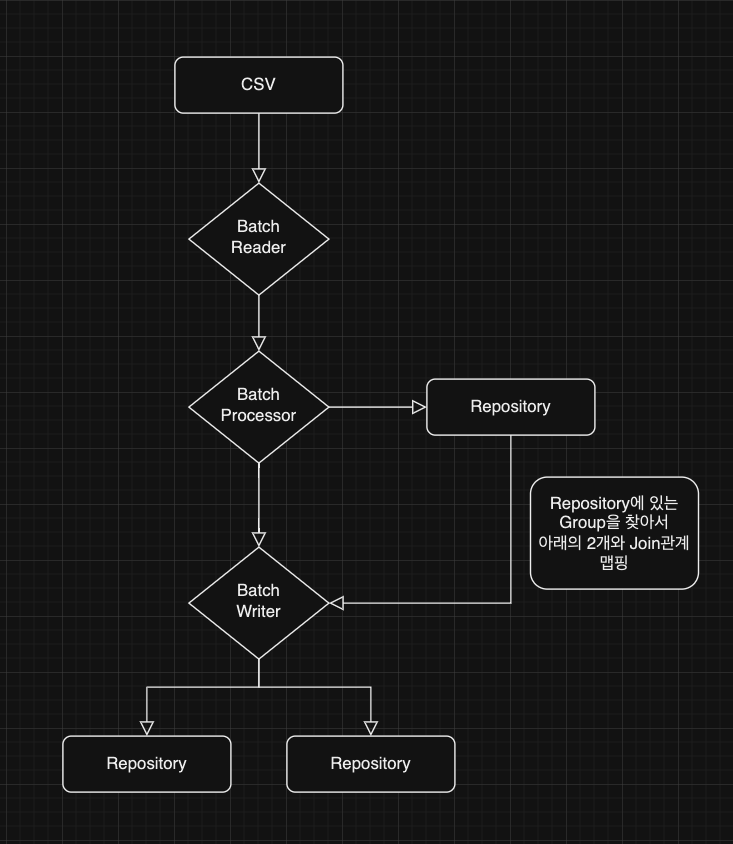
대략적인 구성은 이렇다
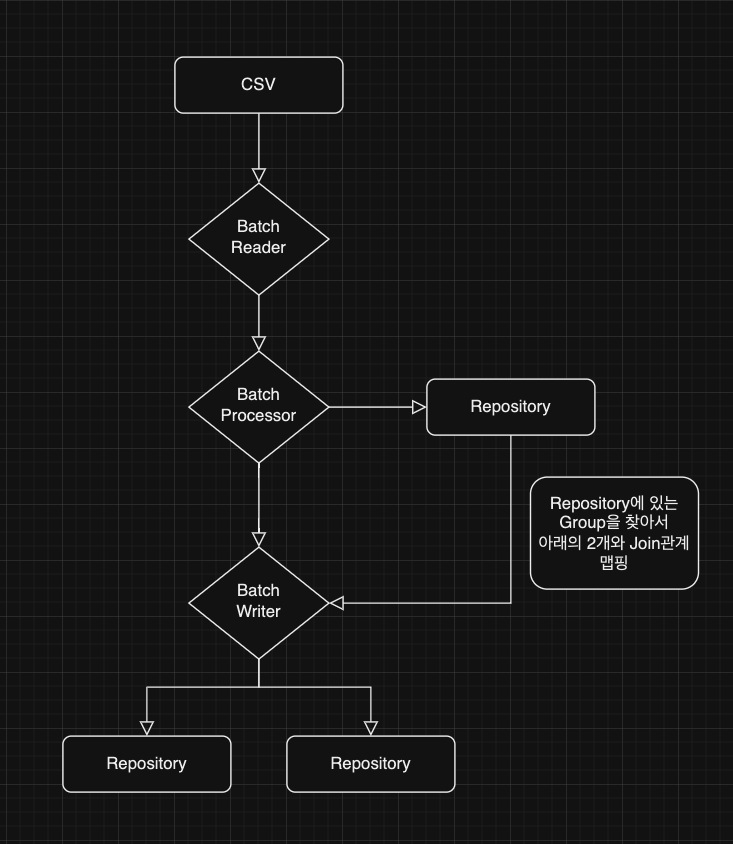
내가 대량의 데이터(130만 건) 처리를 맡았는데, 문제는 데이터의 양이었다.
최적화를 처음 시도했을 때, 저는 Bulk Insert를 위해 Writer 단계에서 각 객체를 Collection으로 묶고 JPA의 findAll을 사용했다.
그 결과, 1만 개의 데이터를 처리하는 데 무려 14분이 걸렸다. 이런 속도라면 130만 개의 데이터 처리에 약 30시간이 소요될 것으로 예상됐다.
이러한 비효율성을 인지하고, 저는 문제의 원인을 다각도로 분석했다
- CSV에 있는 Group ID를 이용해 DB에서 Group을 조회할 때, 개별적으로 조회하는 방식이었다.
- JPA의
saveAll은 실제로는 Bulk Insert가 아니었다. - 컬렉션 최적화에 실패했다. Set을 사용했음에도 불구하고, 이는 나의 오만이었다.
이러한 문제들을 하나씩 해결하기 위해 접근했다..
1)FindByIdIn
간단한 이야기이다. 1개씩 10,000개를 조회하는 것보다 10,000개를 한 번에 조회하는 것이 효율적이다.
현재 내가 사용하는 DB 서버에 한 번 접근하는데 정말 많은 시간이 소모된다.

1번 접근하는데 걸리는 시간은 대략 3초…
그럼 간단한 계산으로 10,000개를 각각 조회한다면 시간이 엄청나가 소요된다.
JPA의 영속석 컨텍스트를 사용해도 이러한 시간 부담은 피할 수 없었다.
때때로는 두 개의 테이블에 접근하여 두 가지 데이터를 가지고 와야 하는 상황도 종종 있었다.
(이미 저장된 경우는 업데이트를 해야 하기 때문)
이러한 로직을 해결 하기 위해서는 ‘FindByIdIn’을 사용하기로 했다.
JPA에는 간단하게 사용하기 위해 ‘FindAllById’를 지원해준다. 이러한 로직으로 실행을 하면 Select 쿼리가 아래의 사진과 같이 한 번에 실행되는 것을 확인할 수 있다.
SELECT *
FROM salaries
WHERE id IN (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)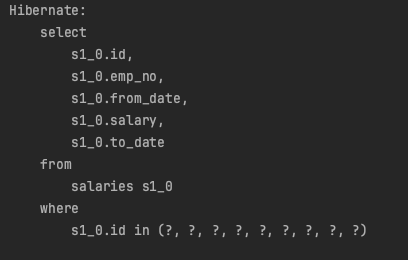
한 번의 접근으로 많은 정보를 가져오는 것만으로도 시간이 상당히 절약할 수 있었다.
많은 데이터를 다루는 만큼, 한번 한번의 접근이 소중해졌다.
2)시간 차이
그렇다면 얼마나 걸릴까?
그냥 FindBy를 한다면
230만건을 조회하는데 아래와 같이 51분 48초가 소모된다 걸린다.
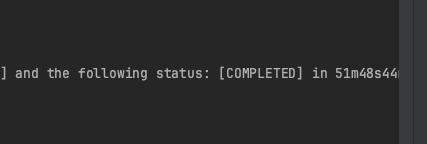
FindByIn을 사용한다면 아래와 같이 2분 10초가 걸린다.
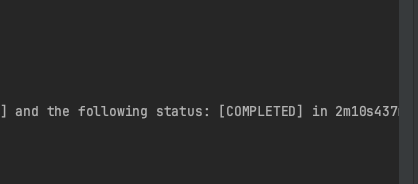
위와 같이 조회하는데에도 시간이 꽤 많이 차이가 난다. 무조건 FindByIn을 사용해야하는 이유이다.
3)SaveAll 은 Bulk Insert가 아니다
우선 위에 대해서 설명하기 전에 Bulk Insert가 무엇인지 설명해야한다.
Bulk Insert는 한 번의 작업으로 여러 행을 데이터베이스 테이블에 삽입하는 방법을 의미한다.
즉, 기존에는
INSERT INTO 테이블명 (컬럼1, 컬럼2, 컬럼3, ...) VALUES (값1_1, 값1_2, 값1_3, ...);
INSERT INTO 테이블명 (컬럼1, 컬럼2, 컬럼3, ...) VALUES (값2_1, 값2_2, 값2_3, ...);
INSERT INTO 테이블명 (컬럼1, 컬럼2, 컬럼3, ...) VALUES (값3_1, 값3_2, 값3_3, ...);
INSERT INTO 테이블명 (컬럼1, 컬럼2, 컬럼3, ...) VALUES (값4_1, 값4_2, 값4_3, ...);
INSERT INTO 테이블명 (컬럼1, 컬럼2, 컬럼3, ...) VALUES (값5_1, 값5_2, 값5_3, ...);위와 같은 형식으로 SQL문을 작성해야했다.
하지만 Bulk Insert를 사용하면 아래와 같은 접근이 가능하다.
INSERT INTO 테이블명 (컬럼1, 컬럼2, 컬럼3, ...)
VALUES
(값1_1, 값1_2, 값1_3, ...),
(값2_1, 값2_2, 값2_3, ...),
(값3_1, 값3_2, 값3_3, ...),
...
(값N_1, 값N_2, 값N_3, ...);이 방법을 사용하면, 한 번의 서버 접근으로 10,000개의 데이터를 저장할 수 있게 되며, 서버에 접근하는 횟수가 대폭 줄어들어 접근 시간이 크게 단축되고, MySQL에서 처리하는 속도도 향상된다.
나는 JPA의 saveAll이 Bulk Insert인줄 알았다. 당연히 지원을 해줄 줄 알았는데, savAll이 Bulk Insert가 아니었다…
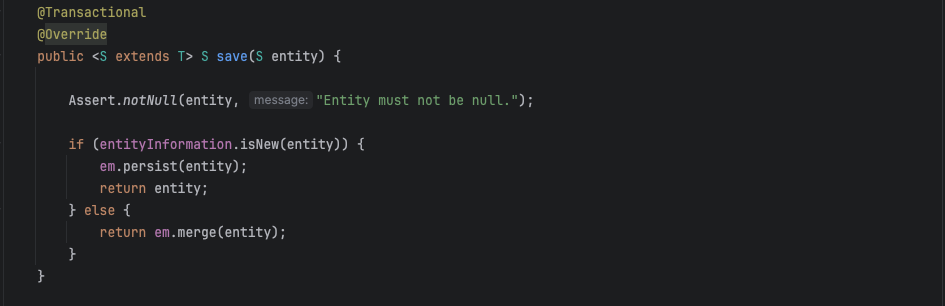
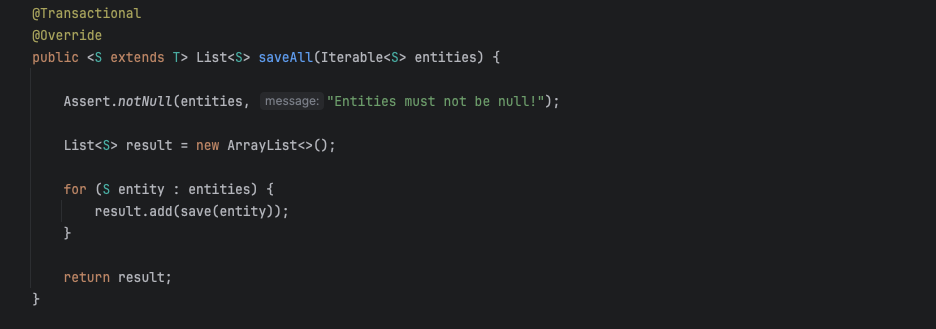
이로 인해서 JDBC Templet을 이용해서 Bulk Insert를 구현하였다.
3. Bulk Insert 구현
fun bulkInsertSalaries(salaries: List<Salary>) {
jdbcTemplate.batchUpdate(
"INSERT INTO salaries (emp_no, salary, from_date, to_date) VALUES (?, ?, ?, ?)",
object : BatchPreparedStatementSetter {
override fun setValues(ps: PreparedStatement, i: Int) {
val salary = salaries[i]
ps.setInt(1, salary.empNo)
ps.setInt(2, salary.salary)
ps.setDate(3, java.sql.Date.valueOf(salary.fromDate))
ps.setDate(4, java.sql.Date.valueOf(salary.toDate))
}
override fun getBatchSize(): Int = salaries.size
}
)
}위와 같은 형식으로 구현을 했다.
JDBC를 사용하면 .batchUpdate 을 지원해주기 때문에 벌크 인서트를 구현하기 쉽다.
또한 데이터베이스의 url 설정에 rewriteBatchedStatements=true도 추가해주어야 한다.

위와 같은 형식으로 INSERT를 하는 경우 얼마나 성능이 향상될까…?
4. 성능 표
- Save
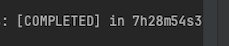
- SaveAll
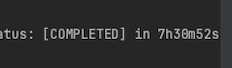
- BulkInsert
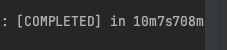
시간 차이가 엄청나게 단축되었다.
(테스트 환경 : CPU : INTEL Celeron J4025 // Ram : 512mb Nas의 Doker Mysql 8.0.18)
(Spring Batch // Chunk Size = 10000 // Read File = CSV)
벌크 인서트가 아니면 대량 인서트는 불가능하다고 생각하는 것이 마음이 편할 것 같다.
[[2편으로는 Bulk Update 성능 개선에 관하여 작성하겠습니다]]
