React

로그인
로그인의 역사
첫번째 로그인의 역사
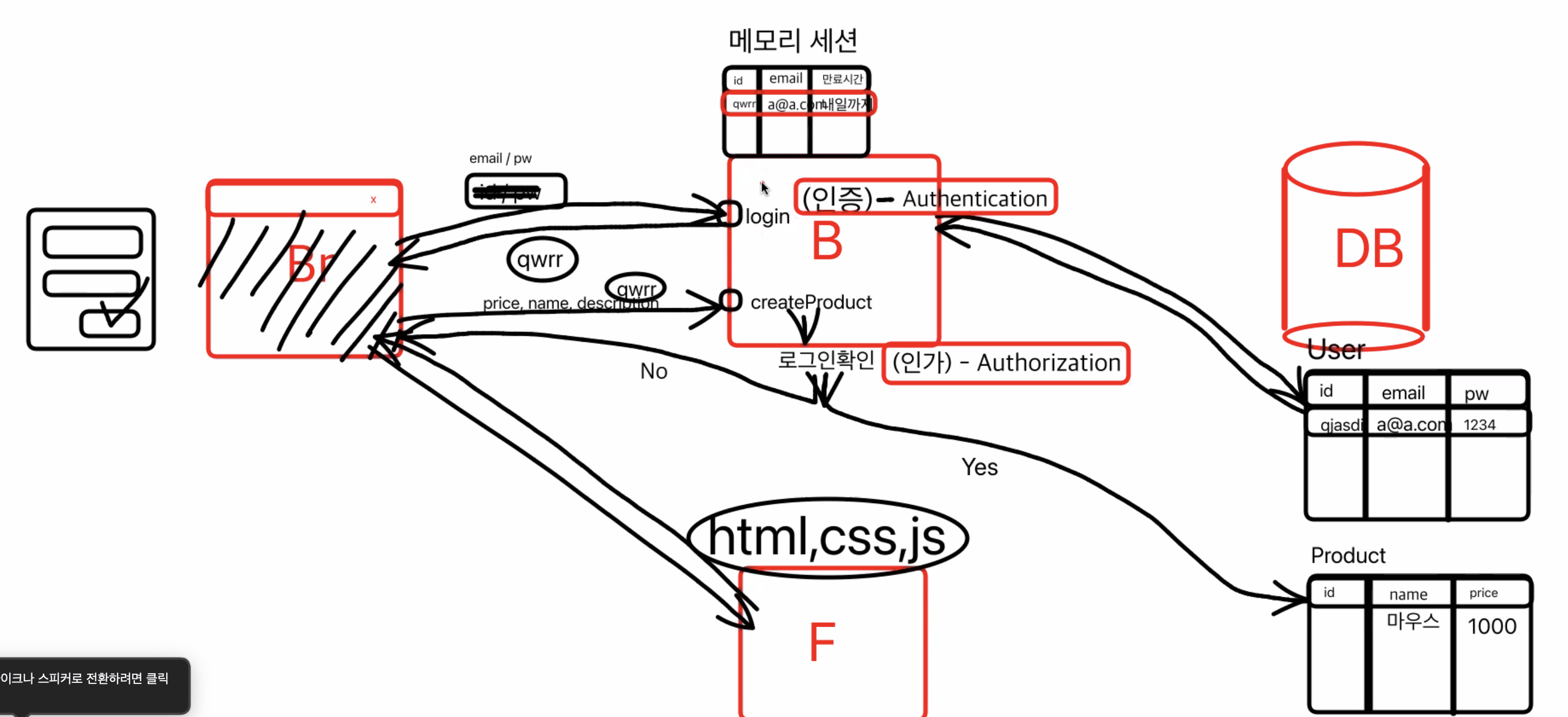 브라우저, 백엔드, 프론트, DB가 있을 때
브라우저, 백엔드, 프론트, DB가 있을 때
- 브라우저에서 email, pw를 입력하고 로그인 버튼을 누르면
- 백엔드로 login API 요청이 날아가게 되고,
- 백엔드 컴퓨터에서 DB를 통해 해당 유저가 있는지(일치하는 정보가 있는지)확인 후
- 있으면 백엔드 컴퓨터의
메모리 세션에 저장해두게 된다 (메모리 세션에는 만료시간이 정해져있다)- 그 후 특정한 id를 부여해서 브라우저로 보내준다 (해당 유저가 뭔가를 요청할 때 본인이 누군지 식별할 수 있도록) => 이런 과정을
인증이라고 함(Authentication)
- 디스크 : 영구저장 (ex: c드라이브에 저장하기)
- 메모리 : 컴퓨터 껐다 키면 사라지는 저장 (ex: 램에 저장하기(변수 등))
이렇게 유저의 정보(Id)를 백엔드 서버로 받다보니 한번에 여러명의 정보를 받기엔 한계가 있었고, 이를 보완하기 위해서 백엔드 컴퓨터를 scale-up(컴퓨터의 성능을 올려주는 것)을 해줌
두번째 로그인의 역사
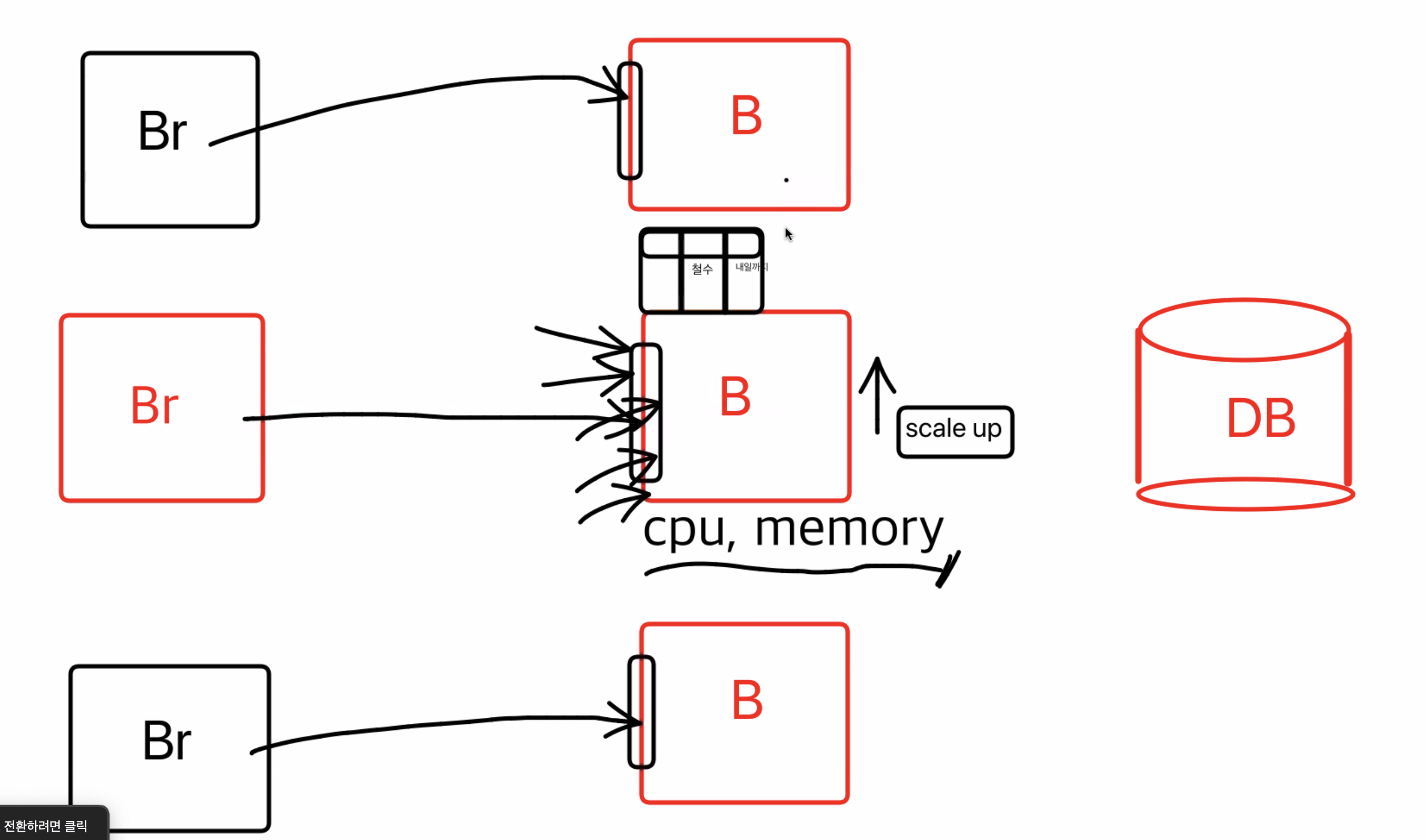
성능을 올려줬는데도 불구하고, 유저의 접속이 동시다발적으로 많이 일어나면 서버에 과부하가 오게된다
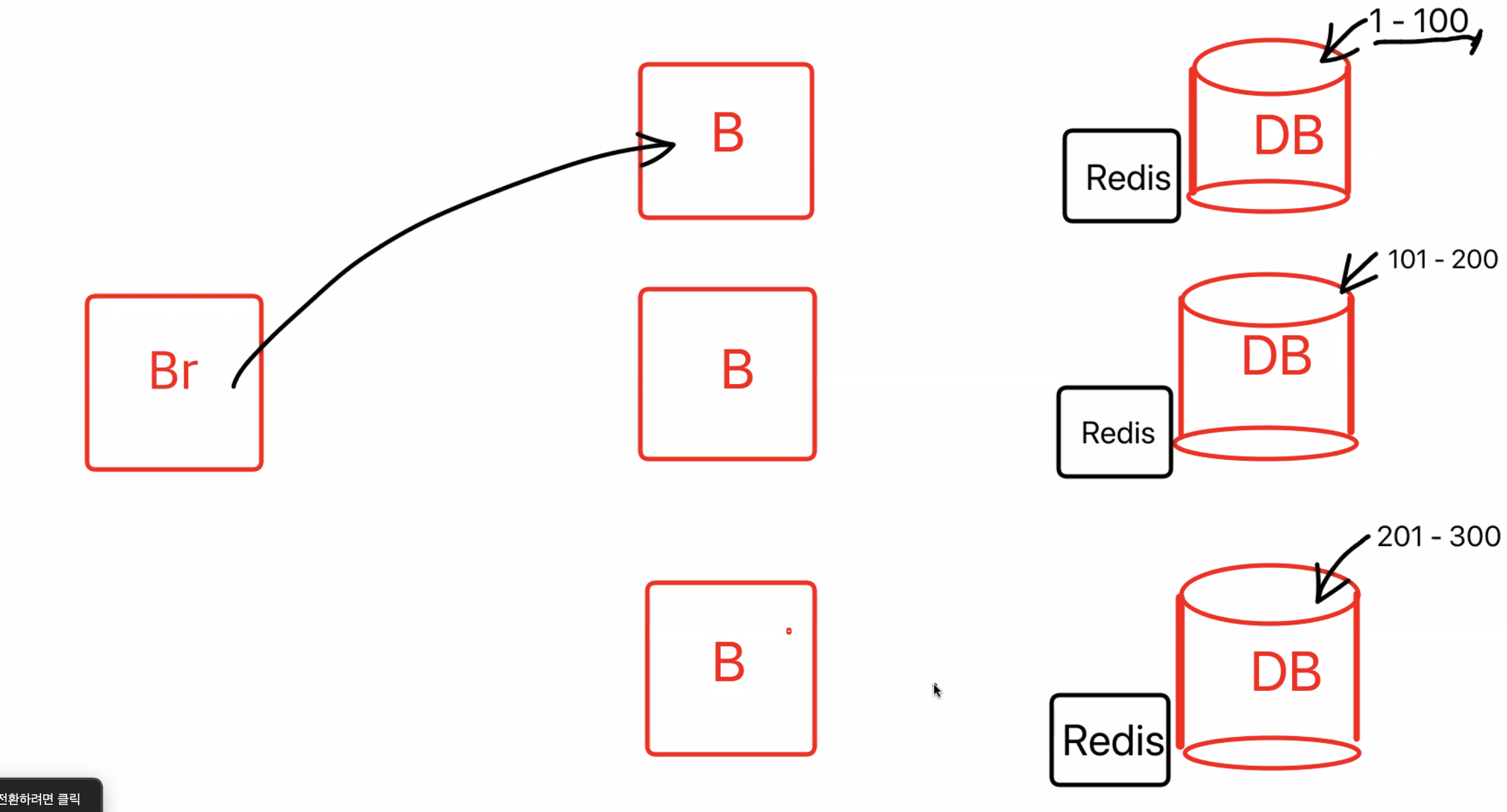
그래서 나온 방법이 백엔드 컴퓨터를 복사하는 방법 scale out
유저의 정보가 담기는 백엔드 컴퓨터를 복사해서 여러대의 컴퓨터로 서버의 부하를 분산해줬다
여기서 문제점은?
컴퓨터를 복사할때는 세션까지 scale out(똑같은 성능의 컴퓨터를 추가하는것)은 안되기 때문에 기존의 로그인 정보를 가지고 있는(stateful 상태) 백엔드 컴퓨터가 아니면, 로그인 정보가 없음(stateless)
세번째 로그인의 역사
위의 session을 scale-out 해오지 못하는 문제점을 보완하여 현재 많이 쓰이고 있는 방법
-
세션을 복사해오지 못하니까,
로그인 정보를 DB에 저장하기 시작했다.하지만 결국 이것도 백엔드 서버의 과부하가 DB로 옮겨진 것이기 때문에 DB의 과부하를 초래한다
- DB를 복사하면 안되나? 라고 생각할 수 있지만, 비용문제 때문에 비효율적 -
그래서 위의 문제점은 데이터를 쪼개면서 해결하게 된다
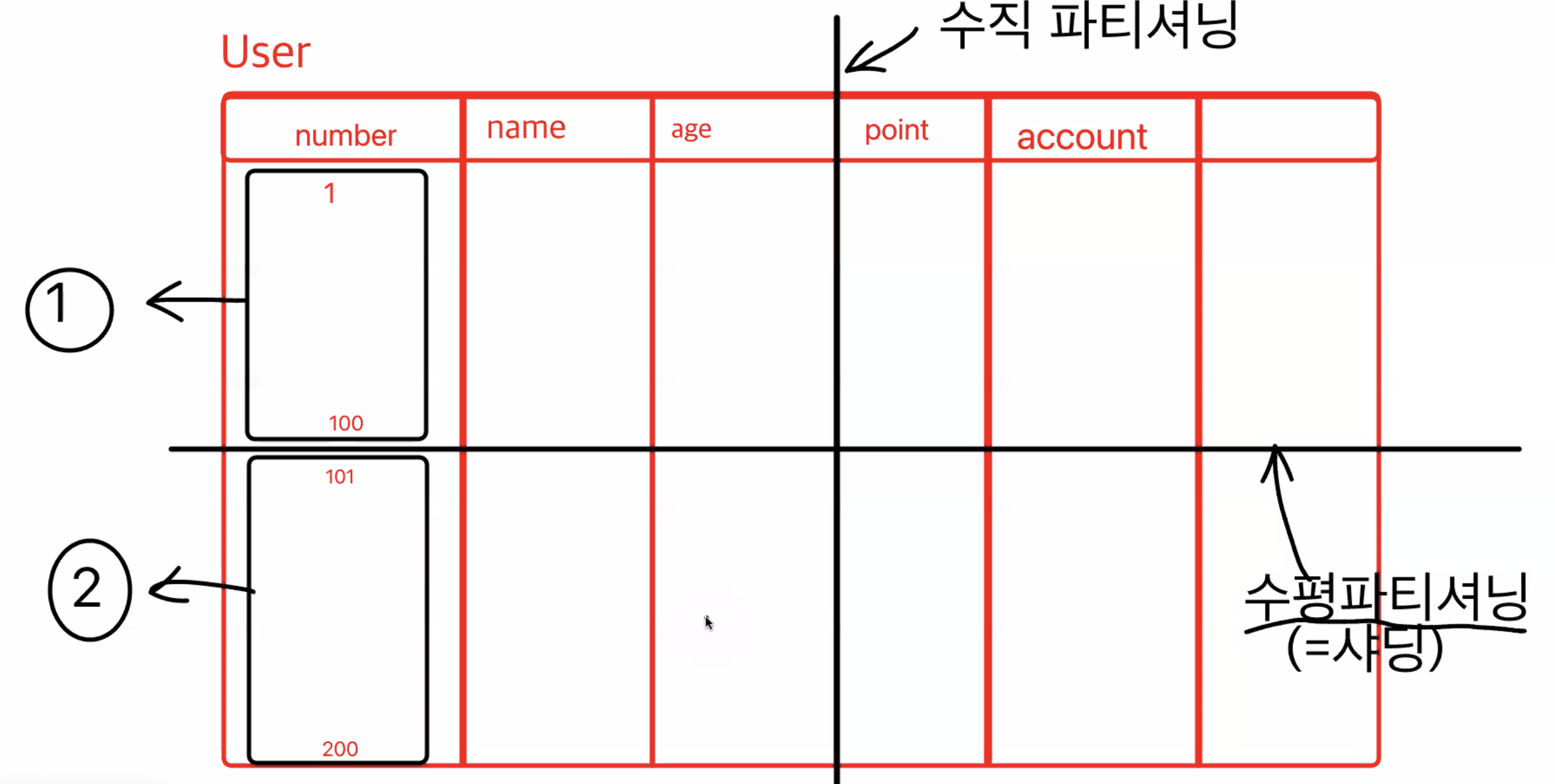
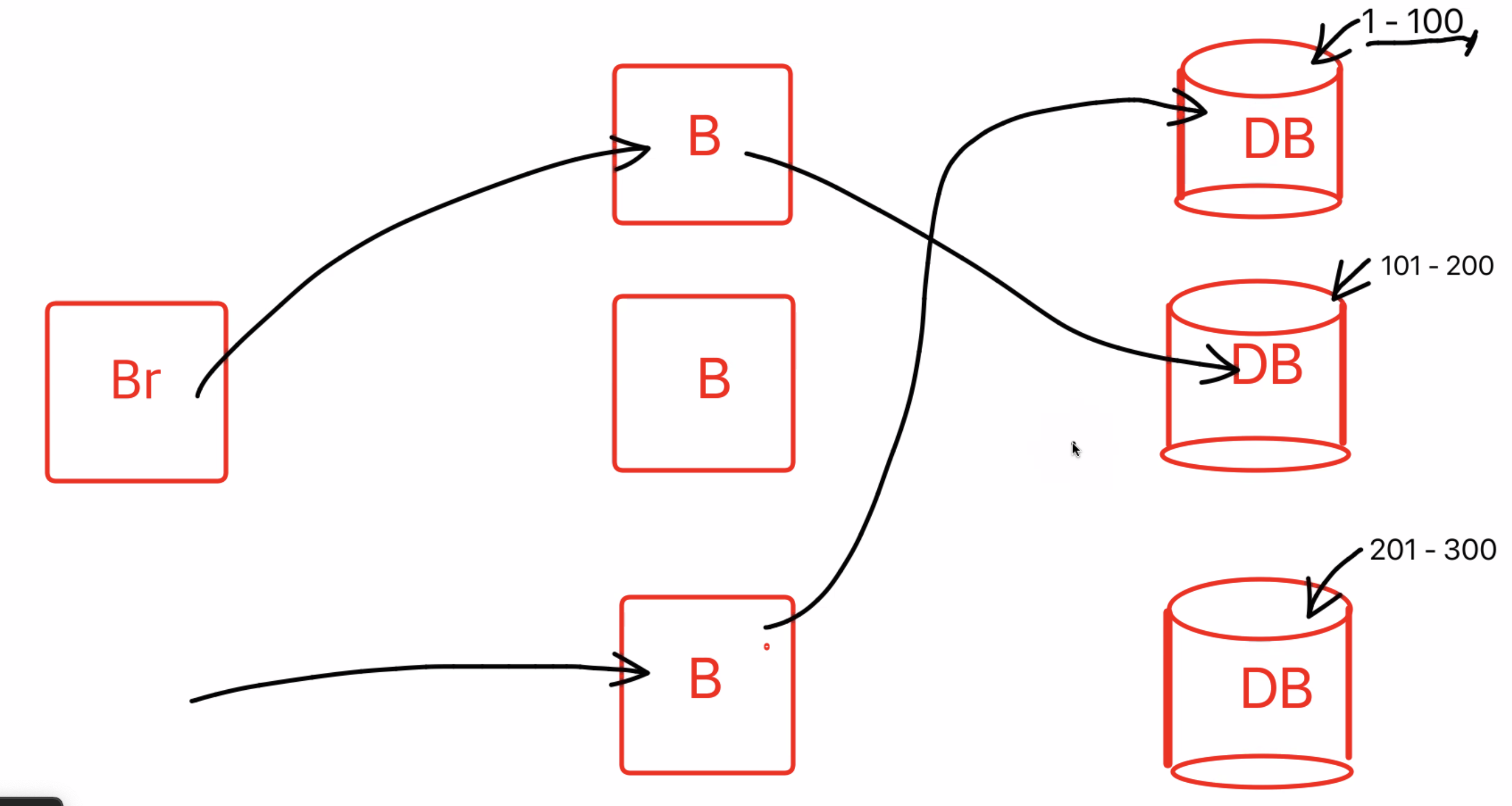
- 수직으로 쪼개는 수직파티셔닝
- 수평으로 쪼개는 수평파티셔닝(샤딩)
-
그런데 여기에도 문제점이 있음
DB는 컴퓨터를 껐다 켜도 날아가지 않기 때문에 데이터들이 disk에 저장된다.=> 따라서 안전하지만 느려!
이렇게 disk에 저장된 데이터를 추출해오는 현상을 DB를 긁는다(scrapping) 라고 한다 -
이걸 또 해결하기 위해서 Redis라는 데이터베이스에 저장해줌 (Redis는 메모리에 저장하기 때문에 위의 문제점을 해결해줌)
 - redis : 메모리에 저장해두는 임시 데이터 베이스
- redis : 메모리에 저장해두는 임시 데이터 베이스 -
이렇게 저장된 특정 ID(토큰)를 다시 브라우저로 돌려주게 된다
돌려받은 토큰은 브라우저 저장공간에 저장해두고, 어떤 행동을 할 때 토큰을 같이 보내줘서 사용자가 누군지 식별하게 한다
JWT 로그인
네번째 로그인의 역사
어떤 사람들이 로그인 정보를 굳이 서버나 DB에 저장해야 할까? 라는 생각을 했고,
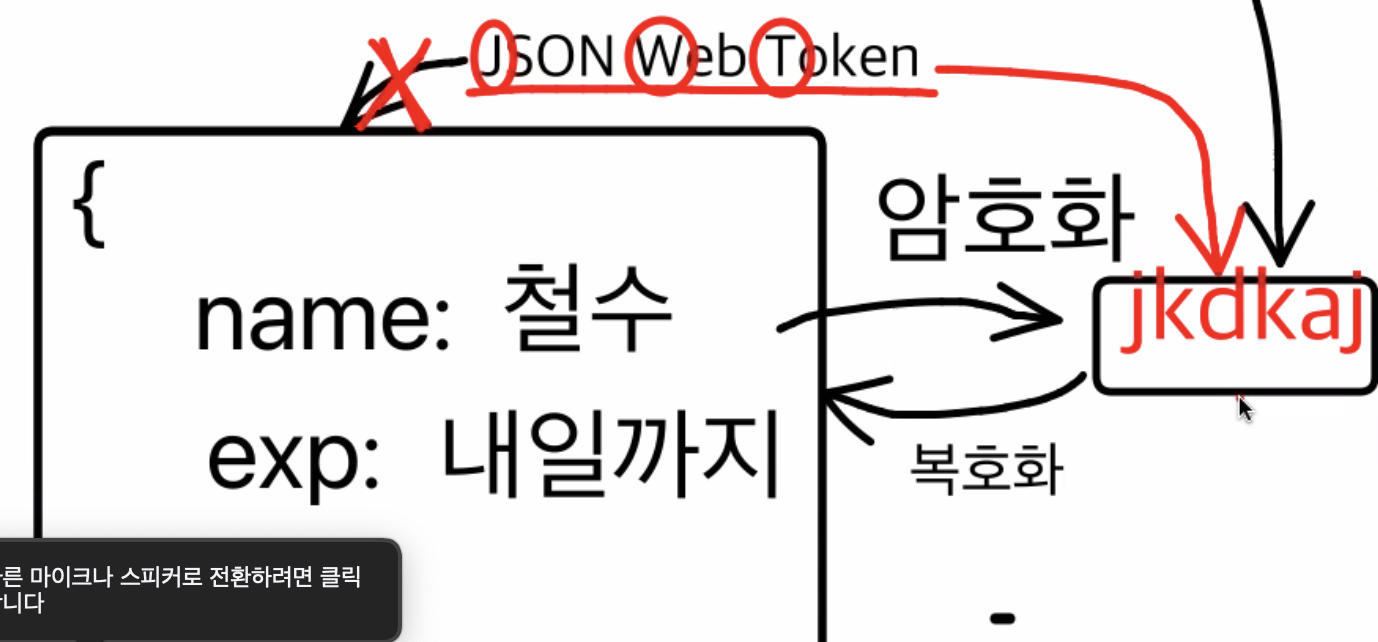
그렇게 탄생한게 JWT 토큰 : JSON Web Token

-
JWT 토큰은 유저 정보를 담은 객체를 문자열로 만들어 암호화한 후 암호화된 키(accessToken)를 브라우저에 준다
-
받아온 암호화된 키를 브라우저 저장소에 저장해두었다가 유저의 정보가 필요한 API를 사용할 때 보내주고
-
해당 키를 백엔드에서 복호화해서 사용자를 식별한 후 접근이 가능하도록 한다
-
JWT 토큰에는 해당 토큰이 발급 받아온 서버에서 정상적으로 발급을 받았다는 증명을하는 signature 를 가지고 있고, 따라서 사용자의 정보를 DB를 열어보지 않고도 식별할 수 있게 됨
- 인증이란? 유저가 누구인지 확인하는 절차, 회원가입하고 로그인 하는 것
- 인가란? 유저에 대한 권한을 허락하는 것.
JWT 토큰 실습
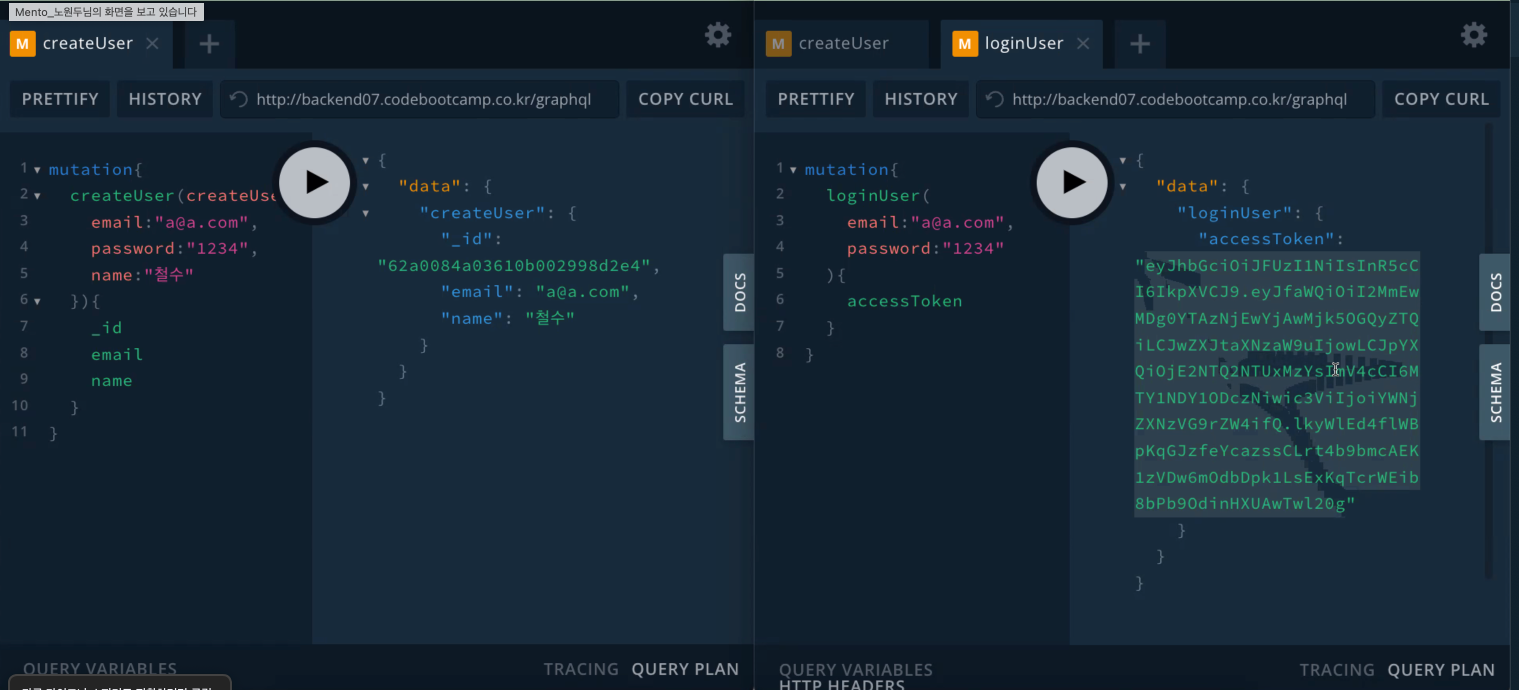 회원가입 후 로그인을 진행하면 acessToken 을 받을 수 있음
회원가입 후 로그인을 진행하면 acessToken 을 받을 수 있음
=> JWT 토큰 은 암호화는 되어있지만 아무나 열어볼 수 있다 그래서
중요한 데이터 넣으면 안됨
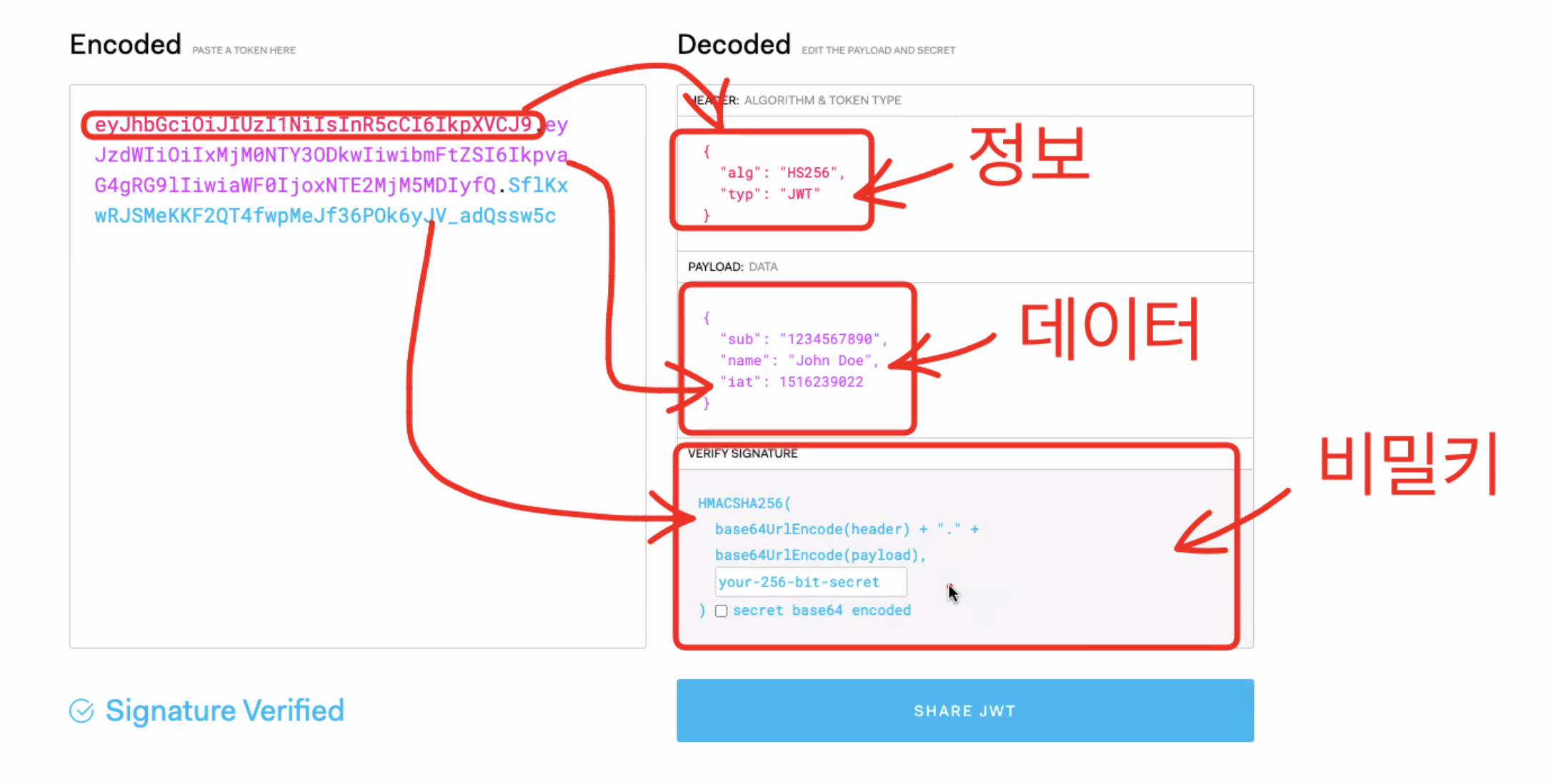
- JWT 토큰의 구성
- header : 토큰의 타입, 암호화시 사용한 알고리즘 정보
- payload : 토큰 발행정보(누구인지, 언제 발행되었는지, 언제 만료될 것 인지)
- signature : 토큰의 비밀번호
로그인 정보 받아오기(토큰 같이 보내주기)
fetchUserLoggedIn 할 때 HTTP HEADERS에 Authorization 후 Bearer뒤에 토큰 써서 보내주기
단방향 암호화(해싱)와 양방향 암호화
우리가 로그인을 하고, 로그인 정보를 fetch 해왔을 때 브라우저에 비밀번호는 fetch 할 수 없어야 함 (비밀번호를 알아내지 못하게)
DB에 있는 비밀번호를 알아낼 수 있게되면, 민감한 정보에 접근이 가능하기 때문에 !
따라서 비밀번호나 계좌번호같은 민감한 정보는 백엔드에 저장할때 그대로 저장하지 않음
양방향 암호화
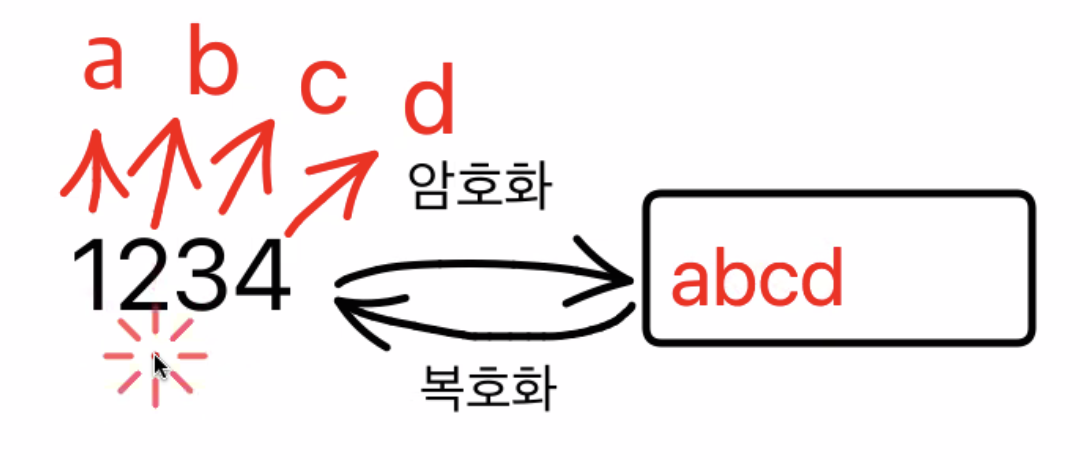
양방향 암호화는 JWT같은 복호화가 되는 암호화 ! 즉 암호화와 복호화 모두할 수 있는 암호화
단방향 암호화(hash)
단방향 암호화는 암호화는 되지만 복호화는 안되는 것을 의미
**275719—암호화—>779**
앞에서 부터 2개씩 끊어가지고 10으로 나눈 나머지를 적어놓은게 779
10으로 나눴을 때 나머지가 7이 되는 숫자는 27,37,47 등등 너무나도 많기 때문에 원래 정보가 뭔지 모르게 만드는 것
이를 다대일 이라고 하는데(원본이 다가 되고 암호화한게 일이 되니까), 이는 레인보우 테이블로 무작정 다 대입해서 복호화 하는 경우도 있어서 이부분을 보완하기위해서 조금더 어려운 알고리즘을 추가하기도 함
따라서 민감한 정보를 저장할때는 해킹을 당해도 알아볼 수 없도록 단방향 암호화를 사용하여 저장하게 된다
Daily-Scrum
데이터구조 : 스택 과 큐
데이터구조
: 데이터에 편리하게 접근하고 변경하기 위해 데이터를 저장하거나 조직하는 방법
스택과 큐는 각자의 생김새와 데이터 저장 방법이 다른 데이터 구조라고 생각하자 !
스택

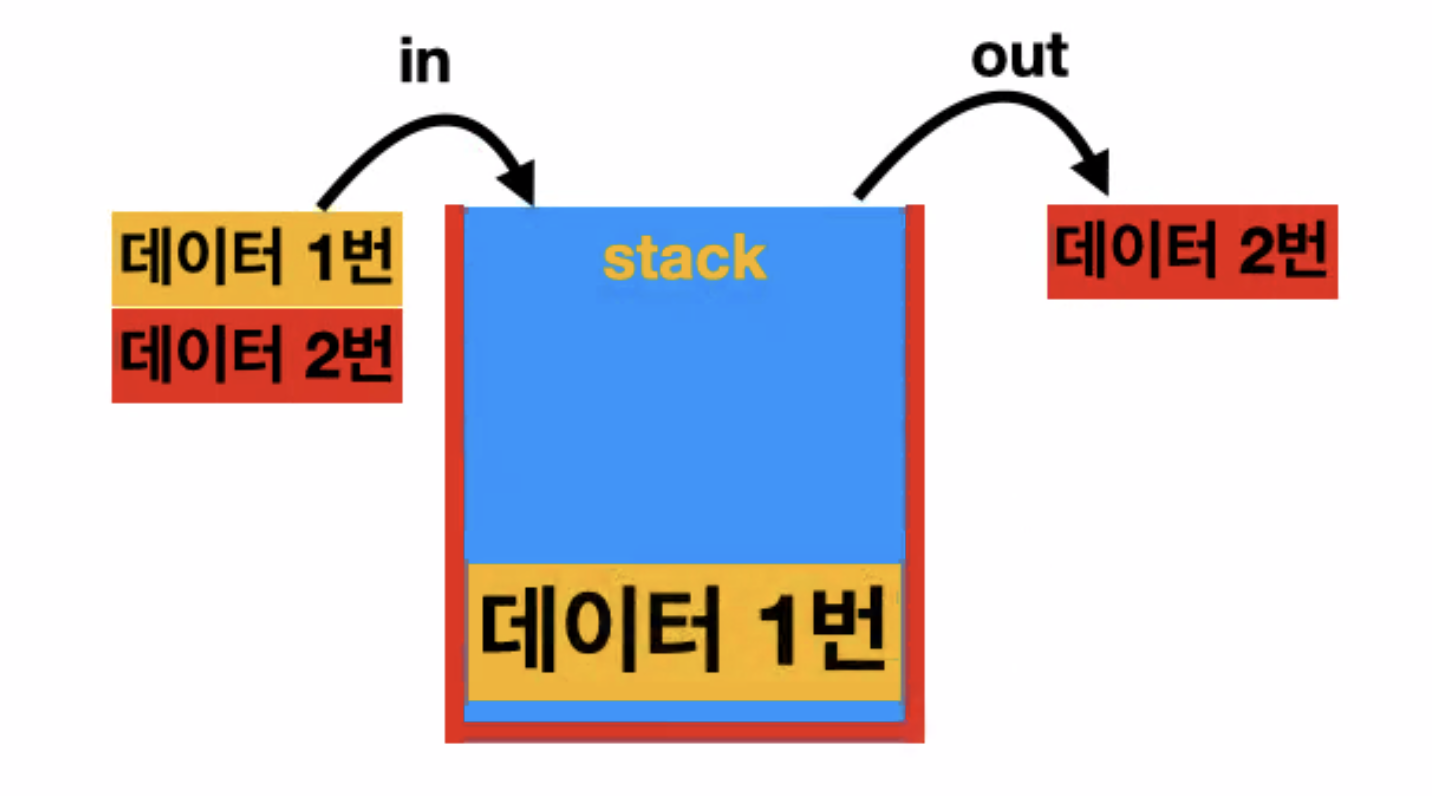
들어오는 순서랑 나가는 순서가 반대 !
큐
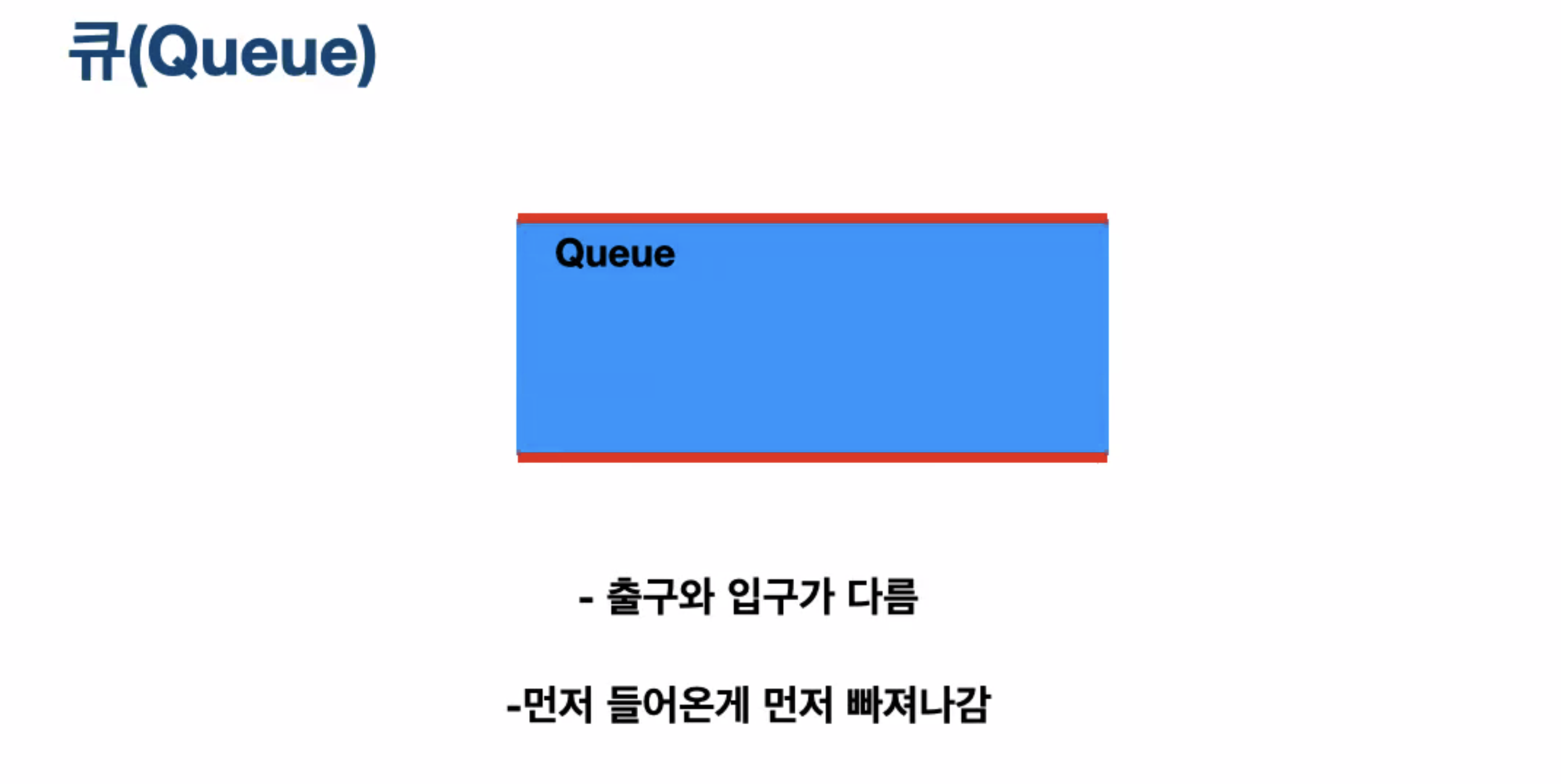
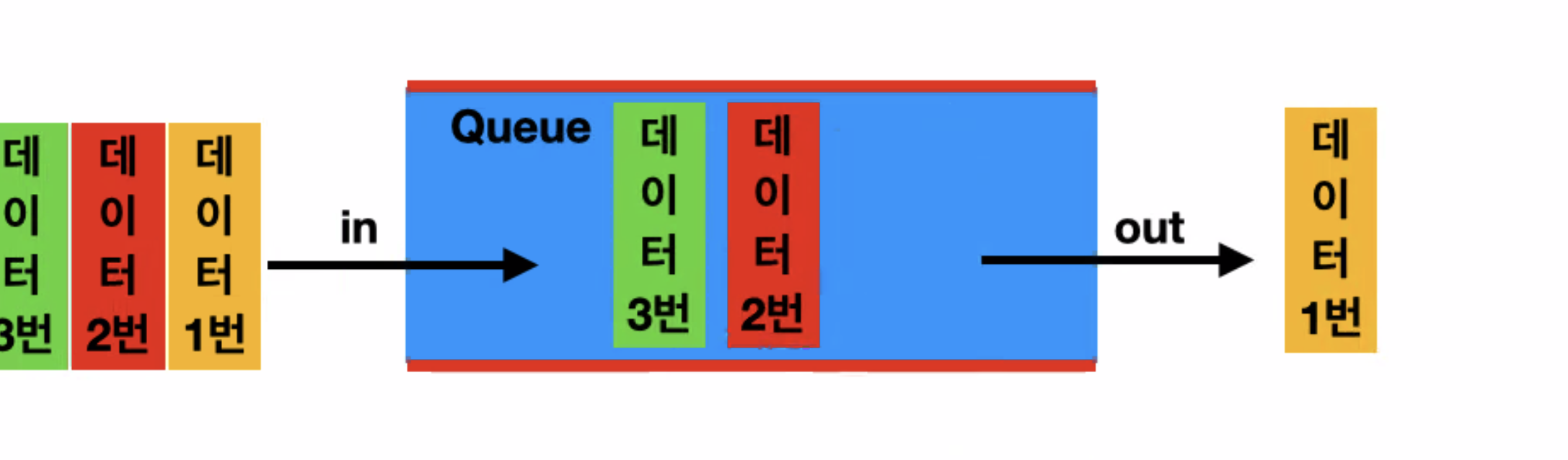
출구와 입구가 다름
먼저 들어온게 먼저 빠져나감
실행 컨텍스트
실행 컨텍스트와 실행컨텍스트로 인해 발생하는 현상

실행 컨텍스트를 만들 수 있는 방법 => 함수를 실행하는 것
- 스택에 쌓았던 데이터들이 바로 실행 컨텍스트 였따
실행 컨텍스트의 구성 
스코프 체인 : 해당 스코프에서 찾아보고, 없으면 상위 스코프로 찾아보러 올라가는것
