OVER
OVER절은 윈도우 함수에서 아주 중요하다.
윈도우는 그룹이라고 생각하면 된다.
윈도우 = 그룹
이 윈도우를 가지고 코드를 실행하여 값을 산출한 다음 해당 값을 각 행에 출력한다.
GROUP BY와 달리 각 그룹(각 윈도우)를 합치지 않는다.
SELECT AVG(salary) OVER() FROM employees;OVER()절을 빈 괄호와 함께 사용하면 윈도우가 생성되는데, 이 때 빈 괄호는 모든 행을 포함하는 윈도우를 의미한다.
OVER는 집계 함수와 함께 사용할 수 있다.
-- 일반 집계 함수와 함께 사용하는 예시 코드
SELECT emp_no, department, salary, AVG(salary) OVER(),
MAX(salary) OVER(),
MIN(salary) OVER() FROM employees;PARTITION BY
OVER안에서 사용되는PARTITION BY.
하나의 거대한 윈도우를 만드는 대신 더 작은 다수의 윈도우를 만들 수 있다.
SELECT emp_no, department, salary, AVG(salary) OVER(PARTITION BY department) AS dept_avg FROM employees;
OVER(PARTITION BY ...)를 사용하여 조회한 부서별 평균 월급
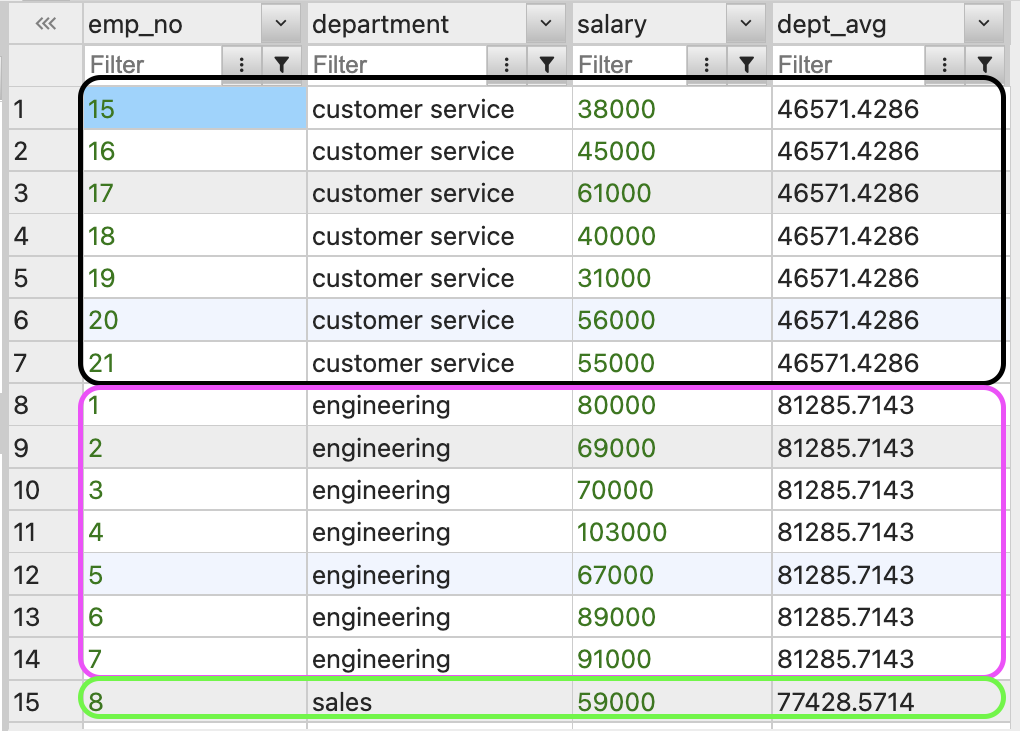
OVER(PARTITION BY ...)를 사용한 위 코드는 부서별 평균 월급을 출력한다.
🔥 여기서 드는 생각이 있다.
Q.
GROUP BY로 할 수 있지 않나요?
A. 각 행마다 출력할 수 없고, 통합하여 결과값을 보여줄 수 있습니다.
Group By를 사용하여 조회한 부서별 평균 월급
각각의 행으로 부서별 평균값이 나오지 않는다.
대신 각 그룹이 하나의 행으로 합쳐짐을 확인했다.
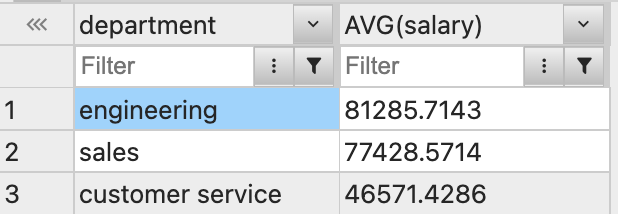
⭐️ 단순하게 부서별 급여 평균을 알고싶을 때는 GROUP BY를 사용하는 것이 효율적이다.
반면, 직원이 받는 월급과 직원들이 소속된 부서 급여 평균에 비교하고자 할 때에는 OVER(PARTITION BY ...)를 사용하는 것이 적합하다.
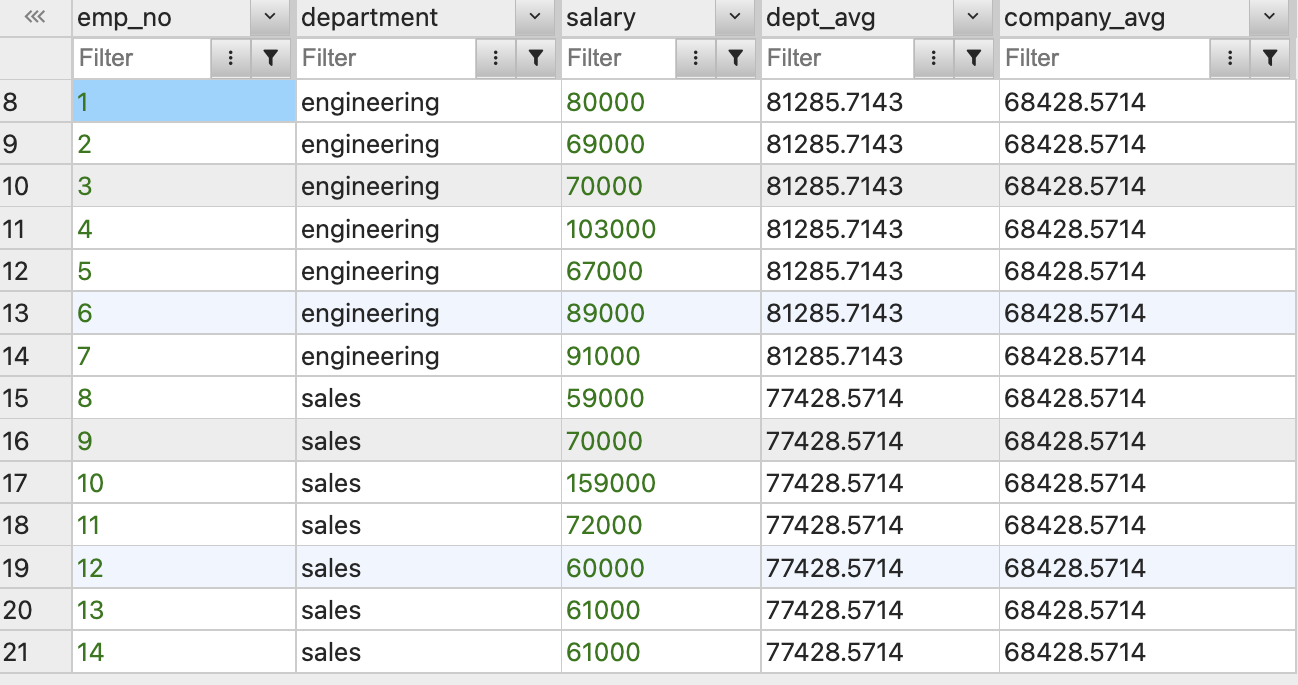
SELECT emp_no,
department,
salary,
AVG(salary) OVER(PARTITION BY department) AS dept_avg,
AVG(salary) OVER() AS company_avg
FROM employees;위 코드는 각 부서별 평균 급여, 회사 전체 평균 급여를 출력하는 코드다.
OVER에빈 괄호로 넣어주면 전체를 윈도우(그룹)로 만들어버리기 때문에 회사 전체 평균 급여값이 출력되는 것을 볼 수 있다.
연습문제
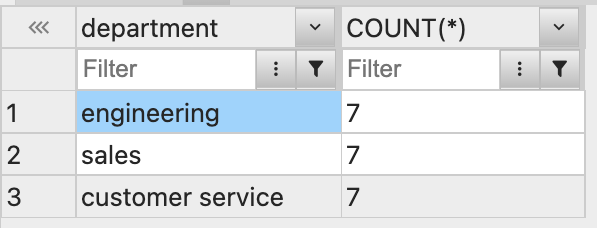
1️⃣ 각 부서의 직원이 몇 명인지 구해보자.
GROUP BY를 사용SELECT department, COUNT(*) FROM employees GROUP BY department;
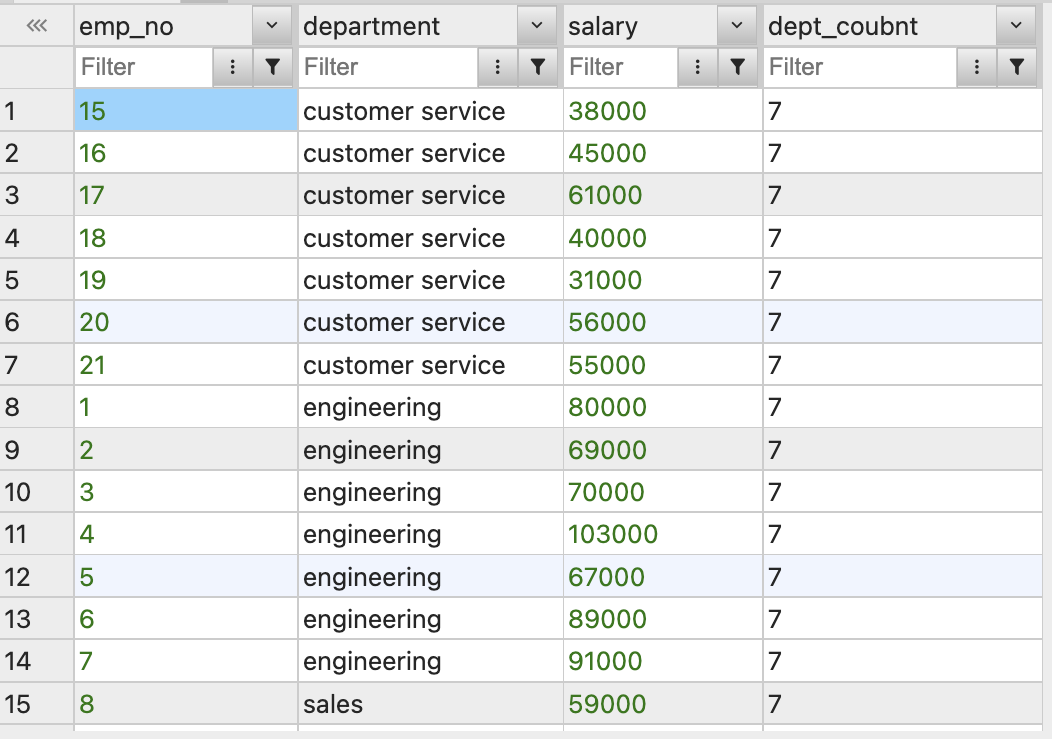
2.OVER(PARTITION BY ...)를 사용SELECT emp_no, department, salary, COUNT(*) OVER(PARTITION BY department) AS dept_count FROM employees;
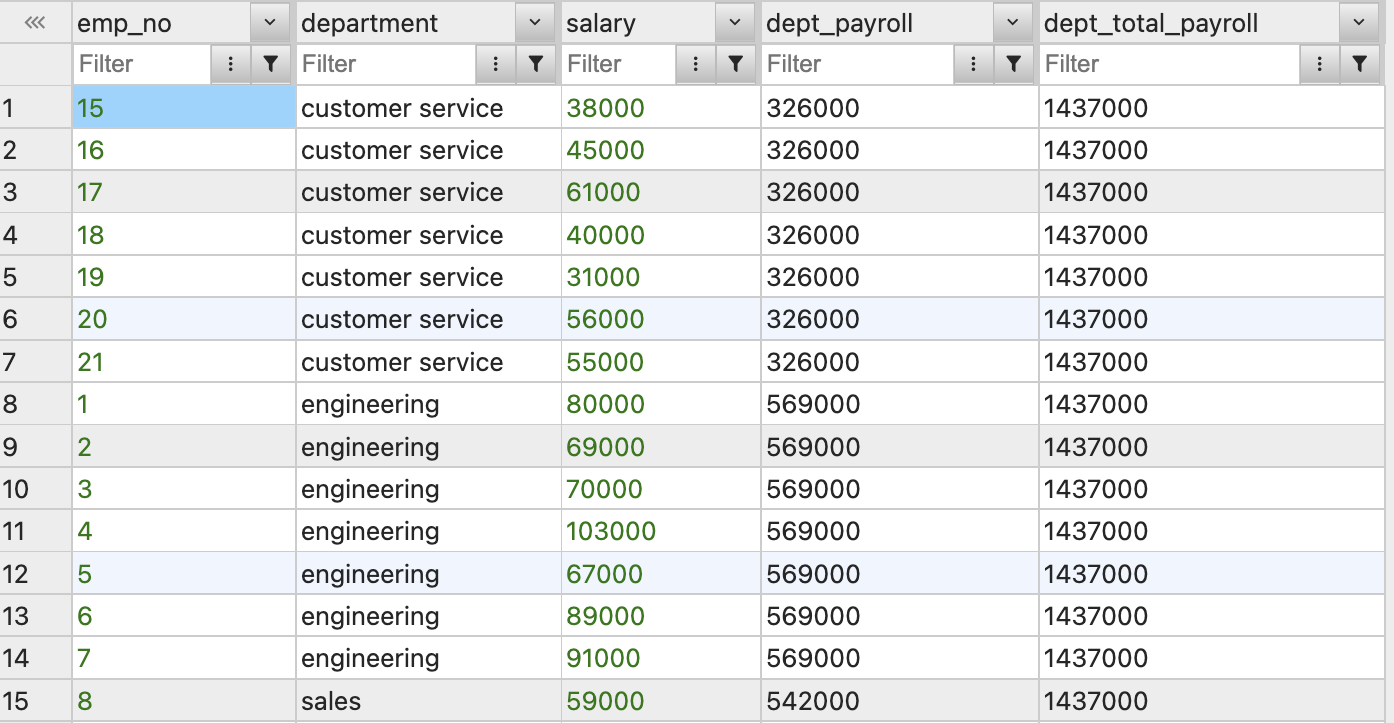
2️⃣ 각 부서별 급여 합산.
SELECT emp_no, department, salary, SUM(salary) OVER(PARTITION BY department) AS dept_payroll, SUM(salary) OVER() AS dept_total_payroll FROM employees;
ORDER BY
OVER절 안에 포함할 수 있는ORDER BY에 대해 알아보자.
OVER안에서 쓰이는 ORDER BY는 일반적인 ORDER BY와 조금 다르다.
행의 정렬 순서를 바꾼다는 점은 동일하다.
하지만 ORDER BY를 OVER 괄호 안에 포함하면 MySQL에 각 윈도우에 속한 행의 순서를 변경하라고 명령할 수 있다.
SELECT emp_no,
department,
salary,
SUM(salary) OVER(PARTITION BY department ORDER BY salary) AS rolling_dept_salary,
SUM(salary) OVER(PARTITION BY department) AS dept_payroll
FROM employees;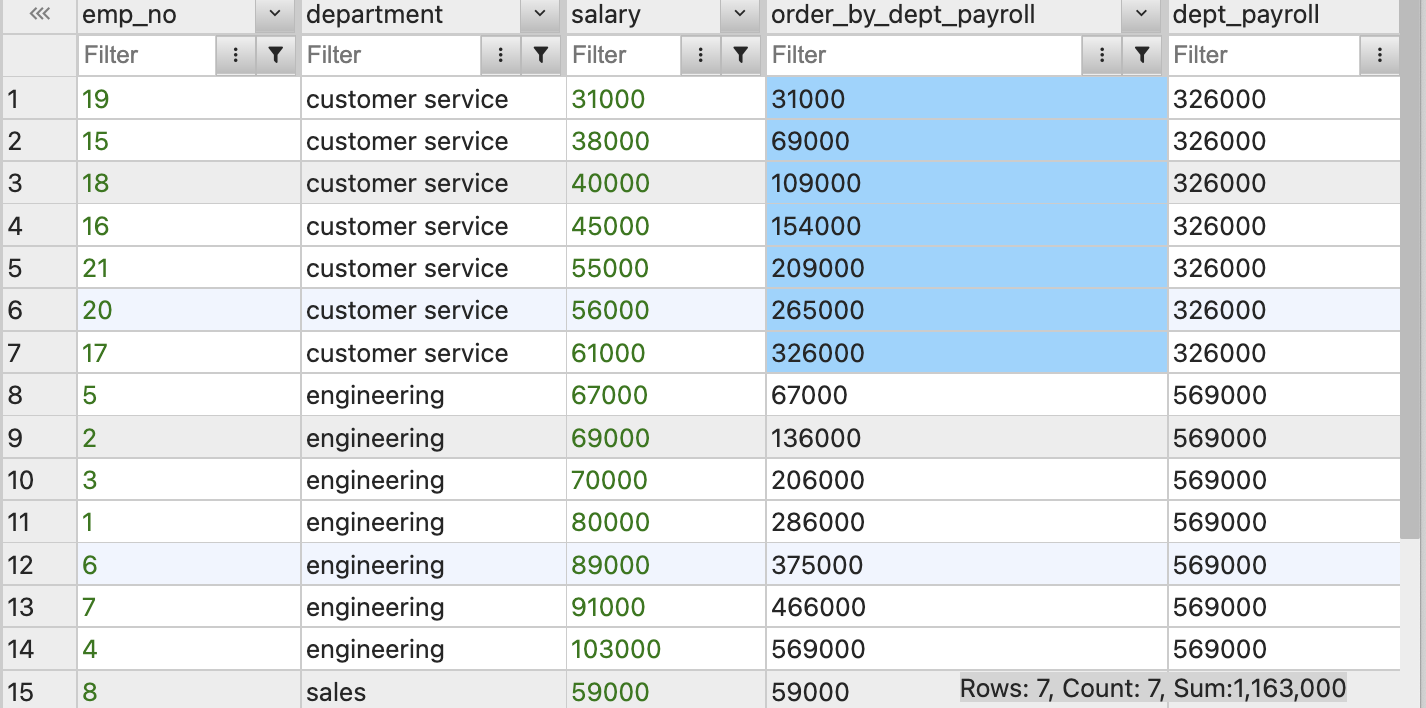
SUM(salary) OVER(PARTITION BY department ORDER BY salary) AS rolling_dept_salary
OVER 괄호 안에 ORDER BY를 사용하니 누적 합산(SUM 함수를 사용하고있어서 누적 합산)이 되는 것을 볼 수 있다.
RANK
Window Function
sum, average, min, max 등의 함수들은 집계 함수라고 한다. 이 집계 함수들은 GROUP BY와 함께 사용하거나 윈도우 함수로 사용할 수 있다.
하지만
RANK는 오로지윈도우 함수로만 사용할 수 있다.
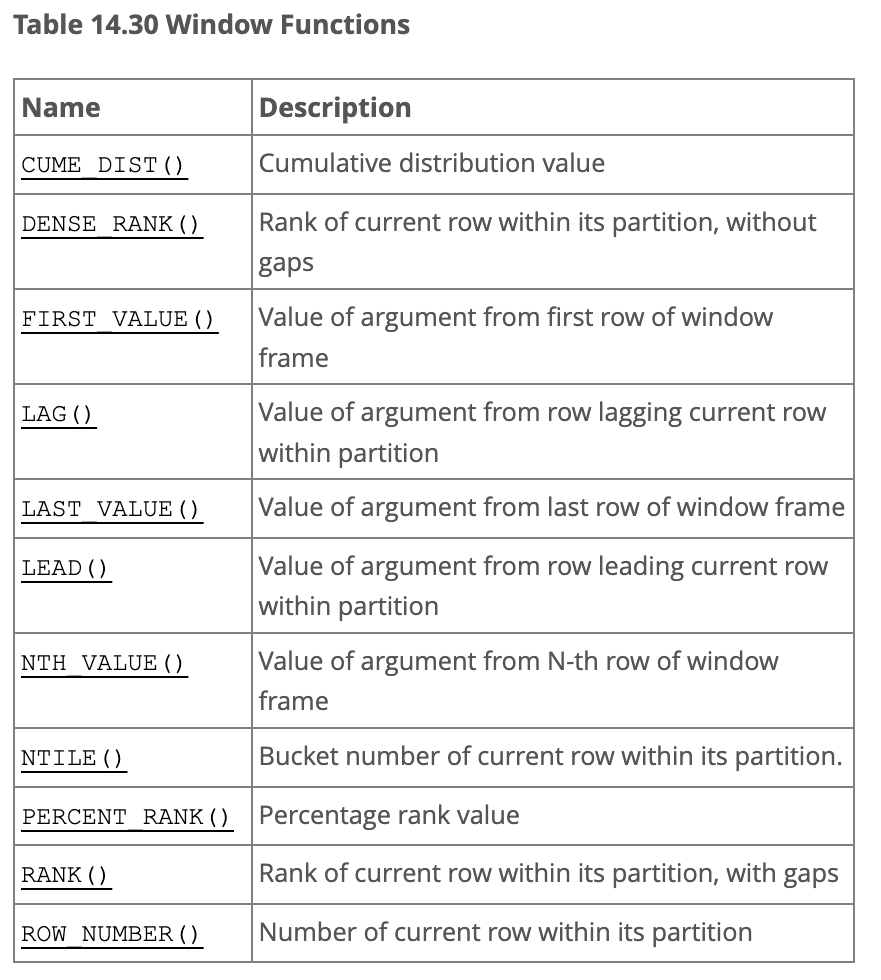
✅ RANK는 파티션 내에서의 현재 행에 대한 순위를 반환한다.
SELECT
emp_no,
department,
salary,
RANK() OVER(ORDER BY salary DESC) AS salary_rank
FROM employees;RANK 알고 넘어가야하는 사항
RANK는ROW_NUMBER와 같지 않다.
ROW_NUMBER는 단순히 연속된 행 번호를 제공한다.
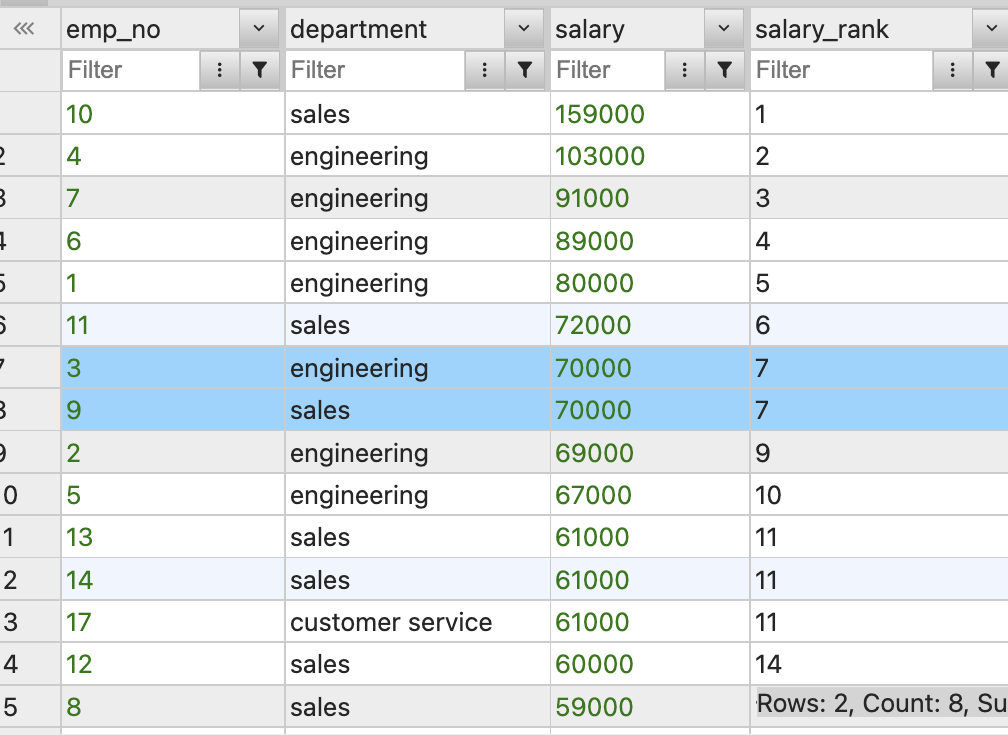
salary_rank값은 7로 동일하다.
RANK를 이용하면 윈도우 내에서 동일한 값들은 같은 순위로 간주된다.
따라서 행이 중복되거나 동점이 있는 경우에는 단지 행 수를 세는 것과 다르다.
부서별 급여 순위, 전체 급여 순위 출력
SELECT emp_no, department, salary, RANK() OVER(PARTITION BY department ORDER BY salary DESC) AS dept_salary_rank, RANK() OVER(ORDER BY salary DESC) AS salary_rank FROM employees;
ROW_NUMBER
ROW_NUMBER()는RANK와 다르게 동점을 허용하지 않는다.
값 자체를 살펴보지 않고 단순히 행을 세는 것에 그친다.
SELECT
emp_no,
department,
salary,
ROW_NUMBER() OVER(PARTITION BY department ORDER BY salary DESC) AS dept_row_number,
RANK() OVER(PARTITION BY department ORDER BY salary DESC) AS dept_salary_rank,
RANK() OVER(ORDER BY salary DESC) AS salary_rank
FROM employees ORDER BY department;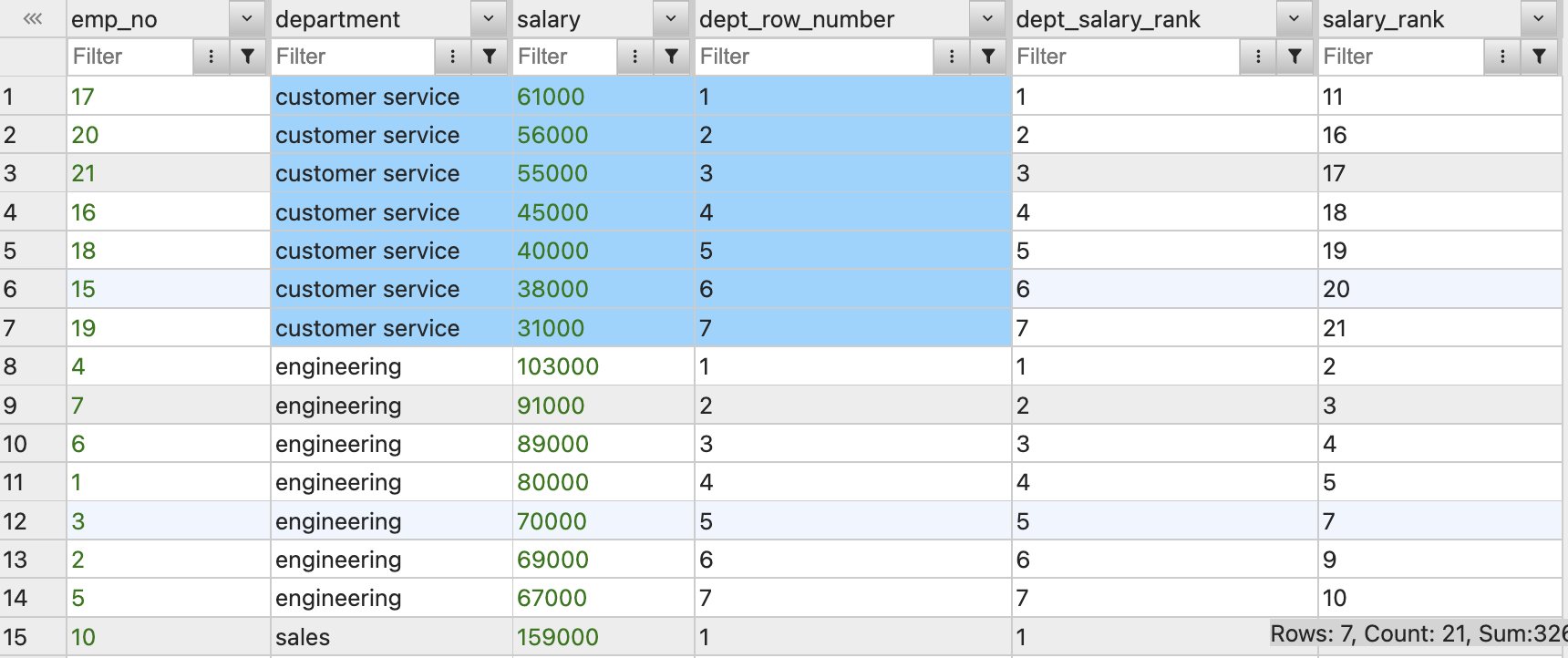
DENSE_RANK
RANK처럼 파티션 내에서 현재 행의 순위를 건너뜀 없이 반환한다.
하지만DENSE_RANK()의 경우 동점 그룹에 연속적인 순위를 할당하므로 값을 건너뛰지 않는다.
SELECT
emp_no,
department,
salary,
ROW_NUMBER() OVER(PARTITION BY department ORDER BY salary DESC) AS dept_row_number,
RANK() OVER(PARTITION BY department ORDER BY salary DESC) AS dept_salary_rank,
RANK() OVER(ORDER BY salary DESC) AS salary_rank,
DENSE_RANK() OVER(ORDER BY salary DESC) AS overroll_dense_rank
FROM employees ORDER BY overroll_dense_rank;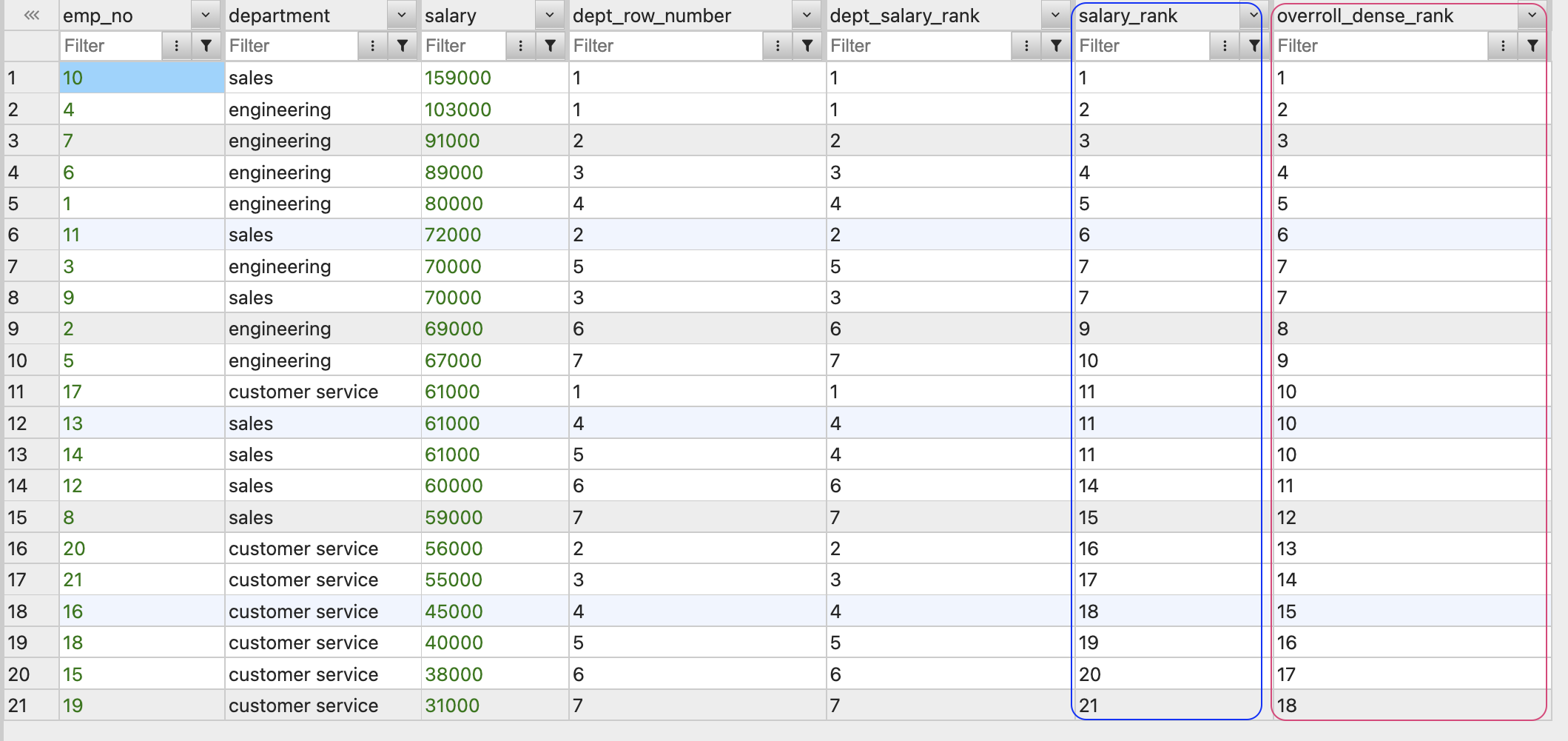
파란 선으로 영역지어놓은 RANK는 중복값을 허용하기 때문에 값이 순차적으로 이어지지 않고 생략되는 값이 있음을 확인할 수 있다.
EX : 7 / 7 / 9 / 9 / 11 ...
반면 빨간 선으로 영역지어놓은 DENSE_RANK()는 순위를 건너뜀 없이 반환하기 때문에 숫자의 순서가 끊김없는 것을 확인할 수 있다.
EX : 7 / 7 / 8 / 8 / 9 ...
NTILE();
NTILE(N)
숫자 N을 제공하면 이것이 값들이 분류될 버킷의 수가 된다. (1부터 N까지의 숫자를 반환한다.)
예를 들어 각 급여 파티션 내에서 4로 분할한다면, 급여에 대해 4개의 버킷이 생성되며 1부터 4까지의 숫자를 반환한다.
NTILE() 예시 코드
SELECT
emp_no,
department,
salary,
NTILE(4) OVER(ORDER BY salary DESC) as salary_quartile
FROM employees;NTILE(4)로 적용하여 salary를 1부터 4까지 숫자로 분할했다.
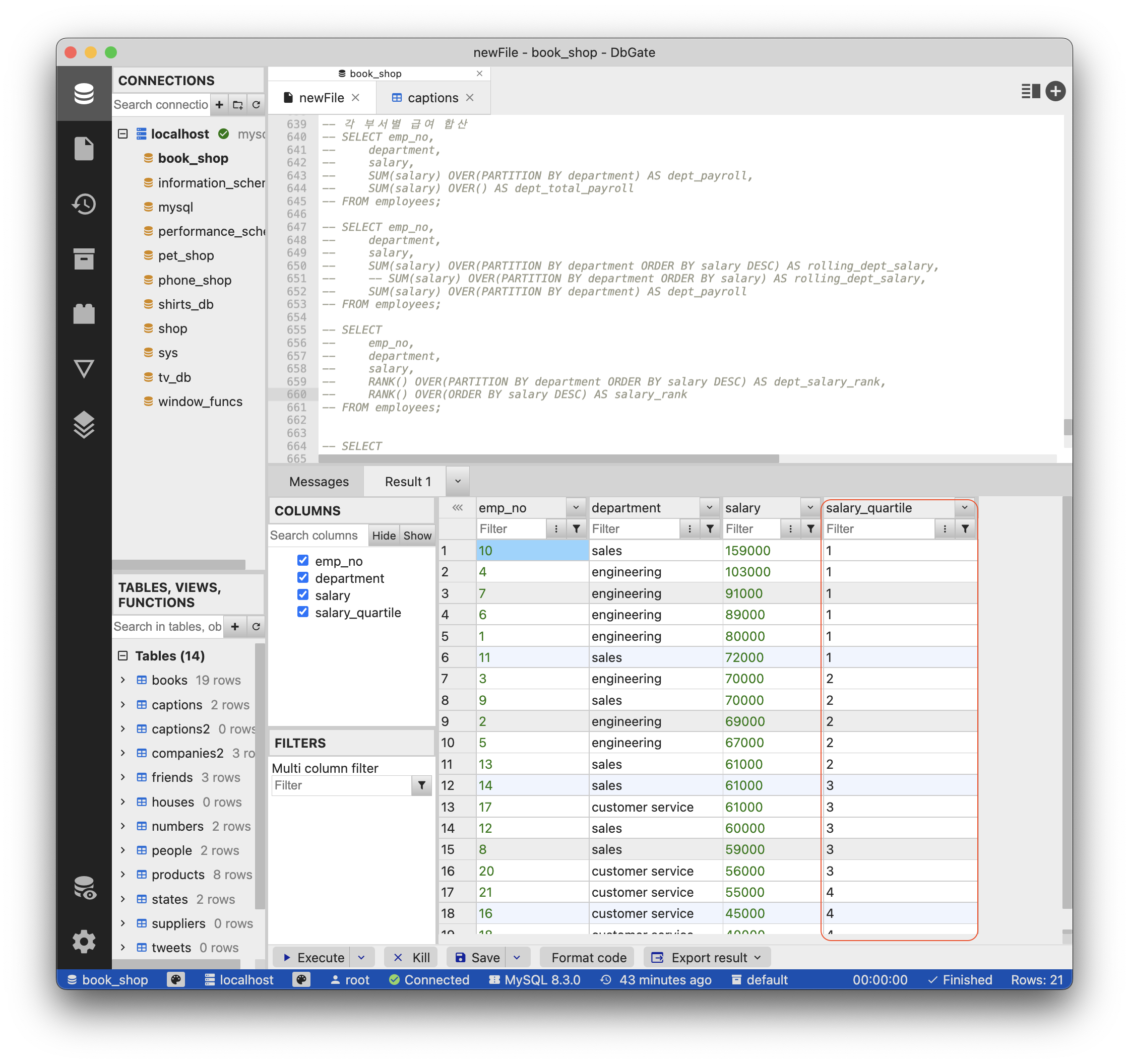
그 결과,salary를 기준으로 1부터 4까지 분위가 나누어짐을 확인할 수 있다.
해당 이미지에서 확인할 수 있는 것은 salary가 55000일 때 부터 4분위로 나누어진다.
✅ 부서 내에서 분위, 전체 분위를 표현할 수도 있다.
SELECT
emp_no,
department,
salary,
NTILE(4) OVER(PARTITION BY department ORDER BY salary DESC) as dept_salary_quartile,
NTILE(4) OVER(ORDER BY salary DESC) as salary_quartile
FROM employees;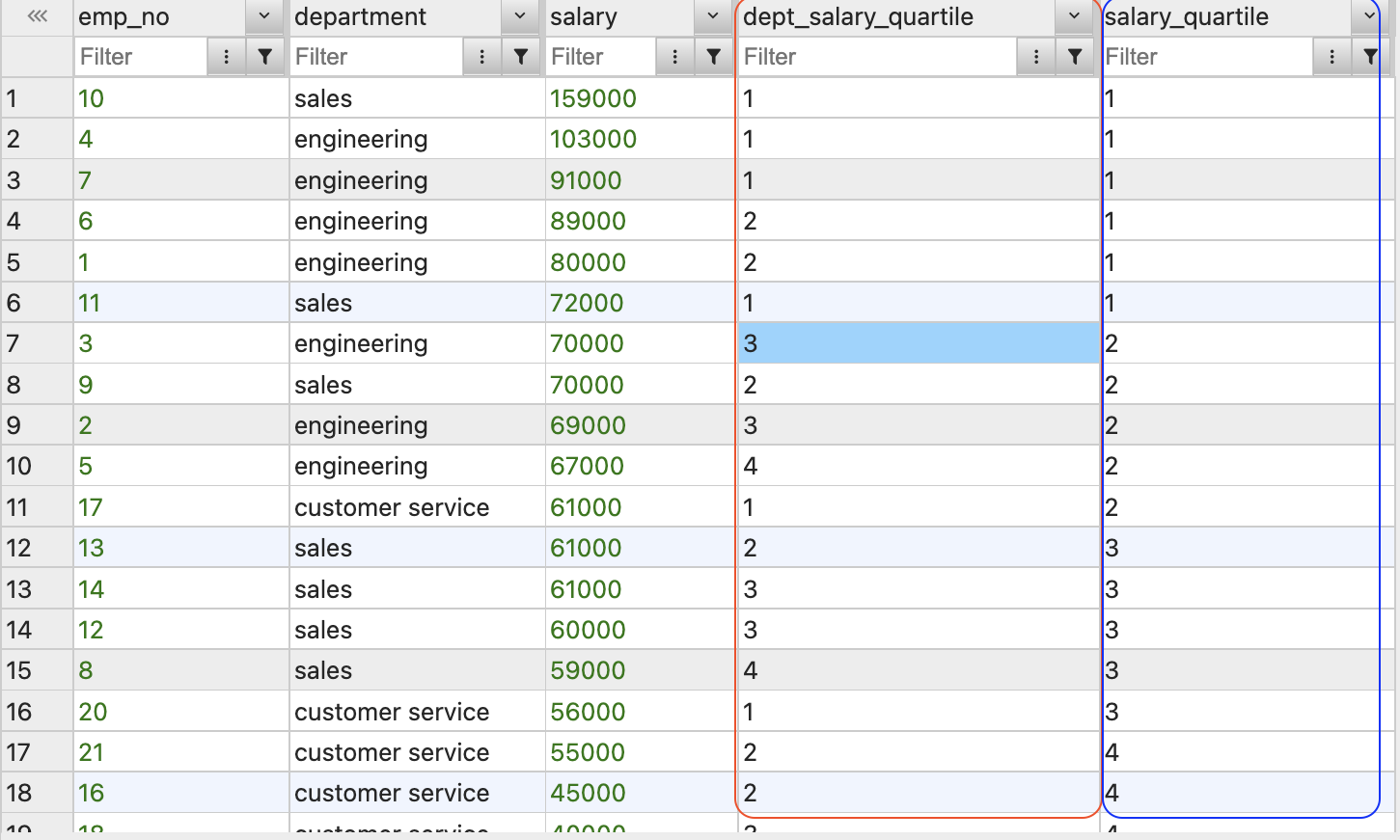
FIRST_VALUE()
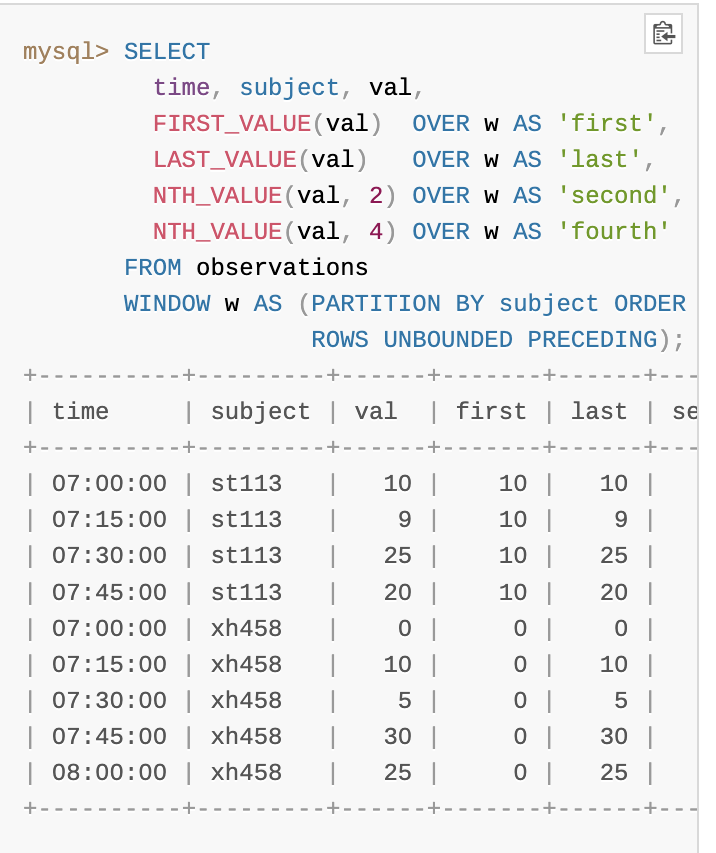
FIRST_VALUE()는 괄호 안에 있는 표현식의 값이 윈도우 프레임의 첫 번째 행에서 반환된다.
동일하게 사용할 수 있지만, 반대의 결과값을 출력하는LAST_VALUE()윈도우 함수도 있다.
NTH_VALUE()윈도우 함수는 표현식 뒤에 원하는 순서를 지정할 수 있다.
해당 윈도우 프레임의 N번째 행에서 전달한 표현식을 가져오는 방식이다.
SELECT
emp_no,
department,
salary,
FIRST_VALUE(emp_no) OVER(PARTITION BY department ORDER BY salary DESC) AS highest_paid_dept_emp_no,
FIRST_VALUE(emp_no) OVER(ORDER BY salary DESC) AS highest_paid_total_emp_no
FROM employees ORDER BY department;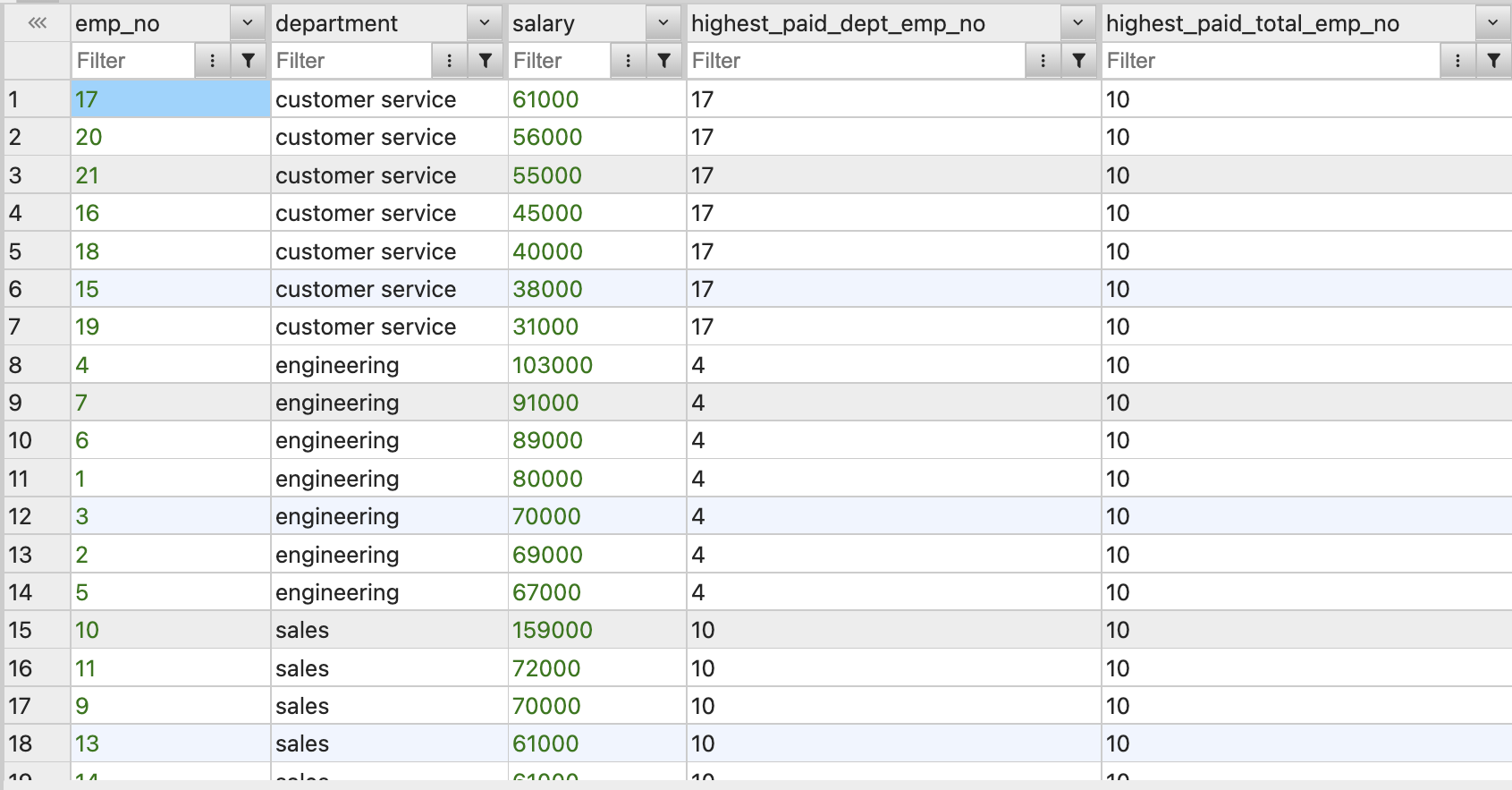
해당 코드는 부서별로 가장 급여를 많이 받는 직원의 emp_no, 전체 최다 급여 직원의 emp_no를 찾을 수 있는 코드이다.
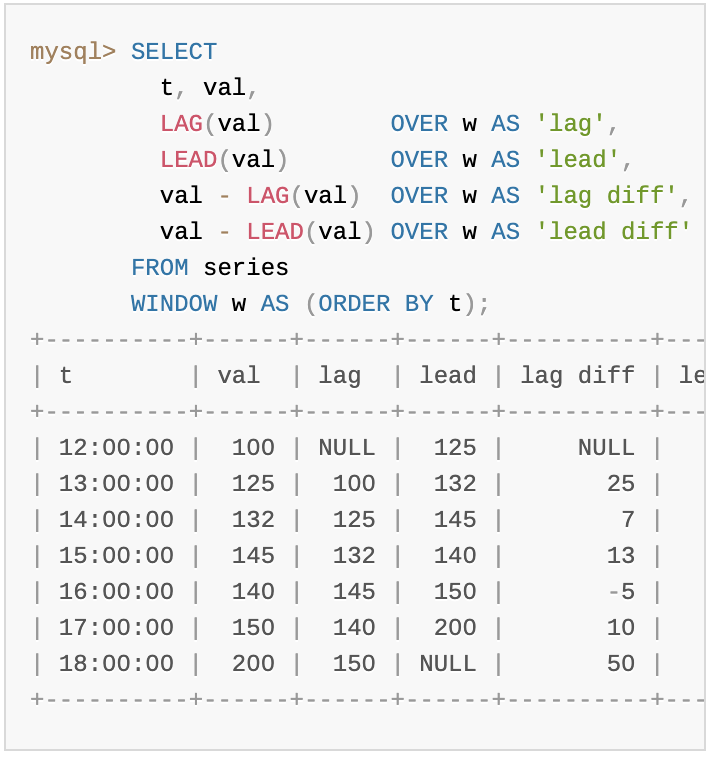
LEAD() | LAG()
해당 윈도우 함수들은 ⭐️ 주로 한 행과 그 전 or 다음 행 간의 차이를 찾기 위해 사용된다.
LAG를 사용한다면 이전 행에서 그 표현식의 값을 반환하고,
LEAD를 사용한다면 다음 행에서 그 표현식의 값을 반환한다.
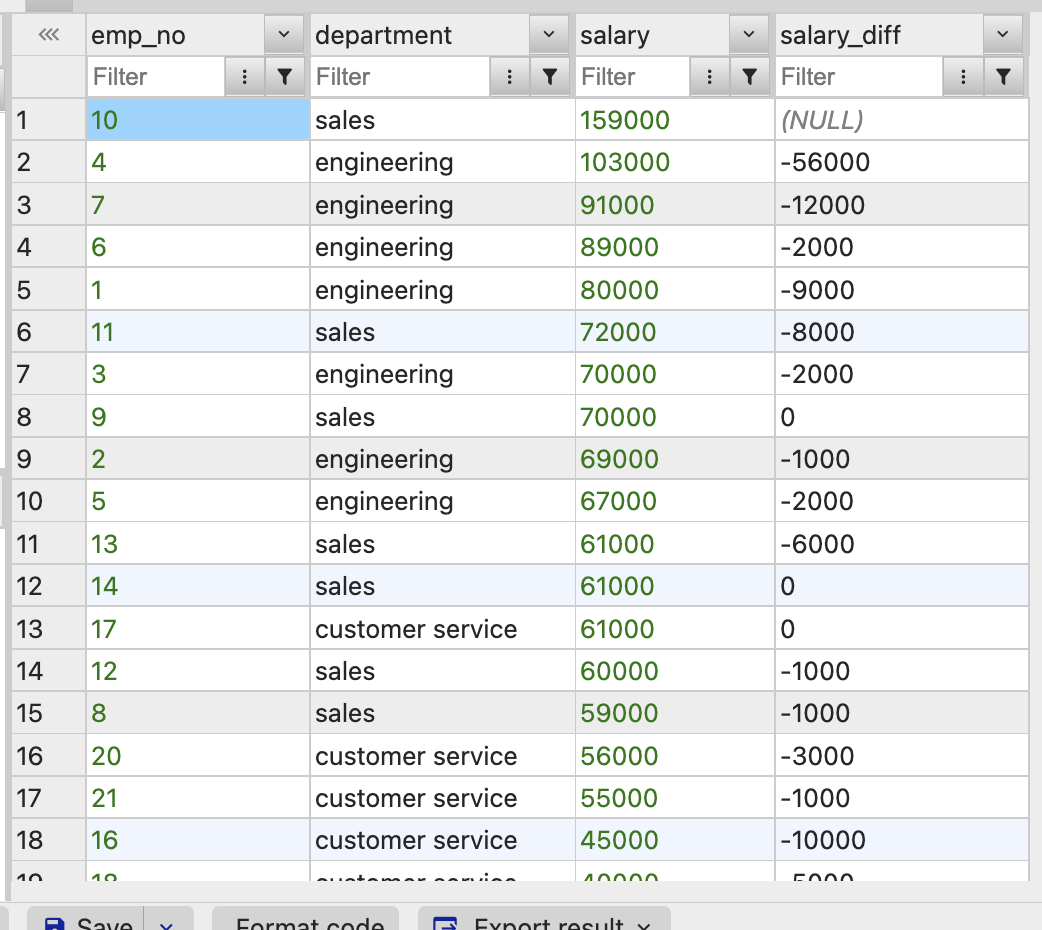
이를 이용하여 급여 차이를 계산할 수도 있다.
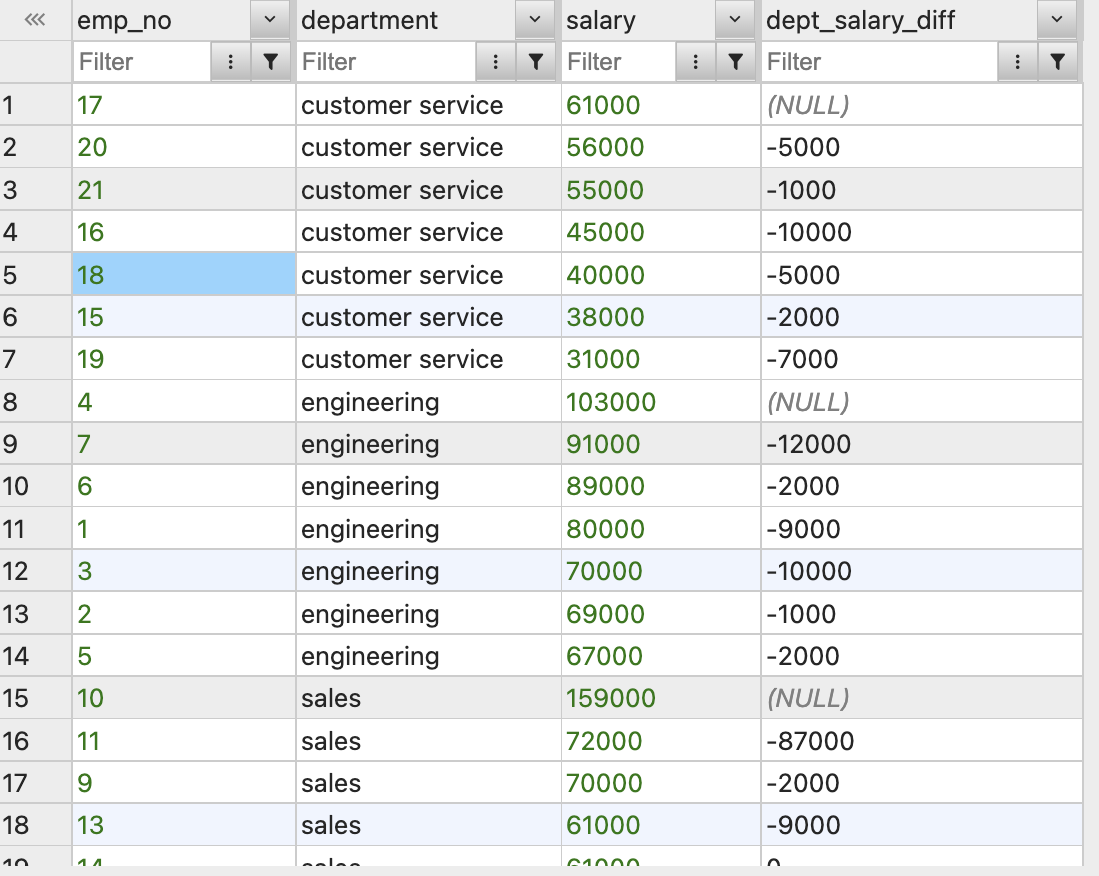
-- 행들 간의 급여 차이 계산 (급여 - 이전 행의 급여)
SELECT
emp_no,
department,
salary,
salary - LAG(salary) OVER(ORDER BY salary DESC) AS salary_diff
FROM employees;(전 행과 비교 LAG())
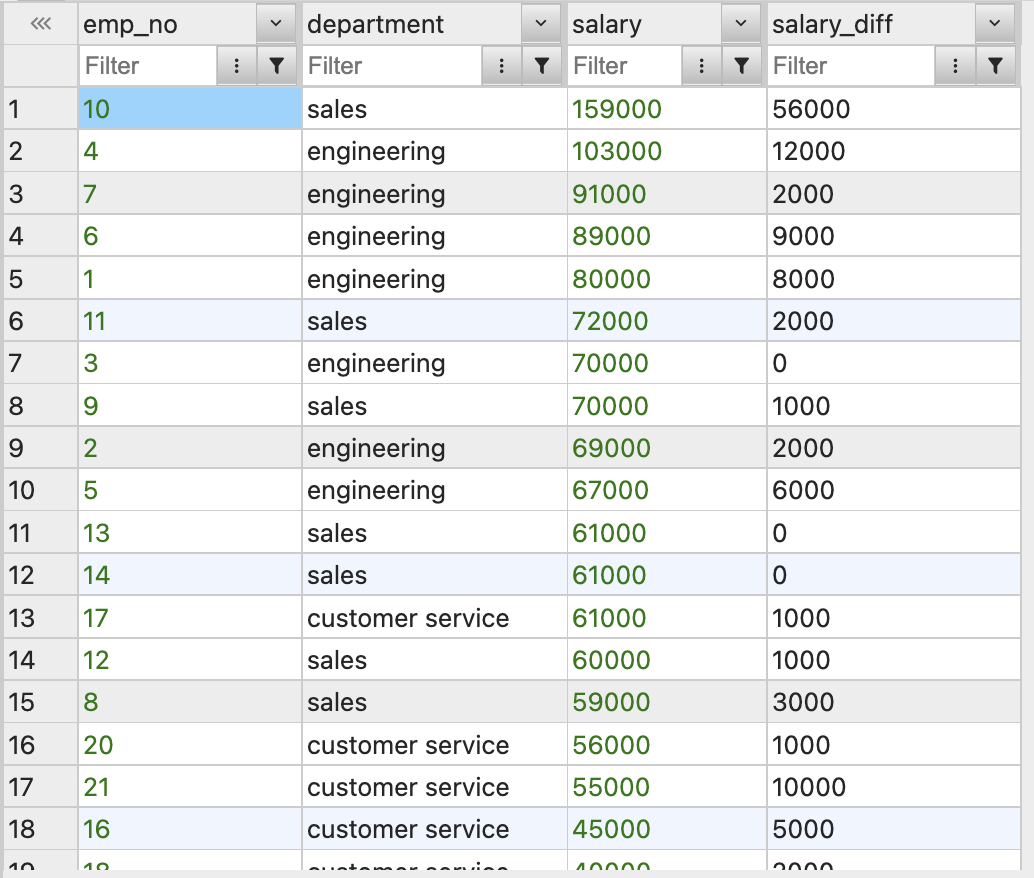
-- 행들 간의 급여 차이 계산 (급여 - 앞의 행의 급여)
SELECT
emp_no,
department,
salary,
salary - LEAD(salary) OVER(ORDER BY salary DESC) AS salary_diff
FROM employees;(앞 행과 비교LEAD())
부서별로 파티션을 두어 급여 차이를 알 수도 있다.
-- 부서간 급여 차이
SELECT
emp_no,
department,
salary,
salary - LAG(salary) OVER(PARTITION BY department ORDER BY salary DESC) AS dept_salary_diff
FROM employees;