
안녕하세요! 이번 포스팅은 Oracle DB를 활용하는 SQL 두번째 포스팅입니다.
이전 포스팅에서 개발환경을 구축하는 방법과 테이블 생성방법, 자료 삽입 방법, 자료형 등에 대해 살펴봤습니다.
개발환경을 구축하는 것만 해도 원래는 진땀 빼는 일이지만 macOS에서 별도의 우회책이 있어 다행인 것 같습니다.
이번 포스팅에서 살펴볼 내용은 가상테이블, 조건문, 연산자, 정렬, 그룹화, 그룹함수입니다.
자 그러면 본격적으로 시작해보겠습니다.
가상 테이블
가상 테이블이란?
우리가 콘솔에서 테이블 만들어달라고 쿼리문을 작성하면
CREATE TABLE TB1(
COL1 VARCHAR2,
COL2 NUMBER,
COL3 LONG
);선언한 구조대로 테이블이 생성되고 프로젝트 파일로 저장됩니다.
만약에 단순히 입력되는 내용만 보고 없애고 싶은데 새로운 표를 생성해서 잠시 사용하고 지우는 일은, 이러한 경우가 많아진다고 할 때 매우 번거로운 일이 아닐 수 없습니다.
그래서 우리는 가상 테이블을 생성해서 결과만 보는 표를 만들 수 있으며 이는 프로젝트로 생성되지 않습니다.
가상 테이블 만들기
가상 테이블은 DUAL로 만들 수 있습니다.
SELECT 컬럼명 FROM DUAL;SELECT 1 FROM DUAL;위와 같이 쿼리문을 작성하면
| 1 |
|---|
| 1 |
이와 같은 표가 작성됩니다.
1이라는 행을 가진 칸을 1개 만들어줍니다.
그리고
SELECT 1, 'A' FROM DUAL;이렇게 작성해주면
| 1 | 'A' |
|---|---|
| 1 | A |
이렇게 두개의 내용이 들어갑니다.
맨 위에 있는 것은 컬럼명이 별도로 들어간 것이므로 신경 쓰지 않으셔도 됩니다.
마지막으로
SELECT TO_DATE ('20211222', 'YYYY-MM-DD') FROM DUAL;이렇게 작성해주면 어떻게 될까요? 참고로 TO_DATE는 입력 받은 날짜를 형식에 맞게 바꿔주는 함수입니다.
| TO_DATE('20211222','YYYY-MM-DD') |
|---|
| 2021-11-22 |
이렇게 되겠지요?
조건문 WHERE과 비교 연산자
기본 개념
자바에서 사용하는 조건문은 if문과 switch case문 이었습니다.
오라클에서도 이와 같이 WHERE라는 조건문이 있습니다.
SELECT 컬럼명 FROM 테이블명 WHERE 조건이렇게 어떤 조건이 성립할 때 SELECT한 것을 조건에 맞게 보여달라는 의미가 됩니다.
비교 연산자도 존재하는데 자바에서 살펴본 비교연산자와 동일합니다. 그렇지만 자바에는 없는 딱 하나의 비교연산자가 있습니다.
| 연산자 | 의미 |
|---|---|
> | 크다 |
< | 작다 |
>= | 크거나 같다 |
<= | 작거나 같다 |
= | 같다 |
!= | 다르다 |
<> | 다르다(!=과 같음) |
사용하기
우리가 실습을 위해 받은 파일에서 이름이 Julia라는 사람을 찾아봅시다.
SELECT FIRST_NAME, LAST_NAME
FROM EMPLOYEES
WHERE FIRST_NAME = 'Julia';이렇게 테이블에서 어떤 것을 선택하고, 그 다음으로 조건을 검사해서 해당하는 내용을 보여줍니다.
급여가 9000이상인 사람을 찾아봅시다.
SELECT FIRST_NAME, SALARY
FROM EMPLOYEES
WHERE SALARY >= 9000;문자열의 순서 비교하기
SQL에서 연산자는 단지 숫자에 한해서만 비교해주지 않습니다.
SELECT FIRST_NAME
FROM EMPLOYEES
WHERE FIRST_NAME > 'Shanta';이렇게 하면 Shanta 다음의 이름부터 보여주게 됩니다.
A, B, C 순서로 정리해서 Shanta 다음으로 올 알파벳을 가진 이름들을 보여줍니다.
IS NULL과 IS NOT NULL
자바에서는 어떤 값이나 객체가 null이라고 하는 것을 표현해 줄 때 다음과 같이 해주었습니다.
int[] myArray = null;SQL에서는 = null이나 != null과 같은 방법으로 선언할 수 없습니다.
예를 들어서 EMPLOYEES에서 MANAGER_ID가 없는 사람의 FIRST_NAME을 보여달라고 한다면
SELECT FIRST_NAME FROM EMPLOYEES
WHERE MANAGER_ID IS NULL;이렇게 MANAGER_ID = NULL이 아니라 MANAGER_ID IS NULL로 해주어야 정확하게 인식합니다.
반대로 != NULL도 비교 연산자를 쓰지 않고 IS NOT NULL이라고 써야 합니다.
SELECT FIRST_NAME, COMMISSION_PCT FROM EMPLOYEES
WHERE COMMISSION_PCT IS NOT NULL;<>과 !=
<>는 SQL에 있는 비교 연산자로 '같지 않다'의 의미입니다.
그래서 아래 두개의 쿼리문은 같은 의미입니다.
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE SALARY != 9000;
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE SALARY <> 9000;논리 연산자
기본 개념
논리연산자, 자바에서는 &&와 ||가 있었습니다. 연산자 앞뒤의 조건이 모두 참이어야 true이거나 둘 중 하나만 참이면 true인 연산자였죠.
SQL에서는 AND와 OR가 그 역할을 합니다. 비슷한 것으로 ALL과 ANY가 있는데 ALL이 AND와 유사하고 ANY가 OR와 유사합니다.
| 연산자 | 의미 |
|---|---|
AND | 앞 뒤에 오는 모든 것이 true일 때 true |
OR | 앞 뒤에 오는 것 중 하나라도 true일 때 true |
ALL | AND와 비슷한 역할 |
ANY | OR와 비슷한 역할 |
사용하기
그렇다면 EMPLOYEES에서 FIRST_NAME이 'Shanta'이고 LAST_NAME이 'Vollman'인 사람을 찾아달라고 할 때 어떻게 할 수 있을까요?
SELECT * FROM EMPLOYEES
WHERE FIRST_NAME = 'Shanta' AND LAST_NAME = 'Vollman';이렇게 각각의 컬럼에서 해당하는 이름을 찾아달라고 할 수 있습니다.
FIRST_NAME이 John이고 SALARY가 5000이상인 사람을 찾는다면
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE FIRST_NAME = 'John' AND SALARY >= 5000;반대로
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE FIRST_NAME = 'John' OR SALARY >= 5000;이렇게 OR를 써주면 FIRST_NAME이 John이거나 SALARY가 5000이상인 모든 사람을 보여줍니다.
ALL과 ANY는 AND, OR와 무엇이 다를까?
유사한 역할을 하지만 작성하는 방법과 의미가 조금 다릅니다.
예를 들어서 FIRST_NAME이 Shanta이고 John인 사람을 찾으라고 하면
SELECT * FROM EMPLOYEES
WHERE FIRST_NAME = 'Shanta' AND FIRST_NAME = 'John';AND는 각각 비교해줘야 하지만 ALL은 한번에 비교할 수 있습니다.
SELECT * FROM EMPLOYEES
WHERE FIRST_NAME = ALL('Shanta', 'John');단, 한번에 하나의 컬럼에 대한 조건만 비교할 수 있어서 여러 컬럼에 대해 비교해야 한다면 차라리 AND를 쓰는게 낫습니다.
이렇게 ANY를 써주면 FIRST_NAME이 Shanta이거나 John인 경우를 다 보여줍니다.
SELECT * FROM EMPLOYEES
WHERE FIRST_NAME = ANY('Shanta', 'John');포함관계를 나타내는 연산자
기본 개념
컬럼 내부에서 특정 내용을 다 뽑아서 보고 싶을 때 사용할 수 있는 연산자가 있습니다.
바로 IN과 NOT IN입니다.
IN(5000, 40)은 5000과 40을 담고 있는 특정 칼럼을 보여달라는 것을 의미합니다.
다시 말해서 5000을 담고 있거나 40을 담고 있는 자료를 모두 보여주는 것입니다.
NOT IN은 그 반대겠지요?
사용하기
예를 들어 SALARY에 8000, 3200, 6000을 담고 있는 내용을 보고 싶다고 한다면 조건구문에 붙여서 쓸 수 있습니다.
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE SALARY IN (8000, 3200, 6000);WHERE SALARY IN (8000, 3200, 6000);는 SALARY = 8000 OR SALARY = 3200 OR SALARY = 6000과 같은 의미겠지요!
위와 같이 쿼리문을 작성해주면 SALARY가 8000, 3200, 6000인 것에 대해 FIRST_NAME과 SALARY를 보여주겠지요?
반대로
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE SALARY NOT IN (8000, 3200, 6000);이렇게 쓰면 8000, 3200, 6000을 제외한 FIRST_NAME과 SALARY를 보여줍니다.
숫자 뿐만 아니라 문자열도 적용할 수 있습니다.
SELECT FIRST_NAME FROM EMPLOYEES
WHERE FIRST_NAME IN ('Julia', 'John');FIRST_NAME에 Julia나 John이 있는 자료만 보여줄 것입니다.
범위 연산자
기본 개념
A와 B사이라는 것을 영어로 하면 BETWEEN A AND B라고 나타냅니다.
SQL에서 어떤 값에 대해 범위를 지정해줄 때 BETWEEN A AND B를 사용할 수 있습니다.
예를 들어서 FIRST_NAME, SALARY를 보여주는데 조건은 SALARY >= 3200 이고 SALARY <= 9000일 때라면 이제까지 우리가 살펴본 방법대로 작성할 때 아래와 같이 작성할 수 있습니다.
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE SALARY >= 3200 AND SALARY <= 9000;사용 하기
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE SALARY >= 3200 AND SALARY <= 9000;이러한 조건문을 조금 더 간결하게 써주는 것이 바로 BETWEEN A AND B입니다.
아래와 같이 SALARY >= 3200 AND SALARY <= 9000을 SALARY BETWEEN 3200 AND 9000로 바꿔 쓸 수 있습니다.
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE SALARY BETWEEN 3200 AND 9000;한편, BETWEEN A AND B의 부정은 BETWEEN 앞에 NOT을 붙여서 NOT BETWEEN A AND B로 써줍니다.
위의 쿼리문을 토대로 BETWEEN을 부정해보겠습니다.
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE SALARY NOT BETWEEN 3200 AND 9000;주의사항
BETWEEN A AND B는 AND라는 논리 연산자를 사용하기 때문에 조건절에 다양한 조건이 들어갈 때는 사용에 유의해야 합니다.
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE SALARY BETWEEN 3200 AND 9000 AND FIRST_NAME = John;과 같이 쿼리문을 작성한다면 연산이 꼬일 수 있기 때문에 괄호를 쳐서 연산의 우선순위를 결정해주어야 합니다.
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
WHERE (SALARY BETWEEN 3200 AND 9000) AND FIRST_NAME = John;LIKE 연산자
기본 개념
LIKE 연산자는 컬럼의 내용이 특정 패턴에 맞는지 필터링 해줍니다.
값의 일부에 대한 일치 여부를 검색할 수 있지요.
기본 형식은 아래와 같습니다.
SELECT * FROM 테이블명 WHERE 컬럼명 LIKE 패턴;사용 하기
실습 파일의 컬럼 FIRST_NAME에서 이름에 G?ra?d가 들어가는 사람을 찾고 싶어합니다. 이 때 ?는 모르는 글자입니다. 어떻게 찾을 수 있을까요?
값의 일부가 일치하는 것을 따로 뽑아낼 수 있는 연산자, LIKE를 쓰면 됩니다!!
SELECT FIRST_NAME FROM EMPLOYEES
WHERE FIRST_NAME LIKE 'G_ra_d'; 그러면 FIRST_NAME의 Gerald와 Girard를 찾아 줄 것입니다.
이 때 언더바_는 한 글자를 의미합니다. 그렇다면 K??????y나 ?????y, K?????? 같이 글자수를 특정하지 않는다고 가정한다면 무제한으로 언더바를 표시해 주어야 할까요?
그렇지 않습니다.
LIKE와 % 기호를 쓰면 되는데요, 예를 들어서 K???????y에 해당하는 컬럼을 뽑아달라는 쿼리문을 작성한다면
SELECT FIRST_NAME FROM EMPLOYEES
WHERE FIRST_NAME LIKE 'K%y';처럼 작성할 수 있습니다.
이는 숫자도, 문자도 모두 다 사용할 수 있습니다.
SELECT FIRST_NAME FROM EMPLOYEES
WHERE FIRST_NAME LIKE 'A%'; -- 첫글자가 A인 사람 전부
SELECT FIRST_NAME FROM EMPLOYEES
WHERE FIRST_NAME LIKE '%y'; -- 마지막 글자가 y인 사람 전부
SELECT FIRST_NAME FROM EMPLOYEES
WHERE FIRST_NAME LIKE '%e%'; -- 이름 철자 가운데 e가 들어가는 사람 전부
SELECT FIRST_NAME, HIRE_DATE FROM EMPLOYEES
WHERE HIRE_DATE LIKE '06%';
SELECT FIRST_NAME, PHONE_NUMBER FROM EMPLOYEES
WHERE PHONE_NUMBER LIKE '590%';정렬하기
기본 개념
데이터를 어떤 기준을 두어 배치하는 것을 정렬이라고 합니다. SQL에서 정렬은 ORDER BY 절을 통해 할 수 있습니다.
여러 개의 컬럼으로 정렬할 수 있고, 기본적으로 오름차순으로 정리됩니다. 이 때 ASC라는 정렬의 기준이 되는 값이 적용되며 이는 기본값입니다. 내림차순 정렬은 DESC로 할 수 있습니다.
선택되지 않은 컬럼으로도 정렬할 수 있습니다.
ORDER BY 컬럼명 정렬방법;사용하기
예를 들어 우리의 실습 파일에서 사람의 이름과 급여정보를 보여주는데 급여의 오름차순으로 나열하고 싶다고 한다면
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
ORDER BY SALARY ASC;이를 내림차순으로 정렬한다면
SELECT FIRST_NAME, SALARY FROM EMPLOYEES
ORDER BY SALARY DESC;과 같이 쿼리문을 작성할 수 있습니다.
별칭(ALIAS)을 붙인 컬럼의 별칭을 사용해서도 적용할 수 있습니다.
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY * 12 ANNUAL FROM EMPLOYEES
ORDER BY ANNUAL DESC;NULL 값 정렬하기
기본적으로 오라클에서는 NULL 값은 마지막에 정렬됩니다. NULL 값을 처음에 정렬되게 하기 위해서는 ORDERD BY 컬럼명 NULLS FIRST라고 해주면 NULL 값이 처음으로 정렬되어 나옵니다.
반대로 ORDERD BY 컬럼명 NULLS LAST는 NULL이 마지막에 정렬되어 나옵니다.
SELECT COMMISSION_PCT FROM EMPLOYEES
ORDER BY COMMISSION_PCT NULLS LAST;다양한 컬럼 정렬 시도해보기
정렬을 꼭 하나의 컬럼을 기준으로만 하라는 법은 없습니다. 다양한 컬럼을 동시에 정렬해 줄 수 있는데 아래의 예시를 살펴보도록 하겠습니다.
SELECT COMMISSION_PCT, SALARY FROM EMPLOYEES
ORDER BY COMMISSION_PCT NULLS LAST, SALARY DESC;
SELECT HIRE_DATE, SALARY, JOB_ID FROM EMPLOYEES
ORDER BY HIRE_DATE ASC, SALARY DESC;
SELECT JOB_ID, SALARY FROM EMPLOYEES
ORDER BY JOB_ID ASC, SALARY DESC;위 쿼리문에서 ORDER BY만 뽑아서 가져오면 각각 다음과 같습니다.
ORDER BY COMMISSION_PCT NULLS LAST, SALARY DESC;COMMISSION_PCT를 오름차순으로해서 NULL을 마지막으로 보내고 SALARY는 내림차순으로 정렬한다.
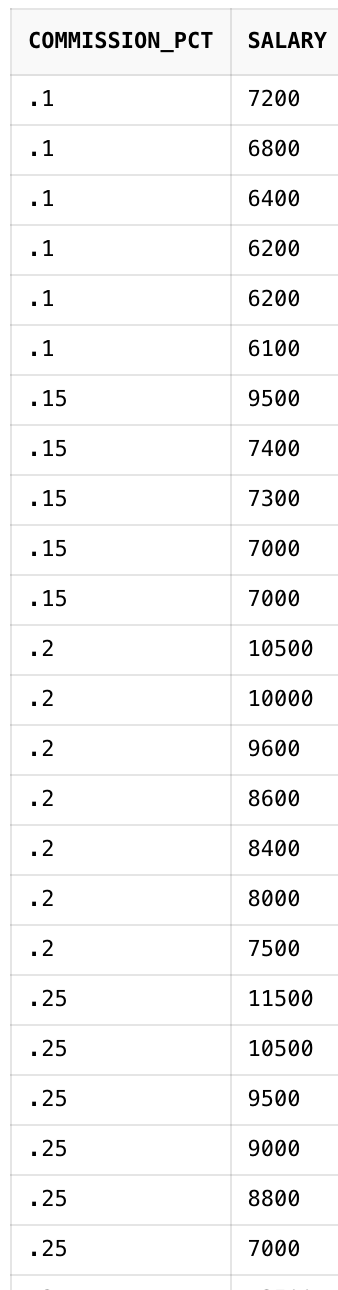
이런식으로 정렬이 될 것입니다(표가 길어서 다 보이지는 않습니다).
그러면 그 다음 쿼리문은 어떨까요?
ORDER BY HIRE_DATE ASC, SALARY DESC;HIRE_DATE를 오름차순으로, SALARY를 다시 내림차순으로 정렬합니다.
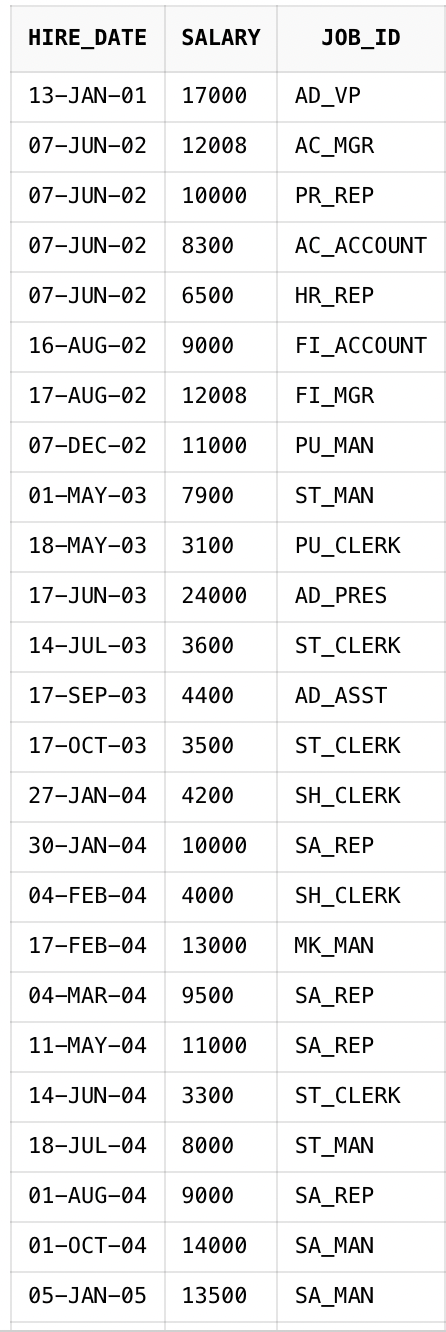
마찬가지로 표가 길어서 정렬된 모든 항목을 볼 수는 없지만 의도한대로 정렬이 되는 것 같습니다.
마지막으로
ORDER BY JOB_ID ASC, SALARY DESC;이렇게 작성한다면 JOB_ID는 오름차순, SALARY는 내림차순으로 정렬하게 합니다.
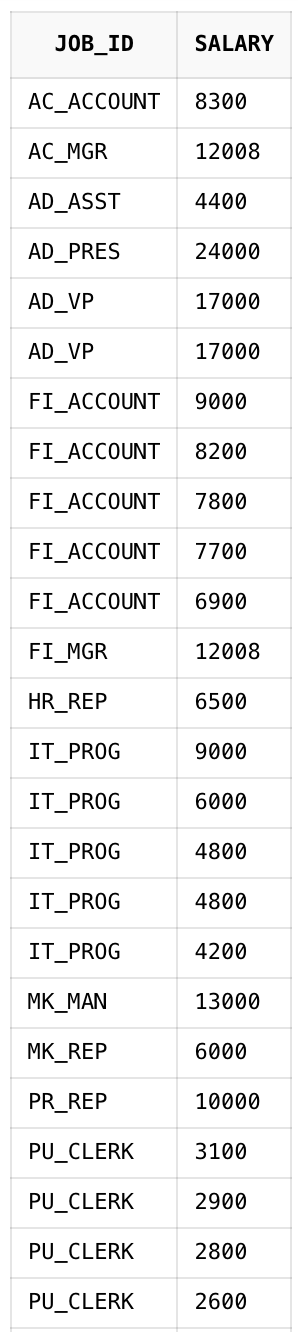
그룹화
기본 개념
그룹화라는 개념은 같은 속성이나 값을 기준으로 공통된 것끼리 묶는 행위를 말합니다.
50이라는 숫자가 100개, 60이라는 숫자가 1,000개 있다면 각각 50과 60으로만 나타내는 것이지요.
테이블상의 데이터도 마찬가지로 그룹화할 수 있는데 이 때 다음과 같이 나타냅니다.
SELECT * FROM 테이블명
ORDER BY 그룹화_할_컬럼명또한 그룹화한 컬럼에 별도의 조건을 걸 수 있는데 이 때, WHERE가 아닌 HAVING을 씁니다.
WHERE는 그룹화 하기 전의 조건 HAVING은 그룹화 이후의 조건이라고 보면 됩니다.
사용하기
SELECT DEPARTMENT_ID FROM EMPLOYEES;라고 쿼리문을 작성한 후 실행시켜주면 DEPARTMENT_ID가 여러개 나옵니다. 여기에서 중복되는 항목들이 있는데요.
이들을 하나로 묶어주겠습니다.
이 때 우리는 다음과 같이 쿼리문을 작성할 수 있습니다.
SELECT DEPARTMENT_ID FROM EMPLOYEES
GROUP BY DEPARTMENT_ID;DEPARTMENT_ID를 그룹화 하기 위해 GROUP BY DEPARTMENT_ID;라고 작성해주었습니다.
그러면 그 많던 숫자들이

이렇게 하나로 포개어집니다.
이 그룹화된 컬럼을 정렬해 줄수도 있습니다. 이 때 하단에 ORDER BY를 추가하면 됩니다.
SELECT DEPARTMENT_ID FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
ORDER BY DEPARTMENT_ID ASC;그러면 정렬된 결과가 나타납니다.

그룹 함수
기본 개념
그룹함수는 통계 기능을 위한 것으로 엑셀을 다뤄보았다면 익숙할 것입니다.
통계를 위한 대표적인 그룹함수의 종류와 각각의 의미는 다음과 같습니다.
| 그룹함수 | 의미 |
|---|---|
COUNT | 컬럼 개수 |
SUM | 더하기 |
AVG | 평균 |
MAX | 최대값 |
MIN | 최소값 |
사실 그룹함수의 종류는 매우 많아서 우리가 다 외울 수 없습니다. 상황에 따라 필요한 함수가 궁금하다면 검색을 통해 유동적으로 사용하는 것이 바람직합니다.
사용하기
EMPLOYEES 테이블에서 컬럼의 개수(인원수), 급여의 합, 평균, 최대값, 최소값을 보여주려면 어떻게 할까요?
SELECT COUNT(*),
SUM(SALARY),
AVG(SALARY),
MAX(SALARY),
MIN(SALARY)
FROM EMPLOYEES;함수이기 때문에 인자를 받아서 처리해 줄 수 있습니다.
결과는 다음과 같이 출력됩니다.

그러면 각각을 그룹화까지 해보겠습니다.
그룹화를 할 때 중요한 것은 공통된 사항끼리 묶어야 한다는 것입니다. 우리가 기준으로 잡은 급여에 관해서는 공통점이 적거나 없을 수 있으므로 JOB_ID를 기준으로 잡아보겠습니다.
SELECT JOB_ID,
COUNT(*),
SUM(SALARY),
AVG(SALARY),
MAX(SALARY),
MIN(SALARY)
FROM EMPLOYEES
GROUP BY JOB_ID;하단에 GROUP BY JOB_ID를 작성해주었고 이는 JOB_ID를 기준으로 그룹화 하겠다는 뜻입니다.
결과는 다음과 같이 나옵니다.
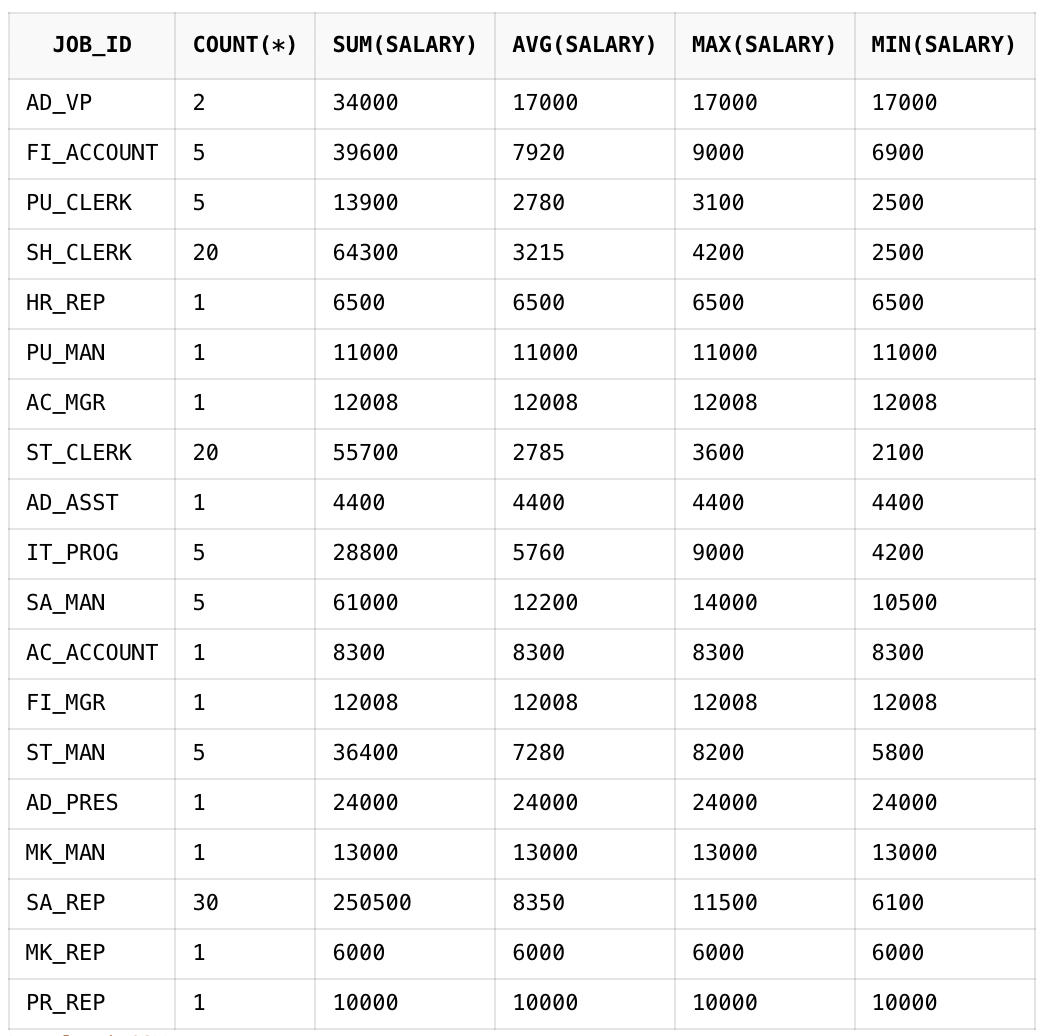
이 때 COUNT는 각각의 JOB_ID를 공유하는 사람의 수입니다.
오늘 준비한 내용은 여기까지입니다. 연습문제를 통해 더 자세하게 복습해 보시기 바랍니다.
연습 문제
문제1
문제1) EMPLOYEES 테이블에서 급여가 3000이상인 사원의 사원번호, 이름, 담당업무, 급여를 출력하라.
문제2) EMPLOYEES 테이블에서 담당 업무가 ST_MAN인 사원의 사원번호, 성명, 담당업무, 급여, 부서번호를 출력하라.
문제3) EMPLOYEES 테이블에서 입사일자가 2006년 1월 1일 이후에 입사한 사원의 사원번호, 성명, 담당업무, 급여, 입사일자, 부서번호를 출력하라.
문제4) EMPLOYEES 테이블에서 급여가 3000에서 5000사이의 사원의 성명, 담당업무, 급여, 부서번호를 출력하라.
문제5) EMPLOYEES 테이블에서 사원번호가 145,152,203인 사원의 정보를 사원번호, 성명, 담당업무, 급여, 입사일자를 출력하라
문제6) EMPLOYEES 테이블에서 입사일자가 05년도에 입사한 사원의 정보를 사원번호, 성명, 담당업무, 급여, 입사일자, 부서번호를 출력하라.
문제7) EMPLOYEES 테이블에서 보너스가 없는 사원의 사원번호, 성명, 담당업무, 급여, 입사일자, 보너스, 부서번호를 출력하라.
문제8) EMPLOYEES 테이블에서 급여가 1100이상이고 JOB이 ST_MAN인 사원의 사원번호, 성명, 담당업무, 급여, 입사일자, 부서번호를 출력하라.
문제9) EMPLOYEES 테이블에서 급여가 10000이상이거나 JOB이 ST_MAN인 사원의 사원번호, 성명, 담당업무, 급여, 입사일자, 부서번호를 출력하라.
문제10) EMPLOYEES 테이블에서 JOB이 ST_MAN, SA_MAN, SA_REP가 아닌 사원의 사원번호, 성명, 담당업무, 급여, 부서번호를 출력하라.
문제11) 업무가 PRES이고 급여가 12000이상이거나 업무가 SA_MAN인 사원의 사원번호, 이름, 업무, 급여를 출력하라.
문제12) 업무가 AD_PRES 또는 SA_MAN이고 급여가 12000이상인 사원의 사원번호, 이름, 업무, 급여를 출력하라.
풀이 예시
-- 문제1) EMPLOYEES 테이블에서 급여가 3000이상인 사원의 사원번호, 이름, 담당업무, 급여를 출력하라.
SELECT EMPLOYEE_ID, FIRST_NAME, JOB_ID, SALARY FROM EMPLOYEES
WHERE SALARY >= 3000;
-- 문제2) EMPLOYEES 테이블에서 담당 업무가 ST_MAN인 사원의 사원번호, 성명, 담당업무, 급여, 부서번호를 출력하라.
SELECT EMPLOYEE_ID, FIRST_NAME, JOB_ID, SALARY, DEPARTMENT_ID FROM EMPLOYEES
WHERE JOB_ID = 'ST_MAN';
-- 문제3) EMPLOYEES 테이블에서 입사일자가 2006년 1월 1일 이후에 입사한 사원의 사원번호, 성명, 담당업무, 급여, 입사일자, 부서번호를 출력하라.
SELECT EMPLOYEE_ID, FIRST_NAME, JOB_ID, SALARY, HIRE_DATE, DEPARTMENT_ID FROM EMPLOYEES
WHERE HIRE_DATE > TO_DATE('2006-01-01', 'YYYY-MM-DD');
-- 문제4) EMPLOYEES 테이블에서 급여가 3000에서 5000사이의 사원의 성명, 담당업무, 급여, 부서번호를 출력하라.
SELECT FIRST_NAME, JOB_ID, SALARY, DEPARTMENT_ID FROM EMPLOYEES
WHERE SALARY BETWEEN 3000 AND 5000;
-- 문제5) EMPLOYEES 테이블에서 사원번호가 145,152,203인 사원의 정보를 사원번호, 성명, 담당업무, 급여, 입사일자를 출력하라
SELECT EMPLOYEE_ID, FIRST_NAME, JOB_ID, SALARY, HIRE_DATE FROM EMPLOYEES
-- WHERE EMPLOYEE_ID = ANY('145', '152', '203');
WHERE EMPLOYEE_ID IN(145, 152, 203);
-- 문제6) EMPLOYEES 테이블에서 입사일자가 05년도에 입사한 사원의 정보를 사원번호, 성명, 담당업무, 급여, 입사일자, 부서번호를 출력하라.
SELECT EMPLOYEE_ID, FIRST_NAME, JOB_ID, SALARY, HIRE_DATE, DEPARTMENT_ID FROM EMPLOYEES
WHERE HIRE_DATE LIKE ('05%');
-- 문제7) EMPLOYEES 테이블에서 보너스가 없는 사원의 사원번호, 성명, 담당업무, 급여, 입사일자, 보너스, 부서번호를 출력하라.
SELECT EMPLOYEE_ID, FIRST_NAME, JOB_ID, SALARY, HIRE_DATE, NVL(SALARY * COMMISSION_PCT, 0), DEPARTMENT_ID FROM EMPLOYEES
WHERE COMMISSION_PCT IS NULL;
-- 문제8) EMPLOYEES 테이블에서 급여가 1100이상이고 JOB이 ST_MAN인 사원의 사원번호, 성명, 담당업무, 급여, 입사일자, 부서번호를 출력하라
SELECT EMPLOYEE_ID, FIRST_NAME, JOB_ID, SALARY, HIRE_DATE, DEPARTMENT_ID FROM EMPLOYEES
WHERE SALARY >= 1100 AND JOB_ID='ST_MAN';
-- 문제9) EMPLOYEES 테이블에서 급여가 10000이상이거나 JOB이 ST_MAN인 사원의 사원번호, 성명, 담당업무, 급여, 입사일자, 부서번호를 출력하라.
SELECT EMPLOYEE_ID, FIRST_NAME, JOB_ID, SALARY, HIRE_DATE, DEPARTMENT_ID FROM EMPLOYEES
WHERE SALARY >= 10000 OR JOB_ID='ST_MAN';
-- 문제10) EMPLOYEES 테이블에서 JOB이 ST_MAN, SA_MAN, SA_REP가 아닌 사원의 사원번호, 성명, 담당업무, 급여, 부서번호를 출력하라
SELECT EMPLOYEE_ID, FIRST_NAME, JOB_ID, SALARY, DEPARTMENT_ID FROM EMPLOYEES
WHERE JOB_ID NOT IN ('ST_MAN', 'SA_,AM', 'SA_REF');
-- 문제11) 업무가 PRES이고 급여가 12000이상이거나 업무가 SA_MAN인 사원의 사원번호, 이름, 업무, 급여를 출력하라.
SELECT EMPLOYEE_ID, FIRST_NAME, JOB_ID, SALARY FROM EMPLOYEES
WHERE (JOB_ID LIKE '%PRES' AND SALARY > 12000) OR JOB_ID = 'SA_MAN';
-- 문제12) 업무가 AD_PRES 또는 SA_MAN이고 급여가 12000이상인 사원의 사원번호, 이름, 업무, 급여를 출력하라.
SELECT EMPLOYEE_ID, FIRST_NAME, JOB_ID, SALARY FROM EMPLOYEES
WHERE JOB_ID = 'AD_PRES' OR JOB_ID = 'SA_MAN' AND SALARY = 12000;문제 2
정렬
문제1) EMPLOYEES 테이블에서 입사일자 순으로 정렬하여 사원번호, 이름, 업무, 급여, 입사일자,부서번호를 출력하라.
문제2) EMPLOYEES 테이블에서 가장 최근에 입사한 순으로 사원번호, 이름, 업무, 급여, 입사일자,부서번호를 출력하라.
문제3) EMPLOYEES 테이블에서 부서번호로 정렬한 후 부서번호가 같을 경우 급여가 많은 순으로 정렬하여 사원번호, 성명, 업무, 부서번호, 급여를 출력하여라.
문제4) EMPLOYEES 테이블에서 첫번째 정렬은 부서번호로 두번째 정렬은 업무로 세번째 정렬은 급여가 많은 순으로 정렬하여 사원번호, 성명, 입사일자, 부서번호, 업무, 급여를 출력하여라.
표준함수
문제1) EMPLOYEES 테이블에서 King의 정보를 대문자로 검색하고 사원번호, 성명, 담당업무를 대문자로 그리고 부서번호를 출력하라.
문제2) DEPARTMENTS 테이블에서 부서번호와 부서이름, 부서이름과 위치번호를 합하여 출력하도록 하라.
문제3) EMPLOYEES 테이블에서 이름 중 ‘e’자의 위치를 출력하라.
문제4) EMPLOYEES 테이블에서 부서번호가 80인 사람의 급여를 30으로 나눈 나머지를 구하여 출력하라.
문제5) EMPLOYEES 테이블에서 현재까지 근무일 수가 몇주 몇일 인가를 출력하여라. 단 근무 일수가 많은 사람 순으로 출력하여라.
문제6) EMPLOYEES 테이블에서 부서 50에서 급여 앞에 $를 삽입하고 3자리마다 ,를 출력하라.
그룹화
문제1) EMPLOYEES 테이블에서 모든 SALESMAN(SA_)에 대하여 급여의 평균, 최고액, 최저액, 합계를 구하여 출력하여라.
문제2) DEPARTMENTS 테이블에서 부서번호와 부서이름, 부서이름과 위치번호를 합하여 출력하도록 하라.
문제3) EMPLOYEES 테이블에서 부서별로 인원수, 평균 급여, 최저급여, 최고 급여, 급여의 합을 구하여 출력하라.
문제4) EMPLOYEES 테이블에서 각 부서별로 인원수,급여의 평균, 최저 급여, 최고 급여, 급여의 합을 구하여 급여의 합이 많은 순으로 출력하여라.
문제5) EMPLOYEES 테이블에서 부서별, 업무별 그룹하여 결과를 부서번호, 업무, 인원수, 급여의 평균, 급여의 합을 구하여 출력하여라.
문제6) EMPLOYEES 테이블에서 부서 인원이 4명보다 많은 부서의 부서번호, 인원수, 급여의 합을 구하여 출력하여라.
문제7) EMPLOYEES 테이블에서 급여가 최대 10000이상인 부서에 대해서 부서번호, 평균 급여, 급여의 합을 구하여 출력하여라.
문제8) EMPLOYEES 테이블에서 업무별 급여의 평균이 10000 이상인 업무에 대해서 업무명,평균 급여, 급여의 합을 구하여 출력하라.
문제9) EMPLOYEES 테이블에서 전체 월급이 10000을 초과하는 각 업무에 대해서 업무와 월급여 합계를 출력하라. 단 판매원(SA)은 제외하고 월 급여 합계로 정렬(내림차순)하라.
풀이 예시
-- 문제1) EMPLOYEES 테이블에서 입사일자 순으로 정렬하여 사원번호, 이름, 업무, 급여, 입사일자,부서번호를 출력하라.
SELECT EMPLOYEE_ID,
FIRST_NAME,
JOB_ID,
SALARY,
HIRE_DATE,
DEPARTMENT_ID
FROM EMPLOYEES
ORDER BY HIRE_DATE ASC;
-- 문제2) EMPLOYEES 테이블에서 가장 최근에 입사한 순으로 사원번호, 이름, 업무, 급여, 입사일자,부서번호를 출력하라.
SELECT EMPLOYEE_ID, FIRST_NAME, JOB_ID, SALARY, HIRE_DATE, DEPARTMENT_ID FROM EMPLOYEES
ORDER BY HIRE_DATE DESC;
-- 문제3) EMPLOYEES 테이블에서 부서번호로 정렬한 후 부서번호가 같을 경우 급여가 많은 순으로 정렬하여 사원번호, 성명, 업무, 부서번호, 급여를 출력하여라.
SELECT EMPLOYEE_ID, FIRST_NAME, JOB_ID, DEPARTMENT_ID, SALARY FROM EMPLOYEES
ORDER BY DEPARTMENT_ID ASC, SALARY DESC;
-- 문제4) EMPLOYEES 테이블에서 첫번째 정렬은 부서번호로 두번째 정렬은 업무로 세번째 정렬은 급여가 많은 순으로 정렬하여 사원번호, 성명, 입사일자, 부서번호, 업무, 급여를 출력하여라.
SELECT EMPLOYEE_ID, FIRST_NAME, HIRE_DATE, DEPARTMENT_ID, JOB_ID, SALARY FROM EMPLOYEES
ORDER BY DEPARTMENT_ID ASC, JOB_ID ASC, SALARY DESC;
-- 표준함수
-- 문제1) EMPLOYEES 테이블에서 King의 정보를 대문자로 검색하고 사원번호, 성명, 담당업무를 대문자로 그리고 부서번호를 출력하라.
SELECT EMPLOYEE_ID, LAST_NAME, UPPER(JOB_ID), DEPARTMENT_ID FROM EMPLOYEES
WHERE UPPER(LAST_NAME) = 'KING';
-- 문제2) DEPARTMENTS 테이블에서 부서번호와 부서이름, 부서이름과 위치번호를 합하여 출력하도록 하라.
SELECT DEPARTMENT_ID, DEPARTMENT_NAME, DEPARTMENT_ID ||' '|| LOCATION_ID FROM DEPARTMENTS;
-- CONCAT
SELECT DEPARTMENT_ID, DEPARTMENT_NAME, CONCAT(DEPARTMENT_ID, LOCATION_ID) FROM DEPARTMENTS;
-- 문제3) EMPLOYEES 테이블에서 이름 중 ‘e’자의 위치를 출력하라.
SELECT FIRST_NAME, INSTR(FIRST_NAME, 'e') FROM EMPLOYEES
-- 문제4) EMPLOYEES 테이블에서 부서번호가 80인 사람의 급여를 30으로 나눈 나머지를 구하여 출력하라.
SELECT DEPARTMENT_ID, FIRST_NAME, SALARY, MOD(SALARY, 30) FROM EMPLOYEES
WHERE DEPARTMENT_ID = 80
-- 문제5) EMPLOYEES 테이블에서 현재까지 근무일 수가 몇주 몇일 인가를 출력하여라. 단 근무 일수가 많은 사람 순으로 출력하여라.
SELECT FIRST_NAME, HIRE_DATE,
ROUND(SYSDATE-HIRE_DATE) AS WORKINGDAY,
ROUND(ROUND(SYSDATE-HIRE_DATE) / 7) AS WORKINGWEEKS
FROM EMPLOYEES
ORDER BY WORKINGDAY DESC;
-- 문제6) EMPLOYEES 테이블에서 부서 50에서 급여 앞에 $를 삽입하고 3자리마다 ,를 출력하라
SELECT FIRST_NAME, SALARY, TO_CHAR(SALARY, '$999,999,999') FROM EMPLOYEES
WHERE DEPARTMENT_ID = 50;
-- 그룹핑
-- 문제1) EMPLOYEES 테이블에서 모든 SALESMAN(SA_)에 대하여 급여의 평균, 최고액, 최저액, 합계를 구하여 출력하여라.
SELECT AVG(SALARY), MAX(SALARY), MIN(SALARY), SUM(SALARY) FROM EMPLOYEES
WHERE JOB_ID LIKE 'SA_%';
-- 문제2) EMPLOYEES 테이블에 등록되어 있는 인원수,
-- 보너스가 NULL이 아닌 인원수, 보너스의 평균, 등록되어 있는 부서의 수를 구하여 출력하라.
SELECT COUNT(*),
COUNT(COMMISSION_PCT), -- null은 count하지 않음
ROUND(AVG(COMMISSION_PCT*SALARY)),
COUNT(DISTINCT DEPARTMENT_ID)
FROM EMPLOYEES;
-- 문제3) EMPLOYEES 테이블에서 부서별로 인원수, 평균 급여, 최저급여, 최고 급여, 급여의 합을 구하여 출력하라.
SELECT COUNT(*),
ROUND(AVG(SALARY)),
MIN(SALARY),
MAX(SALARY),
SUM(SALARY)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID;
-- 문제4) EMPLOYEES 테이블에서 각 부서별로 인원수,급여의 평균, 최저 급여, 최고 급여, 급여의 합을 구하여 급여의 합이 많은 순으로 출력하여라.
SELECT DEPARTMENT_ID,
COUNT(*),
ROUND(AVG(SALARY)),
MIN(SALARY),
MAX(SALARY),
SUM(SALARY) AS TOTALOFSAL
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
ORDER BY TOTALOFSAL DESC;
-- 문제5) EMPLOYEES 테이블에서 부서별, 업무별 그룹하여 결과를 부서번호, 업무,
-- 인원수, 급여의 평균, 급여의 합을 구하여 출력하여라.
SELECT DEPARTMENT_ID,
JOB_ID,
COUNT(*),
ROUND(AVG(SALARY)),
SUM(SALARY)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID, JOB_ID;
-- 문제6) EMPLOYEES 테이블에서 부서 인원이 4명보다 많은 부서의 부서번호, 인원수, 급여의 합을 구하여 출력하여라
SELECT DEPARTMENT_ID,
COUNT(*),
SUM(SALARY)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
HAVING COUNT(*) > 4;
-- 문제7) EMPLOYEES 테이블에서 급여가 최대 10000이상인 부서에 대해서 부서번호, 평균 급여, 급여의 합을 구하여 출력하여라.
SELECT DEPARTMENT_ID,
ROUND(AVG(SALARY)),
SUM(SALARY)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
HAVING MAX(SALARY) >= 10000;
-- 문제8) EMPLOYEES 테이블에서 업무별 급여의 평균이 10000 이상인 업무에 대해서 업무명,평균 급여, 급여의 합을 구하여 출력하라.
SELECT JOB_ID,
ROUND(AVG(SALARY)),
SUM(SALARY)
FROM EMPLOYEES
GROUP BY JOB_ID
HAVING ROUND(AVG(SALARY)) >= 10000;
-- 문제9) EMPLOYEES 테이블에서 전체 월급이 10000을 초과하는 각 업무에 대해서 업무와 월급여 합계를 출력하라.
-- 단 판매원(SA)은 제외하고 월 급여 합계로 정렬(내림차순)하라.
SELECT JOB_ID,
SUM(SALARY) AS TS
FROM EMPLOYEES
WHERE JOB_ID NOT LIKE 'SA%'
group by JOB_ID
HAVING SUM(SALARY) > 10000
ORDER BY TS DESC;참고문헌
Rudy_님의 블로그 - Art Rudy (https://artrudy.tistory.com/13?category=948553)
2021년 12월 22일 접속
